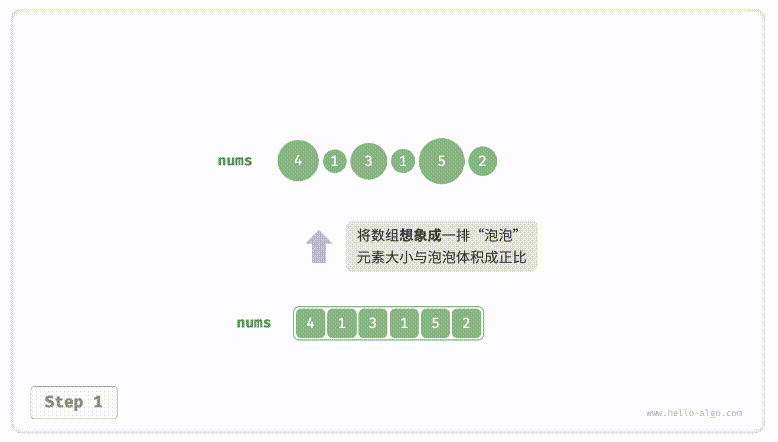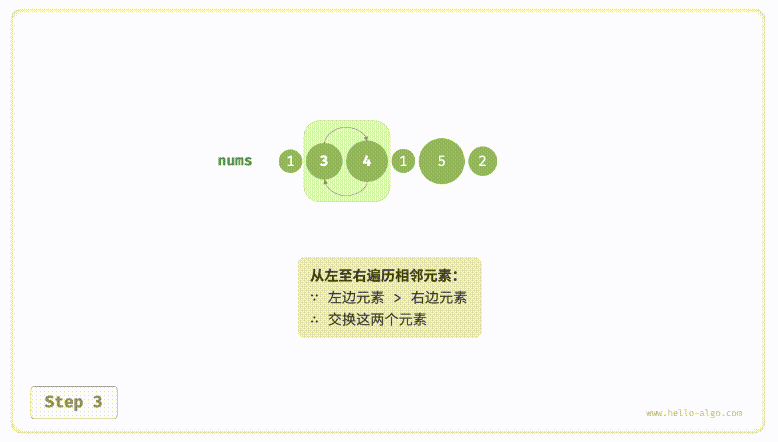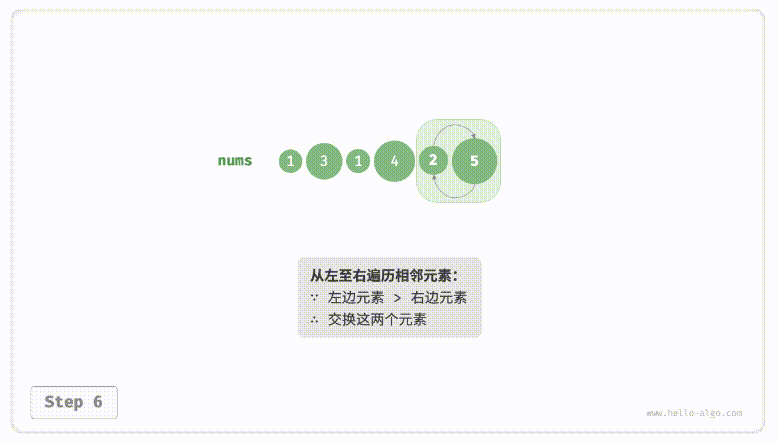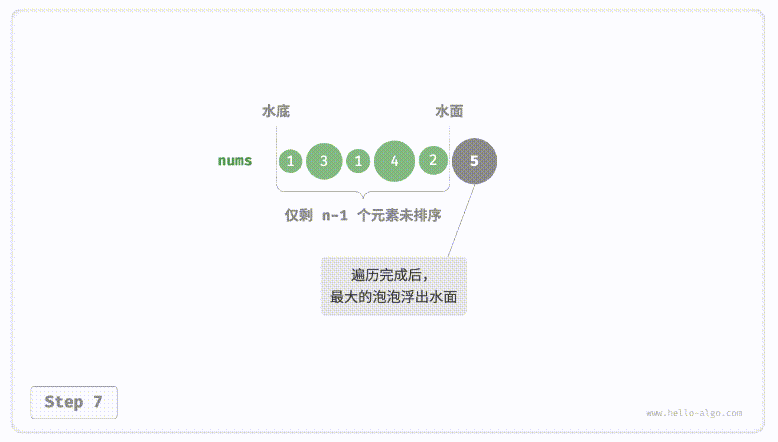
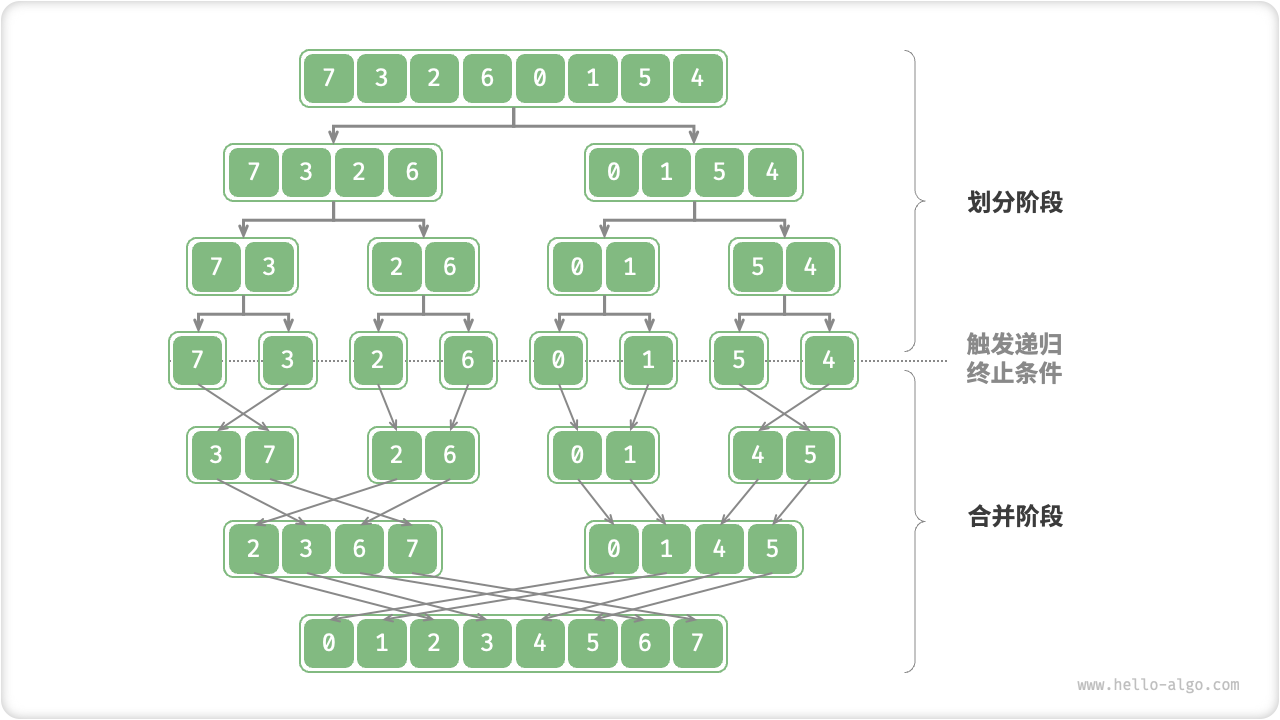
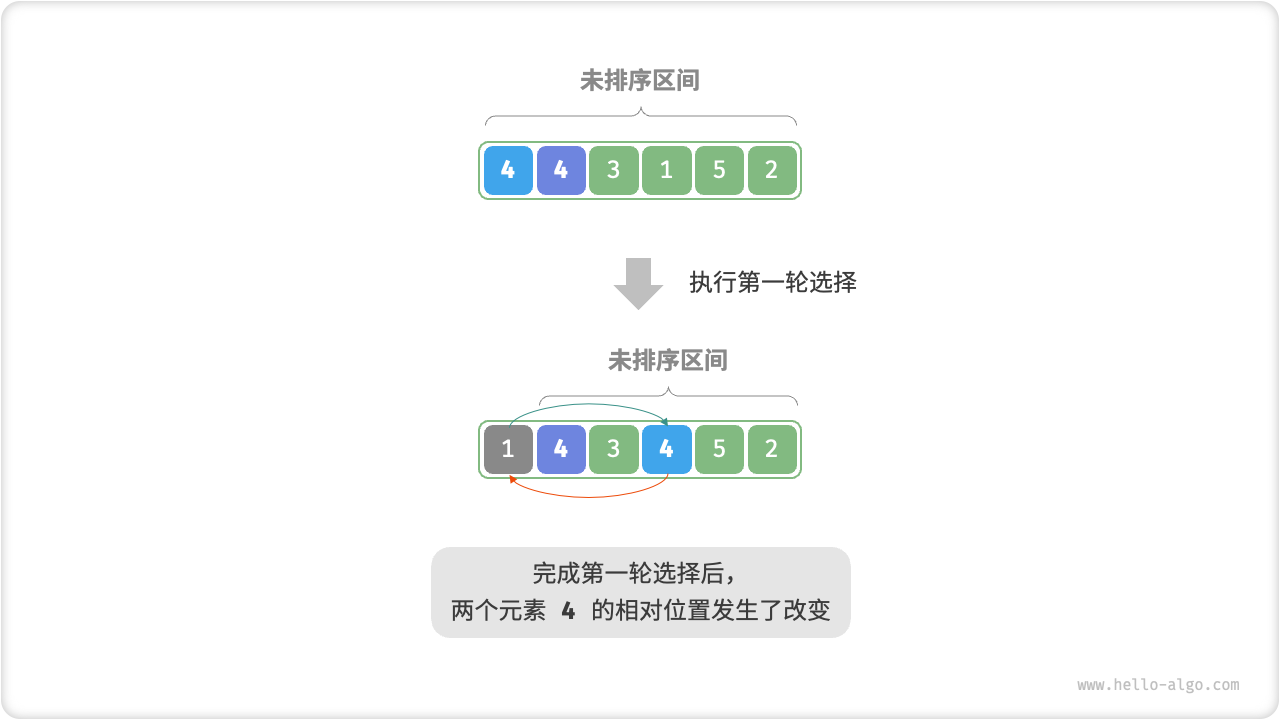
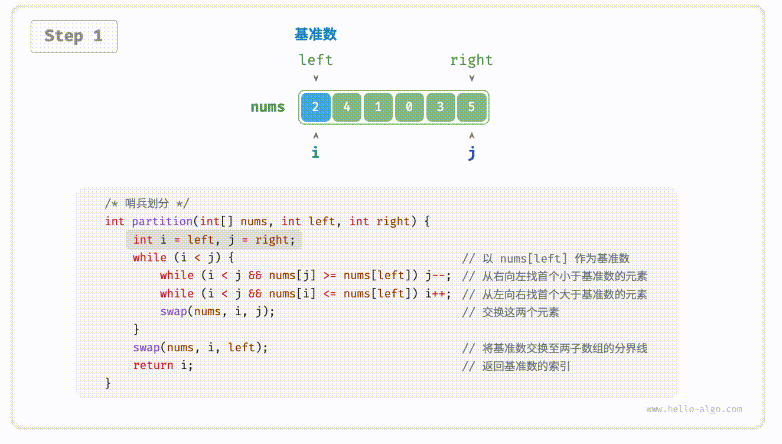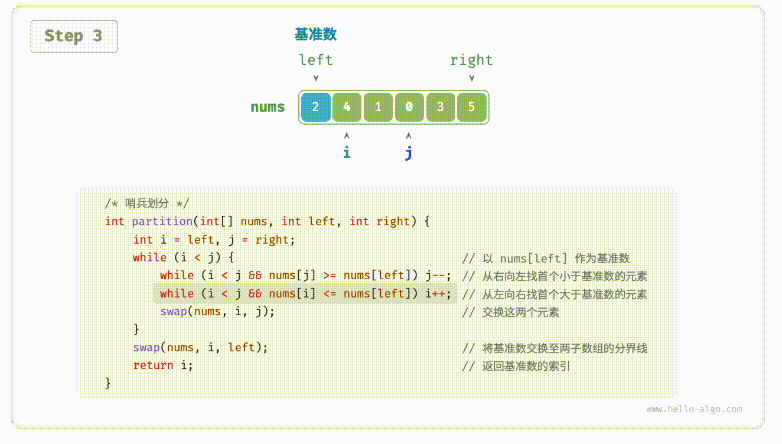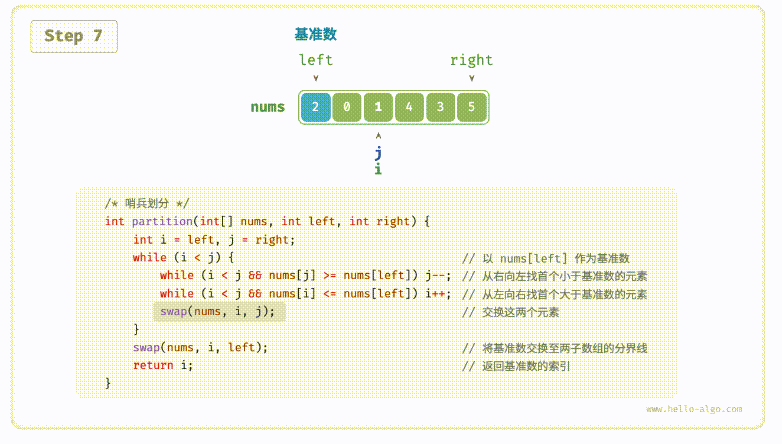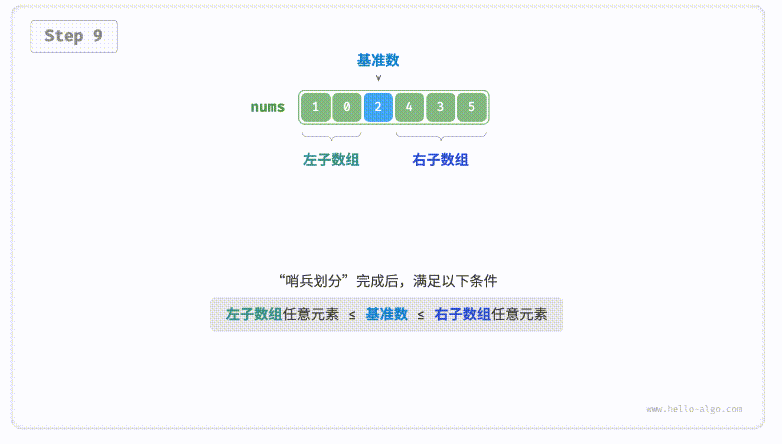
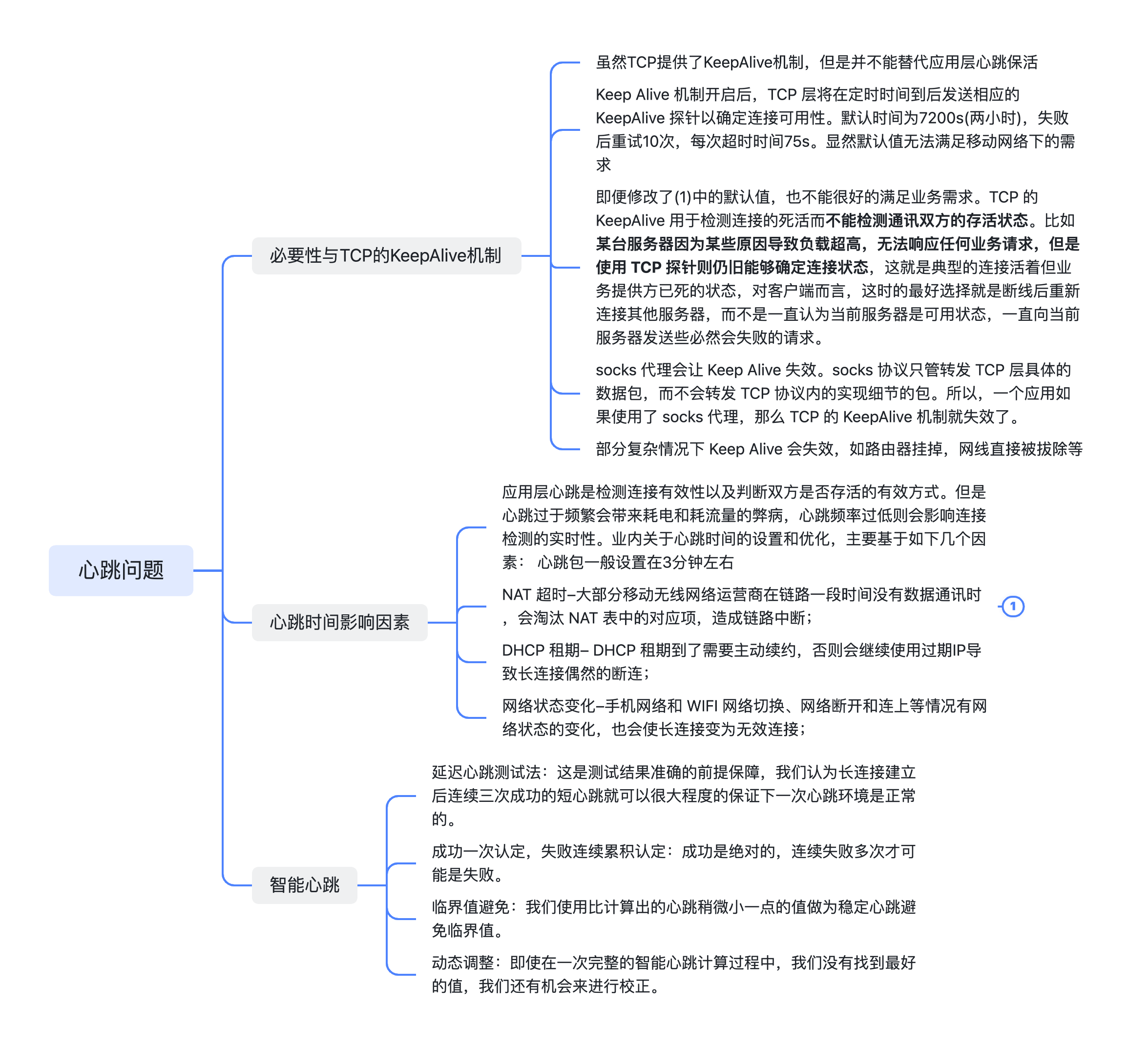
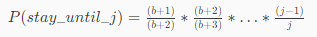defpartition(nums, left, right): i, j = left, right # 以nums[left]作为基准数 while i < j: while i < j and nums[j] >= nums[left]: # 找到右区间第一个比基准数小的 j -= 1 while i < j and nums[i] <= nums[left]: # 找到左区间第一个比基准数大的 i += 1 nums[i], nums[j] = nums[j], nums[i] # 交换这俩,保证左边都比基准数小,右边都比基准数大 nums[i], nums[left] = nums[left], nums[i] # 将基准数放中间 return i # 哨兵位置
defsift_down(nums, root, k): t = nums[root] # 父节点 while root << 1 < k: # k指堆大小 child = root << 1# 左子节点 if child | 1 < k and nums[child | 1] > nums[child]: # 检查右子节点是否有机会 child |= 1 if nums[child] > t: # 如果当前元素更小,则递归向下,使得堆顶元素更大 nums[root] = nums[child] root = child else: # 如果到了合适的位置,则赋值 break nums[root] = t
nums = [0] + nums # 哨兵,基于此可以通过位运算快速定位子节点以及父节点 k = len(nums)
