Latest Blog Posts
Transparent Column Encryption in PostgreSQL: Security Without Changing Your SQL
Posted by Vibhor Kumar on 2026-03-12 at 15:19

There is a moment in many database reviews when the room becomes a little too quiet.
Someone asks:
“Which columns in this database are encrypted?”
At first, the answers sound reassuring.
“We use TLS.”
“The disks are encrypted.”
“The application handles sensitive fields.”
And then the real picture starts to emerge.
Some values are encrypted in one service but not another.
Some migrations remembered to apply encryption.
Some scripts did not.
Some backups are safe in theory, but no one wants to test that theory the hard way.
That is the uncomfortable truth of database security:
encryption is often present, but not always enforced where the data actually lives.
That is exactly the problem I wanted to explore with the PostgreSQL extension:
column_encrypt: https://github.com/vibhorkum/column_encrypt
This extension provides transparent column-level encryption using custom PostgreSQL datatypes so developers can read and write encrypted columns without changing their SQL queries.
And perhaps the most human part of this project is this:
the idea for this project started back in 2016.
It stayed with me for years as one of those engineering ideas that never quite leaves your mind — the thought that PostgreSQL itself could enforce encryption at the column level.
Now I’ve finally decided to release it.
This is the first public version. It’s a starting point — useful, practical, and hopefully something the PostgreSQL community can explore and build upon.
Why This Matters
Encryption conversations often focus first on infrastructure.
- We encrypt disks.
- We use TLS connections.
- We protect credentials.
All of these are important.
But once data is inside the database, a different question matters:
What happens if someone gains access to the database itself?
That access might come from:
- a leaked backup
- an overprivileged account
- a dump file
- a compromised service
- an operational mista
Debugging RDS Proxy Pinning: How a Hidden JIT Toggle Created Thousands of Pinned Connections
Posted by Richard Yen on 2026-03-12 at 08:00
Introduction
When using AWS RDS Proxy, the goal is to achieve connection multiplexing – many client connections share a much smaller pool of backend PostgreSQL connections, givng more resources per connection and keeping query execution running smoothly.
However, if the proxy detects that a session has changed internal state in a way it cannot safely track, it pins the client connection to a specific backend connection. Once pinned, that connection can never be multiplexed again. This was the case with a recent database I worked on.
In this case, we observed the following:
- extremely high CPU usage
- relatively high LWLock wait times
- OOM killer activity on the database, maybe once every day or two
- thousands of active connections
What was strange about it all was that the queries involved were relatively simple, with max just one join.
Finding the Pinning Source
To get to the root cause, one option was to look in pg_stat_statements. However, that approach had two problems:
- Getting a clean snapshot of the statistics while thousands of queries were being actively processed would be tricky.
-
pg_stat_statementsnormalizes queries and does not expose the values passed to parameter placeholders.
Instead, to see the actual parameters, we briefly enabled log_statement = 'all'. This immediately surfaced something interesting in the logs, which could be downloaded and reviewed on my own time and pace.
What we saw were statements like SELECT set_config($2,$1,$3) with parameters related to JIT configuration – that was the first real clue.
Getting to the Bottom
After tracing the behavior through the stack, the root cause turned out to be surprisingly indirect. The application created new connections through SQLAlchemy’s asyncpg dialect, and we needed to drill down into that driver’s behavior.
Step 1 – Reviewing how SQLAlchemy registers JSON codecs
During connection initialization, SQLAlchemy runs an on_connect hook:
def connect(conn):
SCaLE23x
Posted by gabrielle roth on 2026-03-12 at 00:38
The MySQL Shadow
Posted by Bruce Momjian in EDB on 2026-03-11 at 14:15
For much of Postgres's history, it has lived in the shadow of other relational systems, and for a time even in the shadow of NoSQL systems. Those shadows have faded, but it is helpful to reflect on this outcome.
On the proprietary side, most database products are now in maintenance mode. The only database to be consistently compared to Postgres was Oracle. Long-term, Oracle was never going to be able to compete against an open source development team, just like Sun's Solaris wasn't able to compete against open source Linux. Few people would choose Oracle's database today, so it is effectively in legacy mode. The Oracle shadow is clearly fading. In fact, almost all enterprise infrastructure software is open source today.