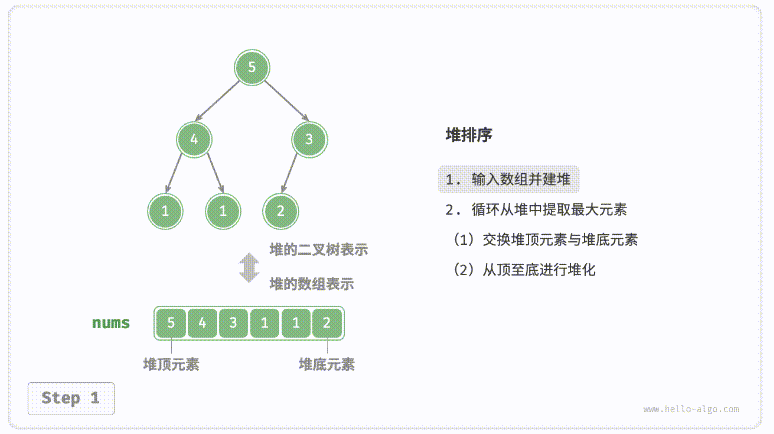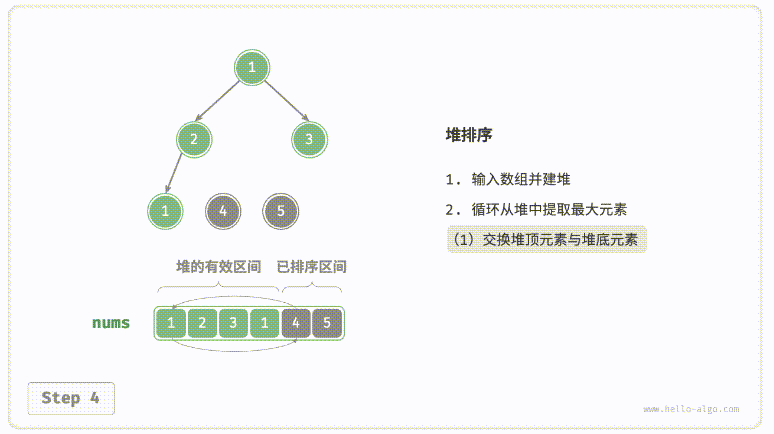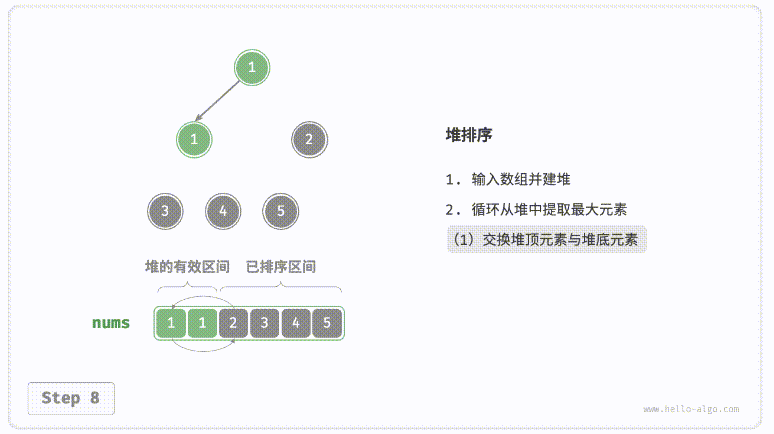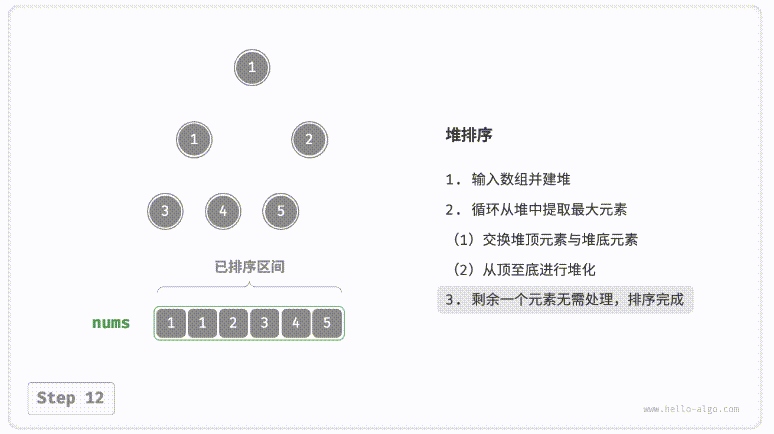
for i inrange((k - 1) >> 1, 0, -1): # 建堆 sift_down(nums, i, k) for i inrange(k - 1, 0, -1): # 取最大元素与堆底元素交换,并从顶到底调整堆 nums[1], nums[i] = nums[i], nums[1] sift_down(nums, 1, i)
print(nums[1:])
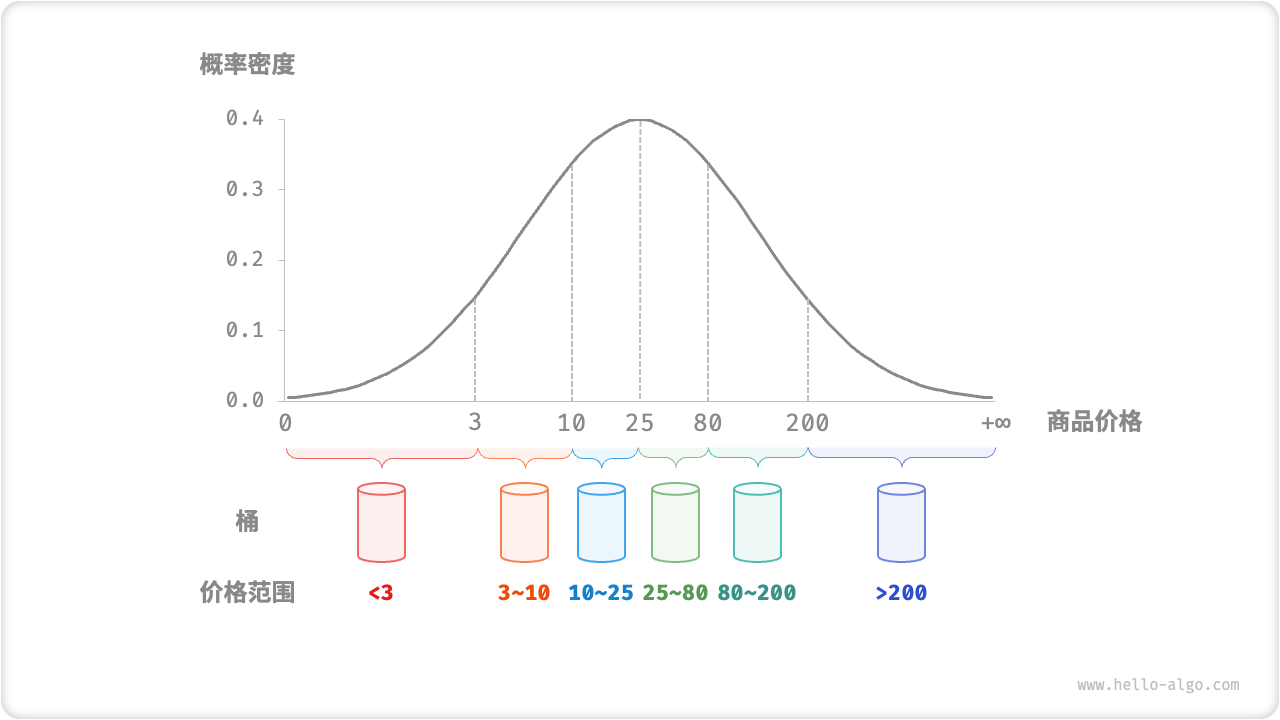
桶排序
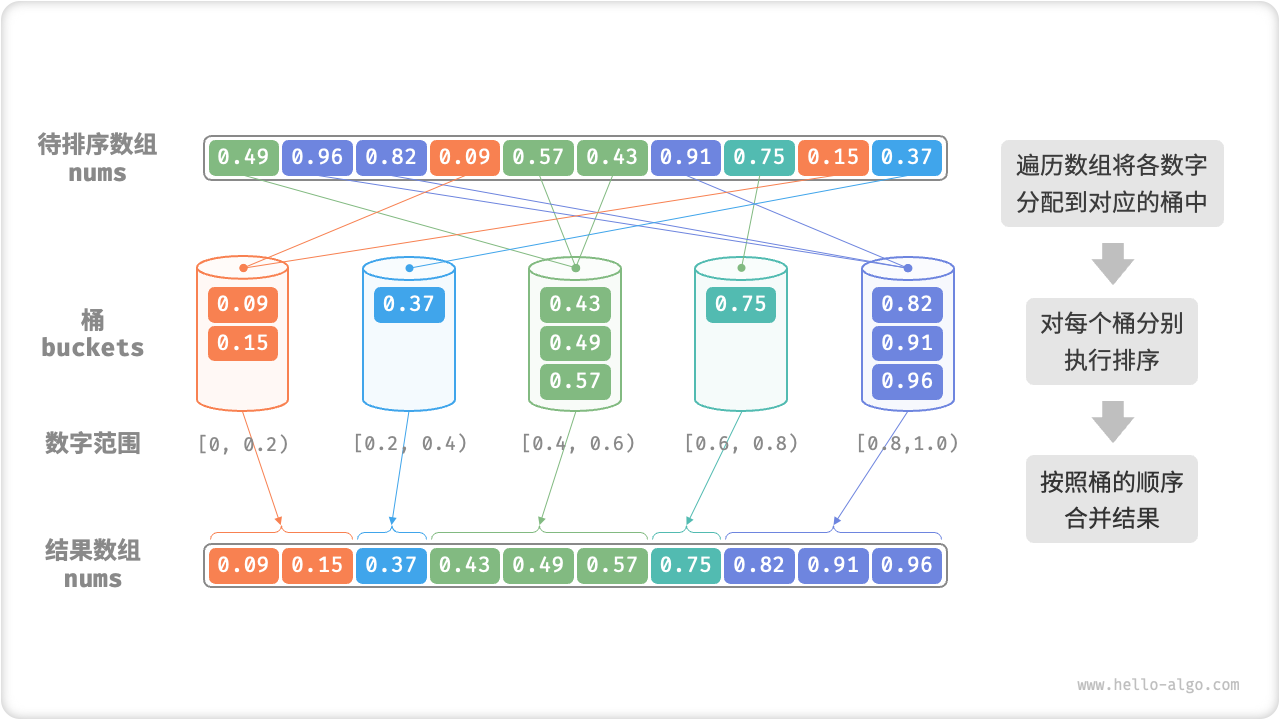
基于分治,非比较的排序算法,通过设置一些具有大小的桶,每个桶对应一个数据范围,将数据平均分散到桶中,然后对桶内执行排序(往往不需要,因为多数只有一个数),最终按照桶范围合并。时间复杂度一般是线性的,n 个数 k 个桶,O(n + k),假设分布均匀,每个桶内元素 O(n/k),排序耗时 O((n/k)log(n/k)),所有桶排序则 O(nlog(n/k))。当桶足够大,分散足够均匀,每个桶一个数,则趋向于O(n)。是否稳定基于桶内排序是否稳定。
流程如下
初始化 k 个桶,将 n 个数分到 k 个桶
k 个桶分别执行排序
从小到大合并 k 个桶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
nums = [56, 32, 13, 26, 43] n = len(nums)
k = 6 bucket = [[] for _ inrange(k)] # 分k个桶 for x in nums: i = x // 10 bucket[i].append(x) for b in bucket: b.sort() i = 0 for x in bucket: for xx in x: nums[i] = xx i += 1 print(nums)
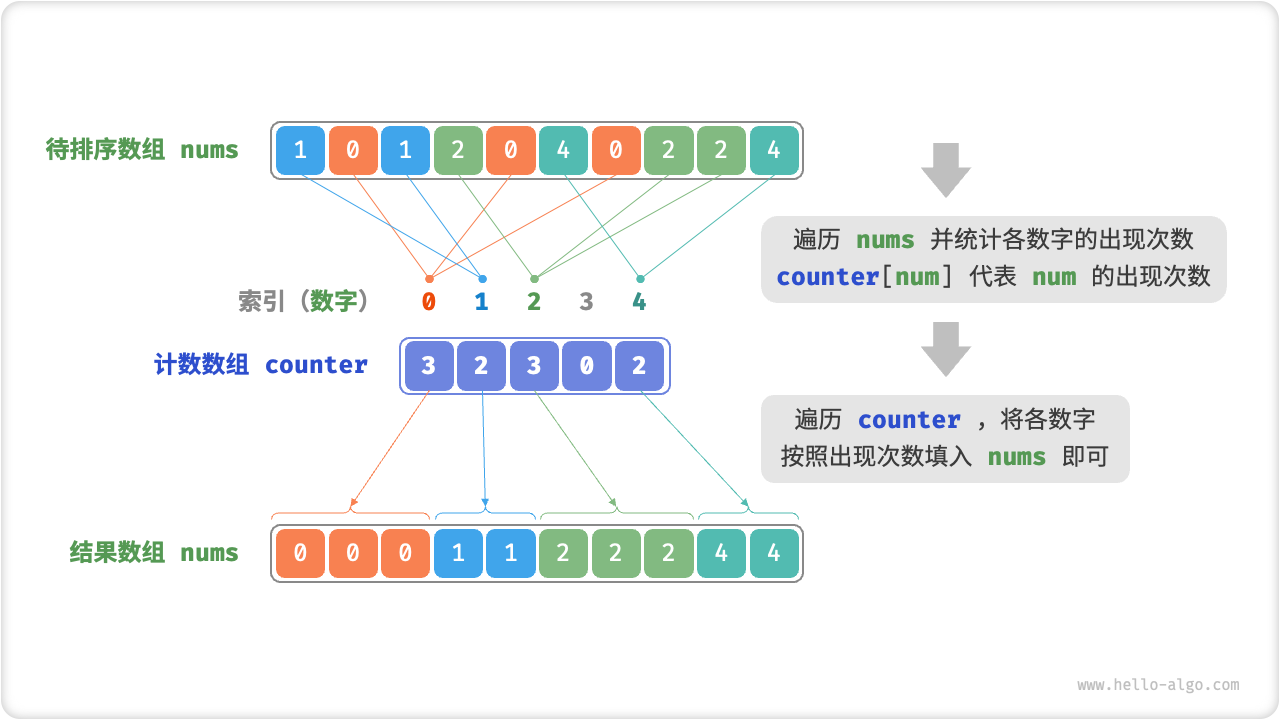
通过统计数量来对元素实现排序,适用于较为密集的数组。时间复杂度O(n + m),包括遍历数组以及计数器。一般 n >> m,趋近于 O(n)。通过倒序遍历可以避免修改元素之间的相对位置,正序则非稳定。
流程如下
遍历数组找到最大数 m,创建一个 m+1 辅助数组
遍历数组计数
编辑计数器统计出现次数,填充即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14
nums = [5, 3, 1, 2, 4, 3, 2, 1] n = len(nums)
maxx = max(nums) c = [0] * (maxx + 1) for x in nums: c[x] += 1 idx = 0 for i, x inenumerate(c): # 遍历计数器 while x > 0: # 递减计数器 nums[idx] = i # 填充nums x -= 1 idx += 1 print(nums) # [1, 1, 2, 2, 3, 3, 4, 5]
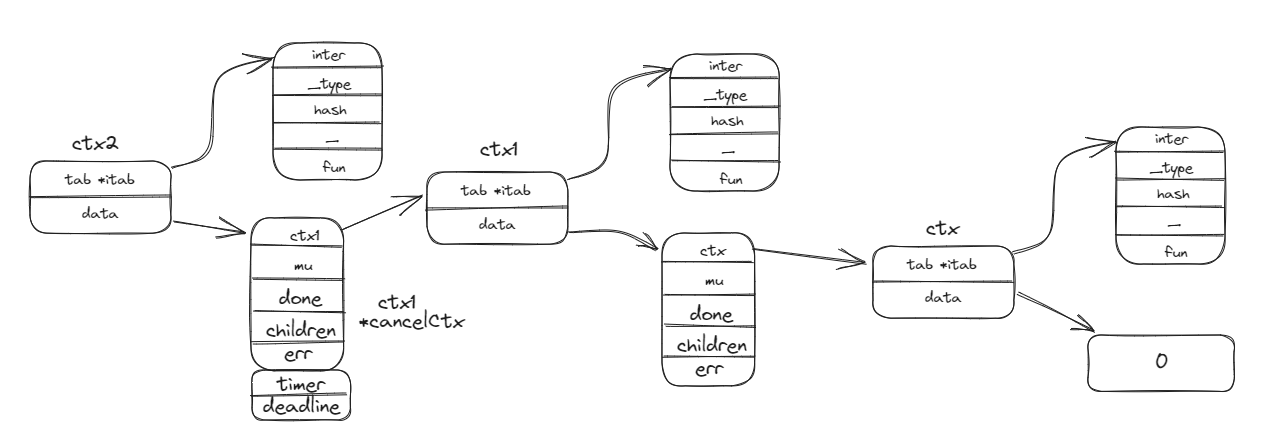
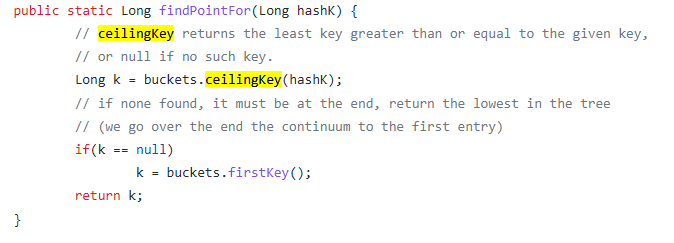
// A Context carries a deadline, a cancellation signal, and other values across // API boundaries. // // Context's methods may be called by multiple goroutines simultaneously. type Context interface { Deadline() (deadline time.Time, ok bool) Done() <-chanstruct{} Err() error Value(key any) any }
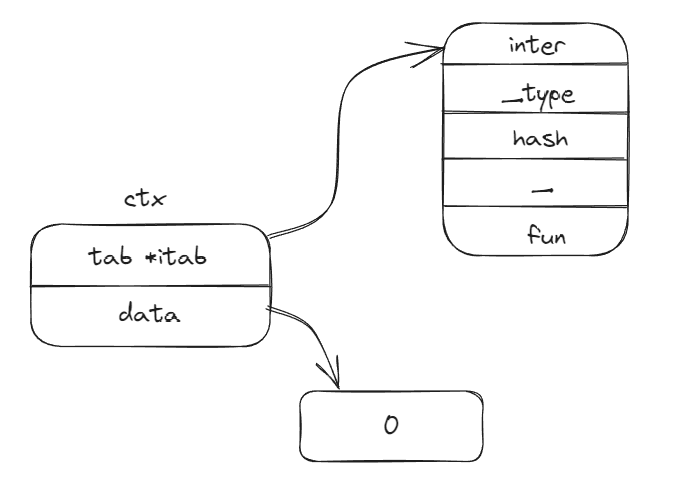
从 emptyCtx 起
其中emptyCtx 只是对这四个方法进行了简单地实现:返回默认值、nil 或者 false。你可能感到很疑惑,emptyCtx 看起来像是什么也没做,恰如其名,事实上确实是这样。emptyCtx 是以 int 为基础定义的自定义类型,不过即使是其他的类型,我们也能够接受。
// An emptyCtx is never canceled, has no values, and has no deadline. It is not // struct{}, since vars of this type must have distinct addresses. type emptyCtx int
func(*emptyCtx) Deadline() (deadline time.Time, ok bool) { return }
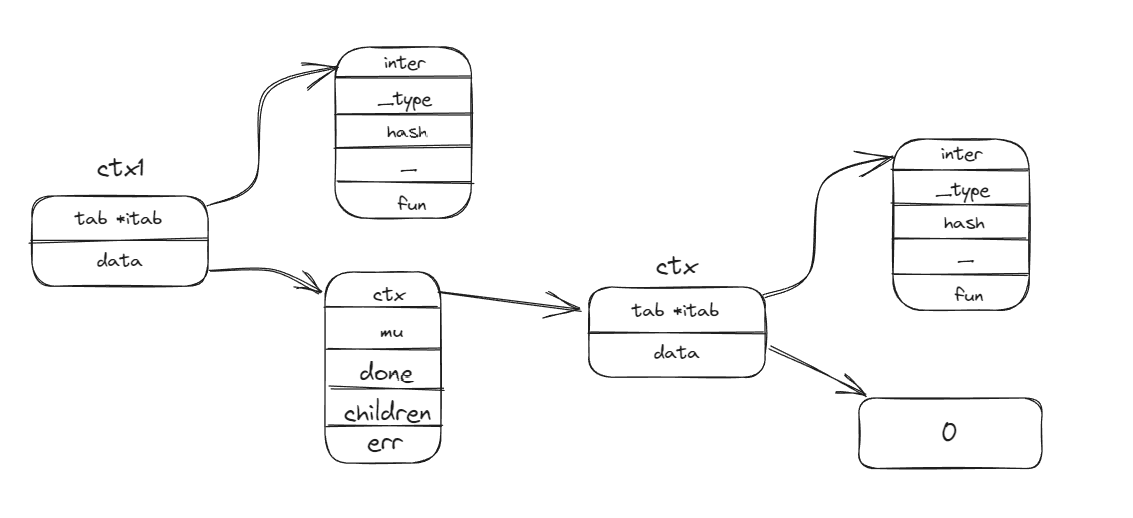
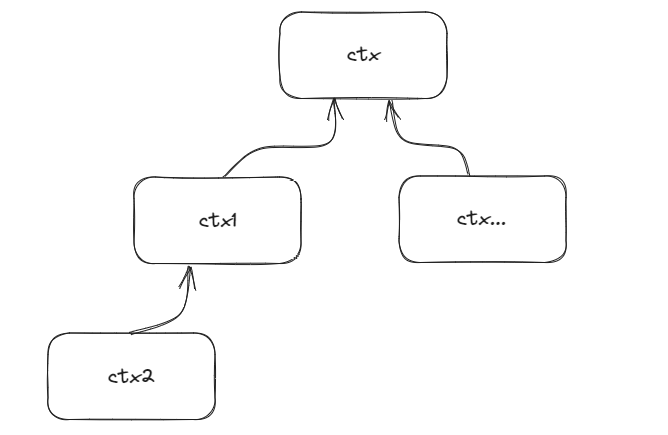
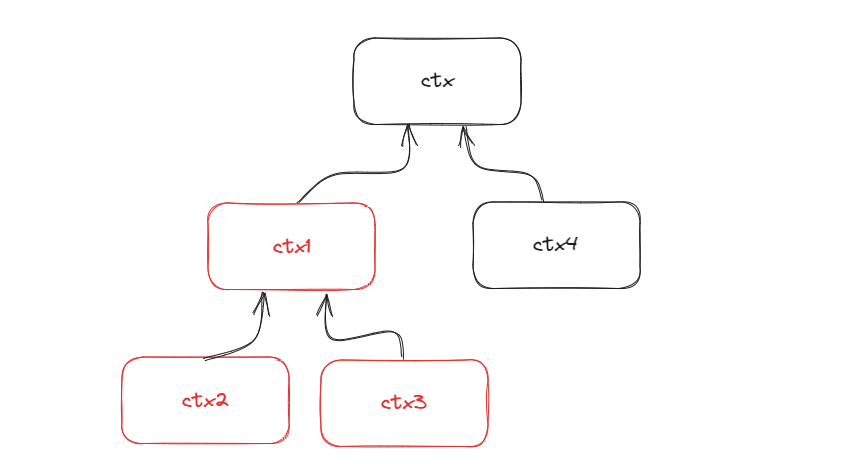