The MySQL shadow is more complex. MySQL is not proprietary, since it is distributed as open source, so it had the potential to ride the open source wave into the enterprise, and it clearly did from the mid-1990s to the mid-2000s. However, something changed, and MySQL has been in steady decline for decades. Looking back, people want to ascribe a reason for the decline:
- Sun buying MySQL AB
- Oracle buying Sun
- Poor stewardship of MySQL by Oracle, including recent layoffs
Beyond Features: What a PostgreSQL Strategy Discussion Taught Me About Calm, Modern Platforms
Posted by Vibhor Kumar on 2026-03-11 at 13:36

Last December, I was part of a long enterprise discussion centered on PostgreSQL.
On paper, it looked familiar: a new major release, high availability and scale, Aurora migration, monitoring, operational tooling, and the growing conversation around AI-assisted operations.
The usual ingredients were all there.
But somewhere in the middle of that day, the tone of the room changed.
It did not change when we talked about new PostgreSQL capabilities. It changed when the conversation moved to upgrades, patching, monitoring quality, and operational control.
That was the moment I realized this was not really a feature discussion.
It was a trust discussion.
Not trust in PostgreSQL as a database. That question is mostly behind us.
It was trust in something more practical: can this platform evolve without exhausting the team responsible for it? Can it scale without becoming harder to reason about? Can it be upgraded without becoming a quarterly trauma ritual? Can it be monitored without operators drowning in false signals? Can it support modernization without making every change feel dangerous?
That, to me, is where the PostgreSQL conversation has matured.
A modern PostgreSQL platform is not defined only by what it can do. It is defined by how calmly it can change.
Why this matters now
This matters because PostgreSQL is no longer entering the enterprise through side doors. In many organizations, it is already trusted with serious workloads and is increasingly central to modernization plans.
That changes the questions.
A few years ago, teams often asked whether PostgreSQL was ready for enterprise use. Today, the better question is whether the operating model around PostgreSQL is ready for enterprise reality.
Because the database can be strong while the surrounding practice is weak.
That is where many teams struggle. They like PostgreSQL, but lag on upgrades. They have HA designs, but unclear failure playbooks. They have monitoring, but poor signal qualit
[...]The Future of Postgres on the agenda: EDB’s PGConf.dev Preview
Posted by Floor Drees in EDB on 2026-03-11 at 12:29
The Dilemma of the ‘AI DBA’
Posted by Lukas Fittl on 2026-03-11 at 00:00
work_mem: it's a trap!
Posted by Lætitia AVROT on 2026-03-11 at 00:00
The Part of PostgreSQL We Discuss the Most — 2
Posted by Virender Singla on 2026-03-10 at 17:27
PostgreSQL and Oracle Implementation
In the Part 1, we explored the general concepts of MVCC and the implications of storing data snapshots either out-of-place or within heap storage, we can now map these methodologies to specific database engines.
The PostgreSQL MVCC implementation aligns with the DatabaseI model, whereas Oracle and MySQL are closely related to the DatabaseO model. Specifically, Oracle utilizes block versioning and stores older versions in a separate storage area known as UNDO, while PostgreSQL employs row versioning.
These engines further optimize their respective in-place or out-of-place MVCC strategies:
- Oracle (DatabaseO) Delta Storage: To improve efficiency, Oracle avoids copying an entire block to UNDO. Instead, it only stores the modified columns as a “delta.” Consequently, when a query requires an older image, the engine applies this delta to the current heap block to reconstruct the previous state.
- PostgreSQL (DatabaseI) Visibility Map (VM): To mitigate the overhead of scanning the entire heap for garbage collection, PostgreSQL uses a Visibility Map. This data structure maintains per-block information of heap, allowing the garbage collector to identify specific blocks containing garbage instead of performing a full table scan.
- Heap Only Tuple (HOT) Optimization: PostgreSQL addresses continuous index churn caused by new physical address (ctid) through HOT optimization. If a new row version fits within the same block as the previous version, the indexes are not updated. Instead, index access lands on the heap block, accessing the old version, which then chains directly to the new version within the same block. Note that it’s still a single block fetch.
- Row Locking Mechanism: PostgreSQL utilizes the visibility counters to manage row locking as well, whereas Oracle employs a distinct data structure located in the block header for this purpose.
- Handling Multiple Data Versions: When a row undergoes multiple updates, Oracle maintai
The Part of PostgreSQL We Discuss the Most — 1
Posted by Virender Singla on 2026-03-10 at 17:26
Early in my PostgreSQL journey, I often sensed that a conversation between two Postgres professionals inevitably revolves around vacuuming. That lighthearted observation still remains relevant, as my LinkedIn feeds are often filled with discussions around vacuuming and comparing PostgreSQL’s Multi-Version Concurrency Control (MVCC) implementation to other engines like Oracle or MySQL. Given that people are naturally drawn to the most complex components of a system, I will continue this journey by exploring a detailed comparison of these database architectures focused on the MVCC implementations.
What is MVCC?
Stone age databases relied on strict locking mechanisms to handle concurrency, which proved inefficient under heavy load. In these traditional models, a read operation required a shared lock that prevented other transactions from updating the record. Conversely, write operations required exclusive locks that blocked incoming reads. This resulted in significant lock contention, where readers blocked writers and writers blocked readers.
To solve this, RDBMS implemented MVCC. The idea was very simple. Rather than overwriting data immediately, maintain multiple versions of data simultaneously. This allows transactions to view a consistent snapshot of the database as it existed at a specific point in time. For instance, if User 1 starts reading a table just before User 2 starts modifying a record, User 1 sees the original version of the data without hindering User 2’s progress. Without MVCC, the system would be forced to either serialize all access — making User 2 wait — or risk data consistency anomalies like dirty or non-repeatable reads where User 1 sees uncommitted changes that might eventually be rolled back.
Database engines utilize various architectures to manage this data versioning. A particularly notable point of discussion is the comparison between “in-place” and “out-of-place” data versioning techniques. Let’s examine these approaches more closely.
Explaining In-Place and Out-of
[...]Shaping SQL in São Paulo
Posted by Floor Drees in EDB on 2026-03-10 at 13:37
Validating the shape of your JSON data
Posted by Andrew Dunstan in EDB on 2026-03-10 at 10:13
One of the great things about PostgreSQL's jsonb type is the flexibility it gives you — you can store whatever structure you need without defining columns up front. But that flexibility comes with a trade-off: there's nothing stopping bad data from getting in. You can slap a CHECK constraint on a jsonb column, but writing validation logic in SQL or PL/pgSQL for anything beyond the trivial gets ugly fast.
I've been working on a PostgreSQL extension called json_schema_validate that solves this problem by letting you validate JSON and JSONB data against JSON Schema specifications directly in the
AI Features in pgAdmin: The AI Chat Agent
Posted by Dave Page in pgEdge on 2026-03-10 at 05:44
This is the second in a series of three blog posts covering the new AI functionality in pgAdmin 4. In the first post, I covered LLM configuration and the AI-powered analysis reports. In this post, I'll introduce the AI Chat agent in the query tool, and in the third, I'll explore the AI Insights feature for EXPLAIN plan analysis.If you've ever found yourself staring at a database schema you didn't design, trying to work out the right joins to answer a seemingly simple question, you'll appreciate what the AI Chat agent brings to pgAdmin's query tool. Rather than having to alt-tab to an external AI service, paste in your schema, describe what you need, and then copy the resulting SQL back into your editor, the entire conversation now happens within the query tool itself, with full awareness of your actual database structure.