funcwithCancel(parent Context) *cancelCtx { if parent == nil { panic("cannot create context from nil parent") } c := newCancelCtx(parent) propagateCancel(parent, c) return c }
func(c *cancelCtx) Done() <-chanstruct{} { d := c.done.Load() if d != nil { return d.(chanstruct{}) } c.mu.Lock() defer c.mu.Unlock() d = c.done.Load() if d == nil { d = make(chanstruct{}) c.done.Store(d) } return d.(chanstruct{}) }
// goroutines counts the number of goroutines ever created; for testing. var goroutines atomic.Int32
// propagateCancel arranges for child to be canceled when parent is. funcpropagateCancel(parent Context, child canceler) { done := parent.Done() // 一次检查:继承父级的done方法,如果父级是*emptyCtx就直接返回 if done == nil { return }
func(c *valueCtx) Value(key any) any { if c.key == key { return c.val } return value(c.Context, key) }
funcvalue(c Context, key any) any { for { switch ctx := c.(type) { case *valueCtx: if key == ctx.key { return ctx.val } c = ctx.Context case *cancelCtx: if key == &cancelCtxKey { return c } c = ctx.Context case *timerCtx: if key == &cancelCtxKey { return ctx.cancelCtx } c = ctx.Context case *emptyCtx: returnnil default: // 向上递归调用 return c.Value(key) } } }
// NewAsyncContext create a new async context // the context will not be canceled when the parent context is canceled funcNewAsyncContext(ctx context.Context) context.Context { if ctx == nil { returnnil } return &asyncCtx{Context: ctx} }