Finding the AI Assistant
The AI Chat agent appears as a new tab alongside the Query and Query History tabs in the left panel of the query tool. It's labelled 'AI Assistant' and is only visible when an LLM provider has been configured (as described in the first post in this series). The panel header shows which LLM provider and model are currently active, so you always know what's generating your responses.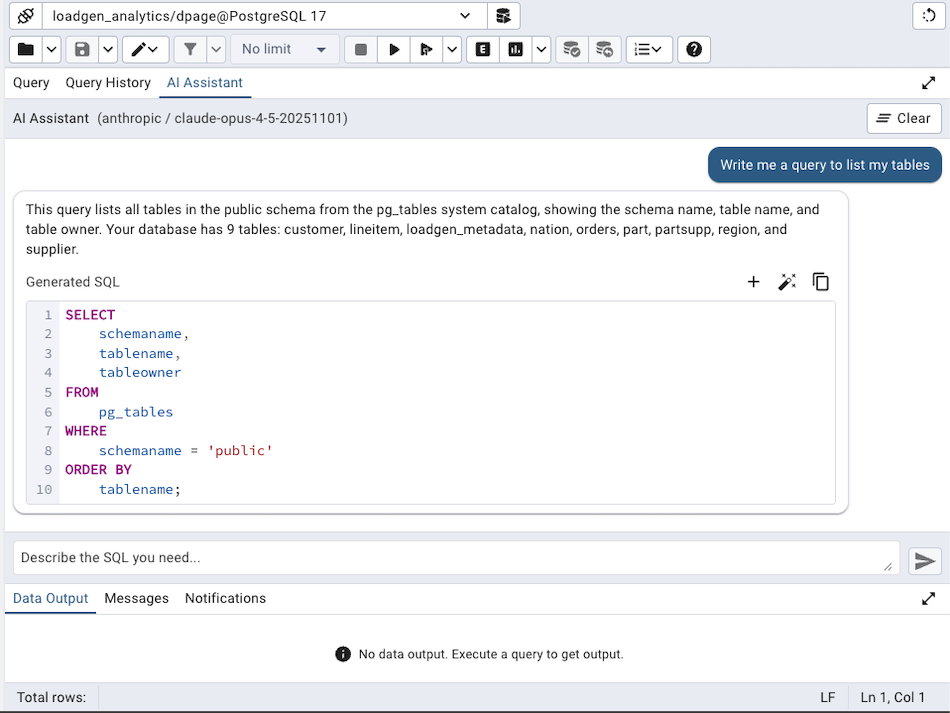
Natural Language to SQL
The core capability of the AI Chat agent is translating natural language questions into SQL queries. You type what you want to know in plain English (or whatever language you're comfortable with), and the assistant generates the corresponding SQL, complete with an explanation of what it does and why it was written that way.For example, you might type something like:The assistant will first inspect your database schema to understand the available tables and relationships, then generate an appropriate query. The response includes both the SQL and a brief explanation, so you can understand what the query is doing before you run it.What makes this particularly useful is that the assistant doesn't just guess at your schema; it actively inspects the database using a[...]Introducing pg_duckpipe: Real-Time CDC for Your Lakehouse
Posted by Yuwei Xiao on 2026-03-10 at 00:00
Thinking of PostgreSQL High Availability as Layers
Posted by Umair Shahid in Stormatics on 2026-03-09 at 14:03
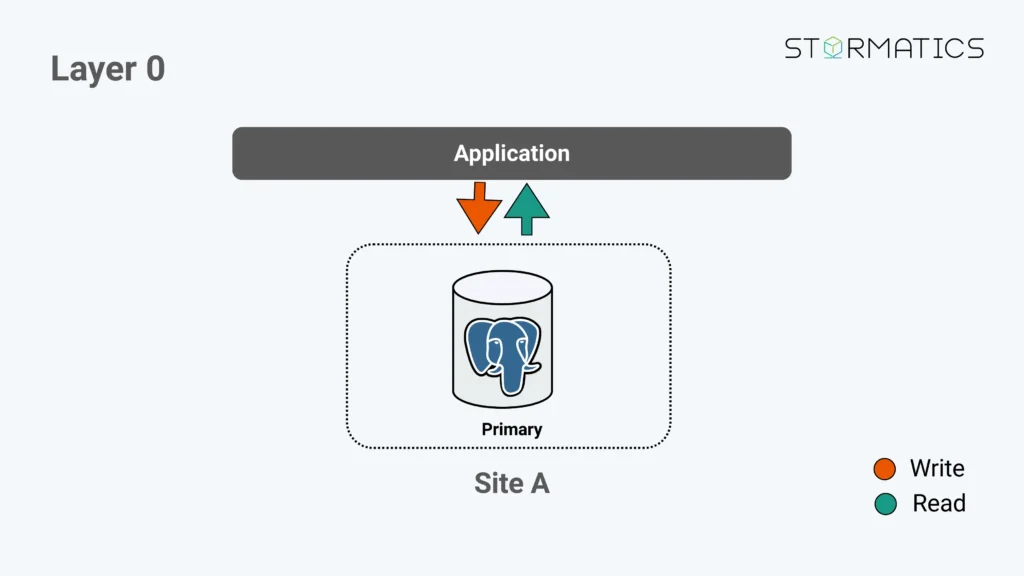
Contributions for week 9, 2026
Posted by Cornelia Biacsics in postgres-contrib.org on 2026-03-09 at 10:31
The community met on Wednesday, March 4, 2026 for the 7. PostgreSQL User Group NRW MeetUp (Cologne, ORDIX AG). It was organised by Dirk Krautschick and Andreas Baier.
Speakers:
- Robin Riel
- Jan Karremans
PostgreSQL Berlin March 2026 Meetup took place on March 5, 2026 organized by Andreas Scherbaum and Sergey Dudoladov.
Speakers:
- Andreas Scherbaum
- Tudor Golubenco
- Narendra Tawar
- Kai Wagner
Kai Wagner wrote about his experience at the meetup PostgreSQL Berlin Meetup - March 2026
Andreas Scherbaum wrote a blog posting about the Meetup.
SCALE 23x (March 5-8, 2026) had a dedicated PostgreSQL track, filled by the following contributions
Trainings:
- Elizabeth Christensen
- Devrim Gunduz
- Ryan Booz
Talks:
- Nick Meyer
- Tristan Ahmadi
- Alexandra Wang
- Christophe Pettus
- Max Englander
- Magnus Hagander
- Bruce Momjian
- Robert Treat
- Payal Singh
- German Eichberger
- Jimmy Angelakos
- Justin Frye
SCALE 23x PostgreSQL Booth volunteers:
- Bruce Momjian
- Christine Momjian
- Gabrielle Roth
- Jennifer Scheuerell
- Magnus Hagander
- Devrim Gunduz
- Elizabeth Garret Christensen
- Robert Treat
- Pavlo Golub
- Phill Vacca
- Jimmy Angelakos
- Erika Miller
- Aya Griswold
- Alex Wood
- Donald Wong
- Derya Gumustel
AI Features in pgAdmin: Configuration and Reports
Posted by Dave Page in pgEdge on 2026-03-09 at 05:31
This is the first in a series of three blog posts covering the new AI functionality coming in pgAdmin 4. In this post, I'll walk through how to configure the LLM integration and introduce the AI-powered analysis reports; in the second, I'll cover the AI Chat agent in the query tool; and in the third, I'll explore the AI Insights feature for EXPLAIN plan analysis.Anyone who manages PostgreSQL databases in a professional capacity knows that keeping on top of security, performance, and schema design is an ongoing endeavour. You might have a checklist of things to review, or perhaps you rely on experience and intuition to spot potential issues, but it is all too easy for something to slip through the cracks, especially as databases grow in complexity. We've been thinking about how AI could help with this, and I'm pleased to introduce a suite of AI-powered features in pgAdmin 4 that bring large language model analysis directly into the tool you already use every day.
Configuring the LLM Integration
Before any of the AI features can be used, you'll need to configure an LLM provider. pgAdmin supports four providers out of the box, giving you flexibility to choose between cloud-hosted models and locally-running alternatives:- Anthropic
- (Claude models)
- OpenAI
- (GPT models)
- Ollama
- (locally-hosted open-source models)
- Docker Model Runner
- (built into Docker Desktop 4.40 and later)
Server Configuration
At the server level, there is a master switch in (or, more typically, ) that controls whether AI features are available at all:When is set to , all AI functionality is hidden from users and cannot be enabled through preferences. This gives administrators full control over whether AI features are permitted in their environment, which is particularly important in organisations with strict data governance policies.Below the master switch, you'll find default configuration for each provider:For the cloud providers (Anthropic and OpenAI), API keys are read from files on di[...]Production Query Plans Without Production Data
Posted by Radim Marek on 2026-03-08 at 21:15
In the previous article we covered how the PostgreSQL planner reads pg_class and pg_statistic to estimate row counts, choose join strategies, and decide whether an index scan is worth it. The message was clear: when statistics are wrong, everything else goes with it.