[root@harbor ~]# ip netns add ns1 [root@harbor ~]# ip netns add ns2 [root@harbor ~]# ip netns ns2 ns1 root@harbor ~]# ip netns exec ns1 ip link list 1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 [root@harbor ~]# ip netns exec ns2 ip link list 1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
[root@harbor ~]# ip link add veth1 type veth peer name veth1-peer [root@harbor ~]# ip linkset veth1 netns ns1 [root@harbor ~]# ip linkset veth1-peer netns ns2 [root@harbor ~]# ip netns exec ns1 ip addr 1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 2739: veth1@if2738: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000 link/ether a2:48:9b:37:b0:37 brd ff:ff:ff:ff:ff:ff link-netnsid 0 [root@harbor ~]# ip netns exec ns2 ip addr 1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 2738: veth1-peer@if2739: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000 link/ether 16:94:b7:58:e9:3e brd ff:ff:ff:ff:ff:ff link-netnsid 0
[root@harbor ~]# ip netns exec ns1 ip addr add 172.16.0.1/24 dev veth1 [root@harbor ~]# ip netns exec ns1 ip linkset dev veth1 up [root@harbor ~]# ip netns exec ns2 ip addr add 172.16.0.2/24 dev veth1-peer [root@harbor ~]# ip netns exec ns2 ip linkset dev veth1-peer up 1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 2739: veth1@if2738: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000 link/ether a2:48:9b:37:b0:37 brd ff:ff:ff:ff:ff:ff link-netnsid 1 inet 172.16.0.1/24 scope global veth1 valid_lft forever preferred_lft forever inet6 fe80::a048:9bff:fe37:b037/64 scope link valid_lft forever preferred_lft forever [root@harbor ~]# ip netns exec ns2 ip addr 1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 2738: veth1-peer@if2739: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000 link/ether 16:94:b7:58:e9:3e brd ff:ff:ff:ff:ff:ff link-netnsid 0 inet 172.16.0.2/24 scope global veth1-peer valid_lft forever preferred_lft forever inet6 fe80::1494:b7ff:fe58:e93e/64 scope link valid_lft forever preferred_lft forever
测试两个 namespace 是否互通:
1 2 3 4 5
[root@harbor ~]# ip netns exec ns1 ping 172.16.0.2 PING 172.16.0.2 (172.16.0.2) 56(84) bytes of data. 64 bytes from 172.16.0.2: icmp_seq=1 ttl=64 time=0.072 ms 64 bytes from 172.16.0.2: icmp_seq=2 ttl=64 time=0.070 ms 64 bytes from 172.16.0.2: icmp_seq=3 ttl=64 time=0.051 ms
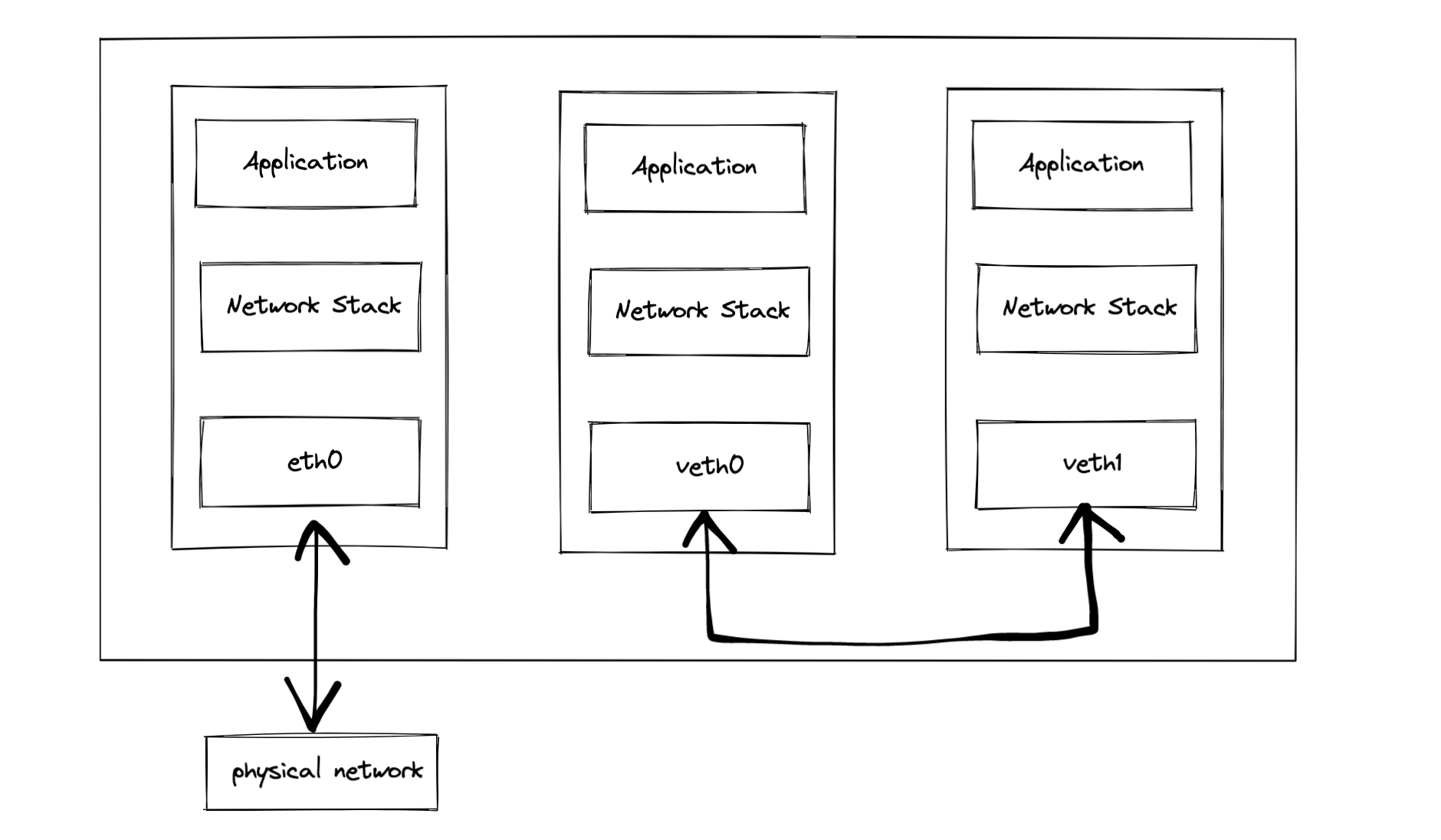
Veth Pair