PostgreSQL 18 changed that. Two new functions: pg_restore_relation_stats and pg_restore_attribute_stats write numbers directly into the catalog tables. Combined with pg_dump --statistics-only, you can treat optimizer statistics as a deployable artifact. Compact, portable, plain SQL.
The feature was driven by the upgrade use case. In the past, major version upgrades used to leave pg_statistic empty, forcing you to run ANALYZE. Which might take hours on large clusters. With PostgreSQL 18 upgrades now transfer statistics automatically. But that's just the beginning. The same logic lets you export statistics from production and inject them anywhere - test database, local debugging, or as part of CI pipelines.
The problem
Your CI database has 1,000 rows. Production has 50 million. The planner makes completely different decisions for each. Running EXPLAIN in CI tells you nothing about the production plan. This is the core premise behind RegreSQL. Catching query plan regressions in CI is far more reliable when the planner sees production-scale statistics.
Same applies to debugging. A query is slow in production and you want to reproduce the plan locally, but your database has different statistics, and planner chooses the predictable path. Porting production stats can provide you that snapshot of thinking planner has to do in production, without actually going to production.
pg_restore_relation_stats
The first of functi
[...]New Presentation
Posted by Bruce Momjian in EDB on 2026-03-07 at 18:45
I just gave a new presentation at SCALE titled The Wonderful World of WAL. I am excited to have a second new talk this year. (I have one more queued up.)
I have always wanted to do a presentation about the write-ahead log (WAL) but I was worried there was not enough content for a full talk. As more features were added to Postgres that relied on the WAL, the talk became more feasible, and at 103 slides, maybe I waited too long. 
I had a full hour to give the talk at SCALE, and that was helpful. I was able to answer many questions during the talk, and that was important — many of the later features rely on earlier ones, e.g., point-in-time recovery (PITR) relies heavily on crash recovery, and if you don't understand how crash recovery works, you can't understand PITR. By taking questions at the end of each section, I could be sure everyone understood. The questions showed that the audience of 46 understood the concepts because they were asking about the same issues we dealt with in designing the features:
- How does server start know if crash recovery is needed?
- Can dirty shared buffers be written to storage before the WAL for the transaction that dirtied them is written?
- Can the WAL and heap/index storage get out of sync?
- How is the needed WAL accurately retained for replica servers?
- Can logical replicas be used as failover servers?
From proposal to PR: how to contribute to the new CloudNativePG extensions project
Posted by Gabriele Bartolini in EDB on 2026-03-07 at 06:36
In this article I walk you through the journey of adding the pg_crash extension to the new CloudNativePG extensions project. It explores the transition from legacy standalone repositories to a unified, Dagger-powered build system designed for PostgreSQL 18 and beyond. By focusing on the Image Volume feature and minimal operand images, the post provides a step-by-step guide for community members to contribute and maintain their own extensions within the CloudNativePG ecosystem.
Using Patroni to Build a Highly Available Postgres Cluster—Part 1: etcd
Posted by Shaun Thomas in pgEdge on 2026-03-06 at 07:48
The last PG Phriday article focused on the architecture of a Patroni cluster—the how and why of the design. This time around, it’s all about actually building one. I’ve often heard that operating Postgres can be intimidating, and Patroni is on a level above that. Well, I won’t argue on the second count, but I can try to at least ease some of the pain.To avoid an overwhelming deluge consisting of twenty pages of instructions, I’ve split this article into a series of three along these lines:
- Etcd
- Postgres and Patroni
- HAProxy
Why etcd?
The last article should have made it abundantly clear that the DCS is the nexus of communication and status for the whole cluster. As a result, it’s important to install it first and certify that it’s operational. Etcd is the default and the example most often deployed in Patroni clusters. It’s also the key/value storage system Kubernetes uses as a default, so it should be reliable enough for our needs.Don’t forget to keep a browser tab opened to the etcd documentation handy.What you’ll need
If you want to follow along with this demonstration, you’ll need:- The ability to create three VMs. Whether it’s
- Amazon EC2
- instances,
- Microsoft Hyper-V
- ,
- Xen
- ,
- QEMU
- ,
- Proxmox
- ,
- Oracle VirtualBox
- , or even
- VMWare Fusion
- , make sure you have a hypervisor and know how to use it.