“veth devices are virtual Ethernet devices. They can act as tunnels between network namespaces to create a bridge to a physical network device in another namespace, but can also be used as standalone network devices.”
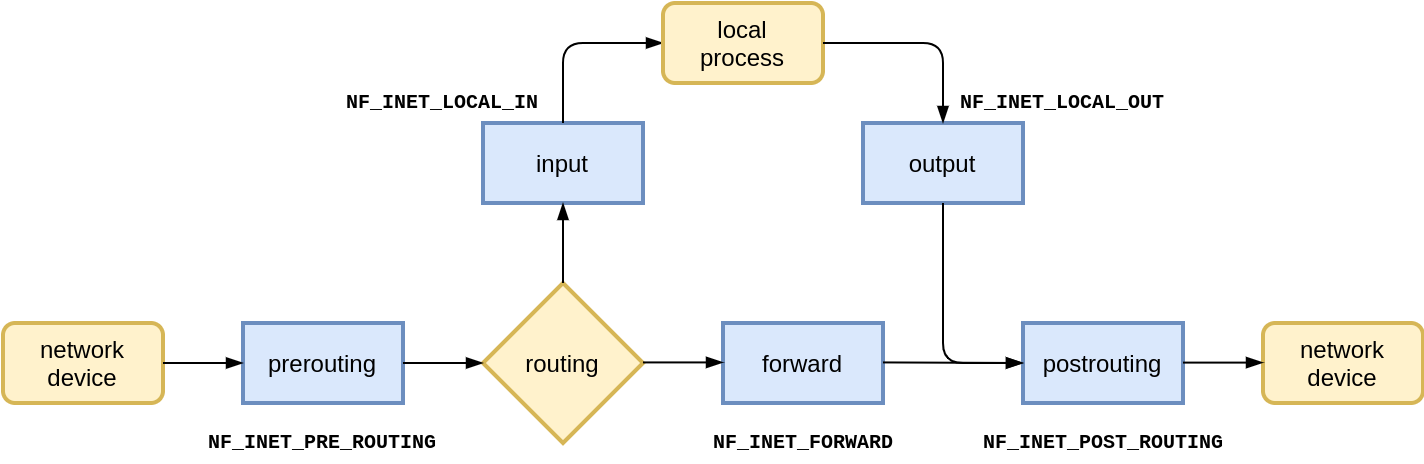
如果两个 namespace 处于不同的子网中,就无法通过作用于二层的 bridge 进行连接,只能通过路由器进行三层转发。所谓路由其实很简单,就是选择哪张网卡将数据写进去,至于选择哪张网卡呢,规则在路由表中指定。Linux 拥有多张路由表,最常用的是 local 和 main。
local 路由表统一记录本网络命名空间的网卡设备 IP 的路由规则。
1 2 3
[root@harbor ~]# ip route list table local local 61.174.x.y dev eth0 proto kernel scope host src 61.174.x.y local 127.0.0.1 dev lo proto kernel scope host src 127.0.0.1
其余基本存在 main 表中,可以用ip route list table local或者route -n看。
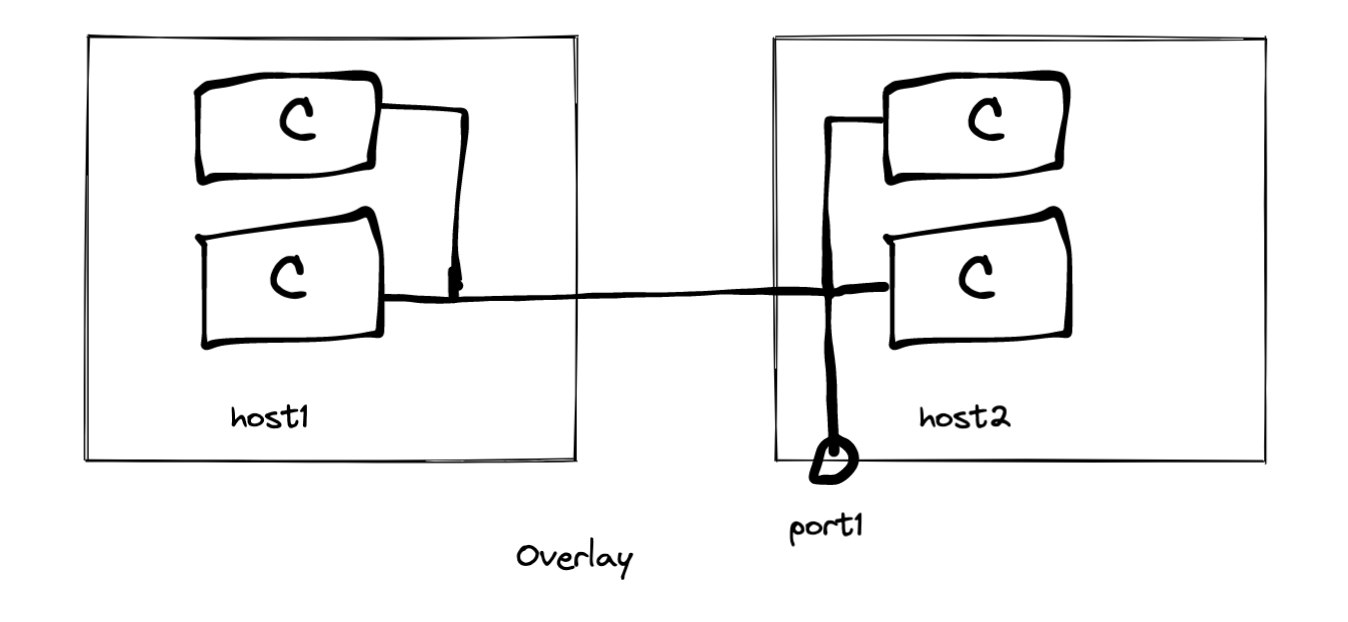
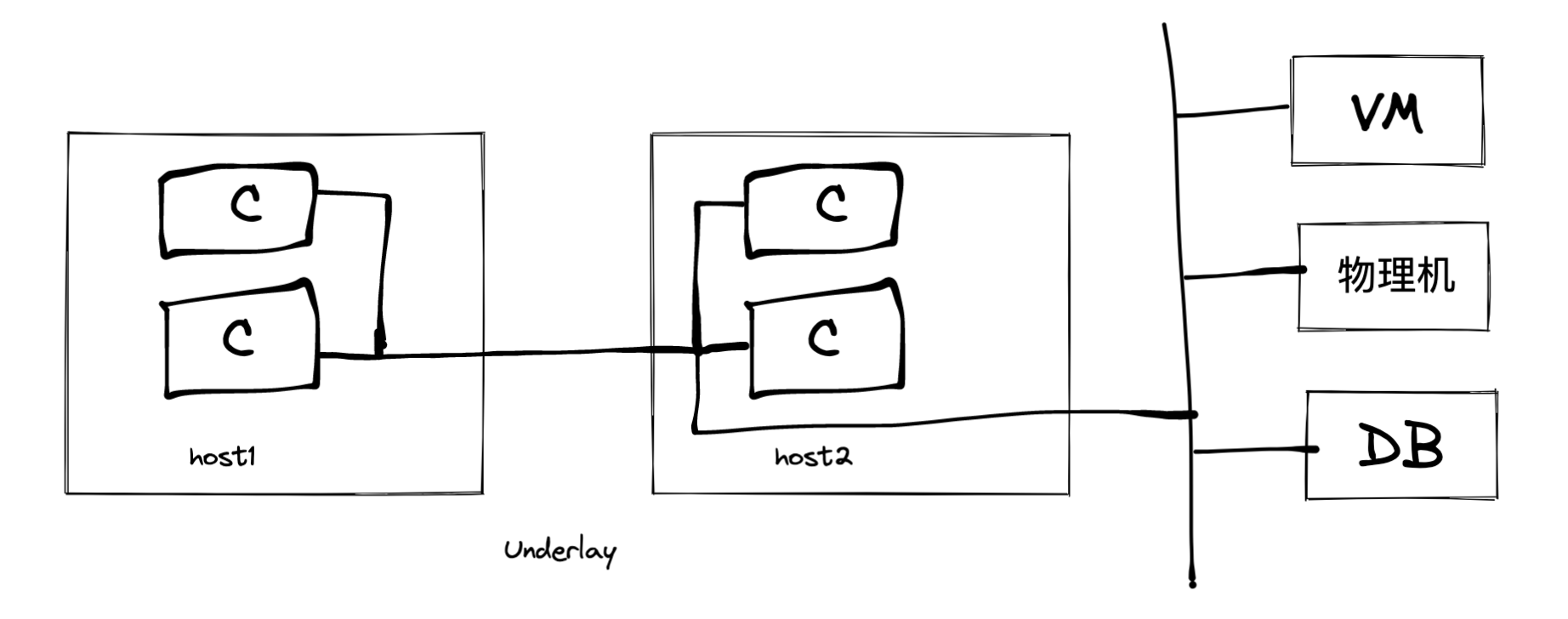
在 Linux 中,要虚拟化网络资源以使容器认为每个都拥有专用的网络栈,可以通过使用网络命名空间(netns)和虚拟以太网设备(veth)实现。网络命名空间创建了独立的网络栈,每个容器可以与一个网络命名空间关联,从而实现网络隔离。veth 设备成对出现,连接主机的根网络命名空间(root netns)与容器的网络命名空间,使容器在通信时表现得好像拥有独立的网络栈,有效地利用网络资源,确保各个容器之间的网络环境隔离。
如何在容器之间实现隔离与通信,确保良好的容器互操作性?
为了在容器之间实现隔离与通信,我们可以利用 Linux 的网络命名空间(netns)和虚拟以太网设备(veth)。通过网络命名空间,每个容器都可以拥有独立的网络栈,从而实现隔离。然后,使用虚拟以太网设备将这些容器连接到一个虚拟网络交换机(bridge),使它们处于同一以太网段内,实现容器之间的通信。虚拟交换机会转发容器之间的数据包,保证良好的容器互操作性。通过这种方法,我们可以在同一主机上运行多个容器,实现资源共享,并确保它们在隔离的同时能够相互通信。
容器如何与外部网络连接?