- Three VMs running
- Debian Stable
- version 13. At the time of writing, this should be the Trixie release.
- SSH access as a root-capable user on each VM.
- An internet connection. If you have the first three, it’s likely you have this as well.
PostgreSQL Berlin March 2026 Meetup
Posted by Andreas Scherbaum on 2026-03-05 at 22:00
Inside the Kernel: The Complete Path to PostgreSQL Delete Recovery — From FPW to Data Resurrection
Posted by Zhang Chen on 2026-03-05 at 00:00
Expert-Level PostgreSQL Deleted Data Recovery in Just 5 Steps — No Kernel Knowledge Required
Posted by Zhang Chen on 2026-03-05 at 00:00
pg_plan_advice: Plan Stability and User Planner Control for PostgreSQL?
Posted by Robert Haas in EDB on 2026-03-04 at 17:55
I'm proposing a very ambitious patch set for PostgreSQL 19. Only time will tell whether it ends up in the release, but I can't resist using this space to give you a short demonstration of what it can do. The patch set introduces three new contrib modules, currently called pg_plan_advice, pg_collect_advice, and pg_stash_advice.
Read more »pg_plan_alternatives: Tracing PostgreSQL’s Query Plan Alternatives using eBPF
Posted by Jan Kristof Nidzwetzki on 2026-03-04 at 00:00
PostgreSQL uses a cost-based optimizer (CBO) to determine the best execution plan for a given query. The optimizer considers multiple alternative plans during the planning phase. Using the EXPLAIN command, a user can only inspect the chosen plan, but not the alternatives that were considered. To address this gap, I developed pg_plan_alternatives, a tool that uses eBPF to instrument the PostgreSQL optimizer and trace all alternative plans and their costs that were considered during the planning phase. This information helps the user understand the optimizer’s decision-making process and tune system parameters. This article explains how pg_plan_alternatives works, provides examples, and discusses the insights the tool can provide.
Cost-Based Optimization
SQL is a declarative language, which means that users only specify what they want to achieve, but not how to achieve it. For example, should the query SELECT * FROM mytable WHERE age > 50; perform a full table scan and apply a filter, or should it use an index (see the following blog post for more details about this)? The optimizer of the database management system is responsible for determining the best execution plan to execute a given query. During query planning, the optimizer generates multiple alternative plans. Many DBMSs perform cost-based optimization, where each plan is qualified with a cost estimate, a numerical value representing the estimated resource usage (e.g., CPU time, I/O operations) required to execute the plan. The optimizer then selects the plan with the lowest estimated cost as the final execution plan for the query.
To calculate the costs of the plan nodes, the optimizer uses a cost model that accounts for factors such as the number of rows predicted to be processed (based on statistics and selectivity estimates) and constants.
Query Plans in PostgreSQL
Using the EXPLAIN command in PostgreSQL, you can see the final chosen plan and its estimated total cost, and the costs of the individual plan nodes. For example, using
Mostly Dead is Slightly Alive: Killing Zombie Sessions
Posted by Lætitia AVROT on 2026-03-04 at 00:00
pg_semantic_cache in Production: Tags, Eviction, Monitoring, and Python Integration
Posted by Muhammad Aqeel in pgEdge on 2026-03-03 at 04:20
Part 2 of the Semantic Caching in PostgreSQL series that’ll take you from a working demo to a production-ready system.
From Demo to Production
In Part 1, we set up pg_semantic_cache in a Docker container and demonstrated how semantic similarity matching works. In summary, semantic caching associates a string with each query that allows us to search the cache by meaning instead of by the exact query text. We demonstrated a cache hit at 99.9% similarity and a cache miss at 68% (configurable defaults), and discussed why this can make a difference for LLM-powered applications.Now let's make it production-ready. A cache that can store and retrieve is useful, but a cache you can organize, monitor, evict, and integrate into your application is what you actually need for a production deployment. In this post, we'll cover all of that.We'll continue using the same Docker environment from Part 1. If you need to set it up again, refer to the Dockerfile and setup instructions in that post.Organizing with Tags
Tags let you group and manage cache entries by category; the at the end of the cache entry contains the tags associated with a specific query. For example, tags in our first query:Identify the query as being associated with and .In our second query, the tags identify the query as being associated with and :We can view the tags with the following statement:When the underlying data changes in our backing database, we can then use the tags to Invalidate old content in our data set:Eviction Strategies
Caches need boundaries. You can use those boundaries to keep data sets fresh:pg_semantic_cache provides eviction strategies you can use to set those boundaries for your cache:For easy maintenance in a production environment, you can schedule automatic cache clean up with pg_cron:Monitoring
The extension provides built-in views for observability. The semantic_cache.cache_health view provides an overview of the number of entries and use of a given cache:The semantic_cache.recent_cache_activity view provide[...]INSERT ... ON CONFLICT ... DO SELECT: a new feature in PostgreSQL v19
Posted by Laurenz Albe in Cybertec on 2026-03-03 at 04:00

© Laurenz Albe 2026
PostgreSQL has supported the (non-standard) ON CONFLICT clause for the INSERT statement since version 9.5. In v19, commit 88327092ff added ON CONFLICT ... DO SELECT. A good opportunity to review the benefits of ON CONFLICT and to see how the new variant DO SELECT can be useful!
What is INSERT ... ON CONFLICT?
INSERT ... ON CONFLICT is the PostgreSQL implementation of something known as “upsert”: you want to insert data into a table, but if there is already a conflicting row in the table, you want to either leave the existing row alone or update update it instead. You can achieve the former by using “ON CONFLICT DO NOTHING”. To update the conflicting row, you use “ON CONFLICT ... DO UPDATE SET ...”. Note that with the latter syntax, you must specify a “conflict target”: either a constraint or a unique index, against which PostgreSQL tests the conflict.
You may wonder why PostgreSQL has special syntax for this upsert. After all, the SQL standard has a MERGE statement that seems to cover the same functionality. True, PostgreSQL didn't support MERGE until v15, but that's hardly enough reason to introduce new, non-standard syntax. The real reason is that “INSERT ... ON CONFLICT”, different from “MERGE”, does not have a race condition: even with concurrent data modification going on, “INSERT ... ON CONFLICT ... DO UPDATE” guarantees that either an INSERT or an UPDATE will happen. There cannot be a failure because — say — a concurrent transaction deleted a conflicting row between our attempt to insert and to update that row.
An example that shows the race condition with MATCH
Create a table as follows:
CREATE TABLE tab (key integer PRIMARY KEY, value integer);
Then start a transaction and insert a row:
BEGIN; INSERT INTO tab VALUES (1, 1);
In a concurrent session, run a MERGE statement:
MERGE INTO tab USING (SELECT 1 AS key, 2 AS value) AS source ON source.key = tab.key WHEN MATCHED THEN UPDATE SET value = source.value WHEN NOT MATCHED THEN INSERT VALUES (so[...]
Top posters
Number of posts in the past two months
 Lætitia AVROT - 8
Lætitia AVROT - 8- Dave Page (pgEdge) - 7
- Radim Marek - 6
- Cornelia Biacsics (postgres-contrib.org) - 6
- Floor Drees (EDB) - 5
- Vibhor Kumar - 5
- Jimmy Angelakos - 5
- Hubert 'depesz' Lubaczewski - 4
- Robert Haas (EDB) - 4
- Jeremy Schneider - 4
Top teams
Number of posts in the past two months
- EDB - 14
- pgEdge - 14
- HexaCluster - 8
- Stormatics - 7
- postgres-contrib.org - 6
- Cybertec - 6
- Percona - 5
- Crunchy Data - 2
- Postgres Professional - 2
- PostgreSQL Europe - 2
Feeds
Planet
- Policy for being listed on Planet PostgreSQL.
- Add your blog to Planet PostgreSQL.
- List of all subscribed blogs.
- Manage your registration.
Contact
Get in touch with the Planet PostgreSQL administrators at planet at postgresql.org.