为了使容器与外部网络连接,我们需要创建一个虚拟交换机(bridge),并将容器的虚拟以太网设备(veth)连接到该交换机。这样,容器之间可以相互通信,同时也可以通过交换机连接到主机和外部网络。为了实现这一连接,我们需要为交换机分配 IP 地址,并将其设置为容器的默认网关。同时,启用网络地址转换(NAT)功能,以便在容器发送到外部网络的数据包上替换源 IP 地址为主机的外部接口地址,从而使外部网络可以回复数据包给容器。最后,如果需要将容器的某个端口发布到主机的接口上,可以使用 iptables 进行端口转发,将到达主机特定端口的数据包重定向到容器的对应端口。通过这些步骤,我们可以实现容器与外部网络之间的连接,使容器能够与外部服务通信,并让外部网络能够访问容器的特定端口。
总结
本篇文章主要介绍容器网络,从容器网络的演变历史到 Docker 官网的一些描述,再到 Linux 内核网络、网络虚拟化来探究容器的大致底层实现原理,最后回答了单主机容器网络的几个问题。笔者在前一段时间深入学习过 Linux 网络相关知识,本以为容器网络无非是使用到几条命令,官网以及书上的几个简短说明这么简单,在翻阅参考资料与深入学习的过程中,笔者才发现容器网络有着非常庞大且复杂的体系,由于阅历与经验有限,文中多数部分都只是简单介绍就略过了。当然,此篇也只是初探开篇,后续会更深入理解容器网络相关的知识。
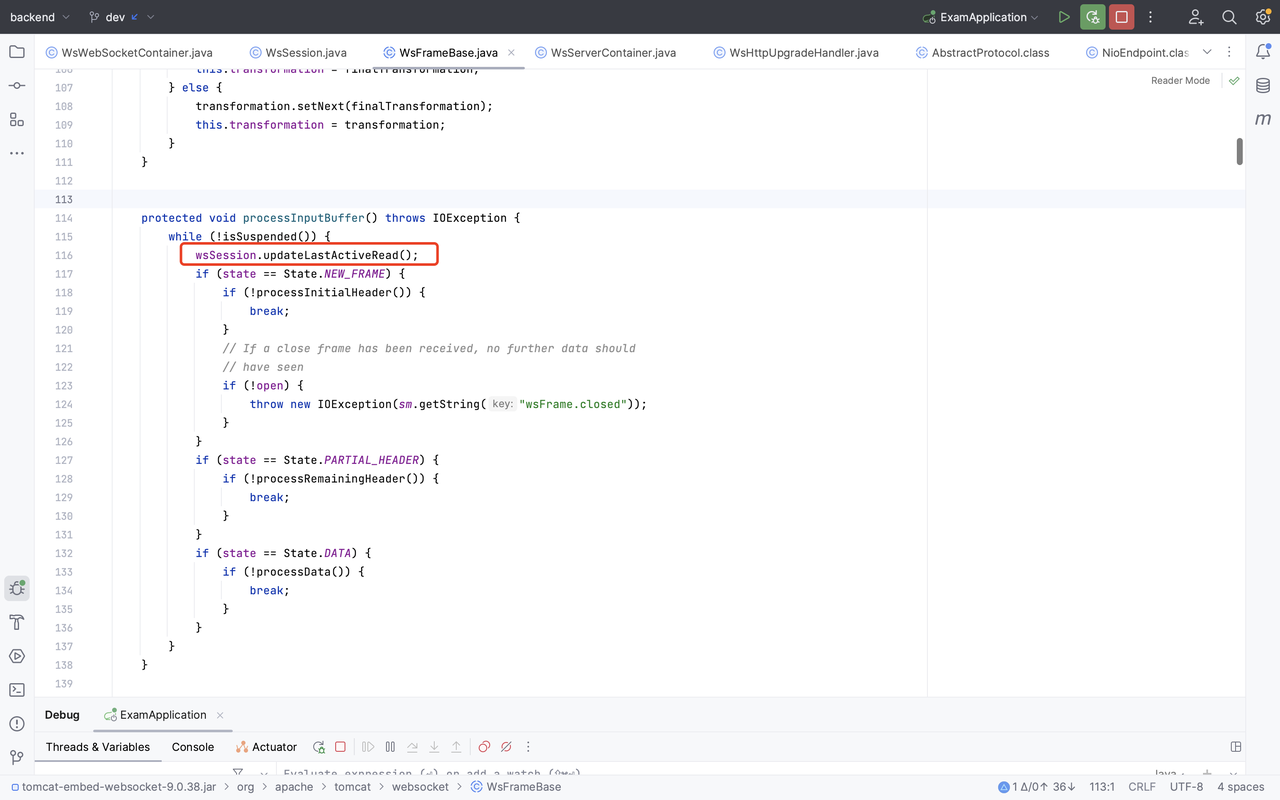
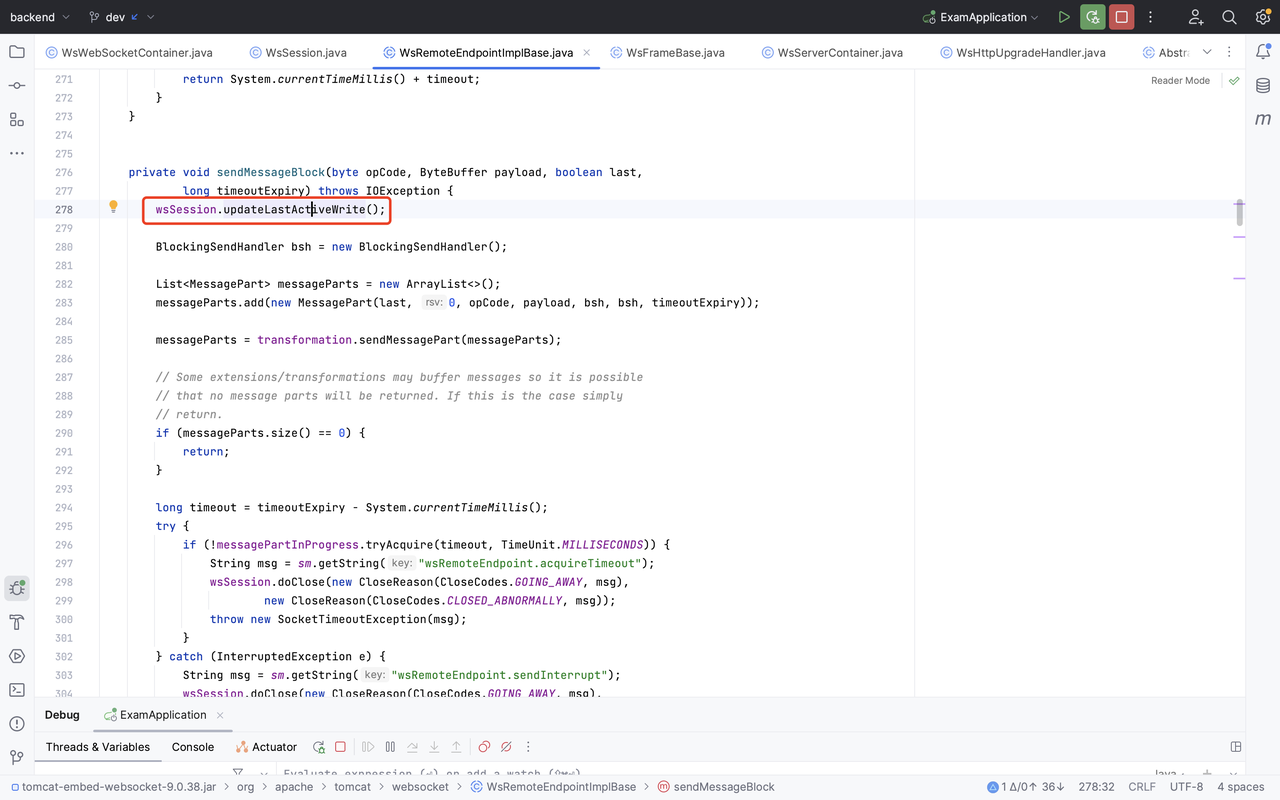
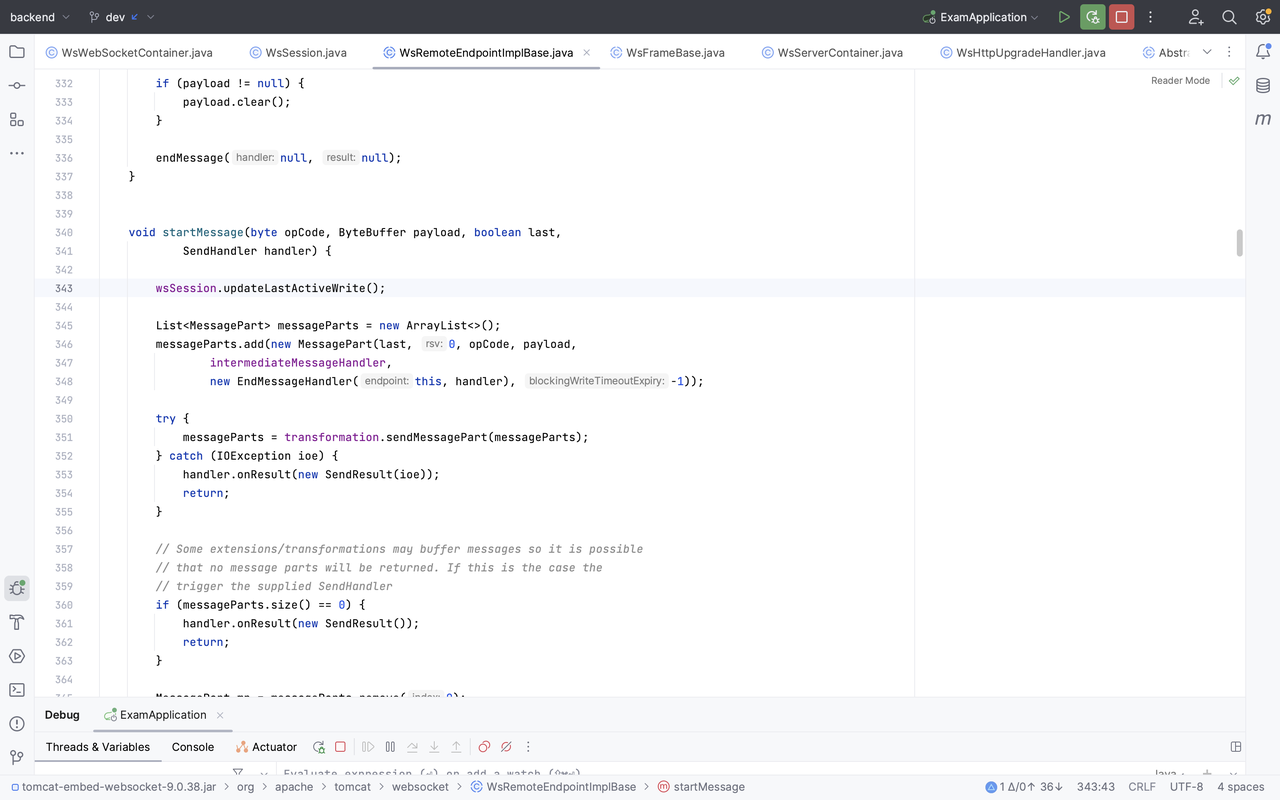
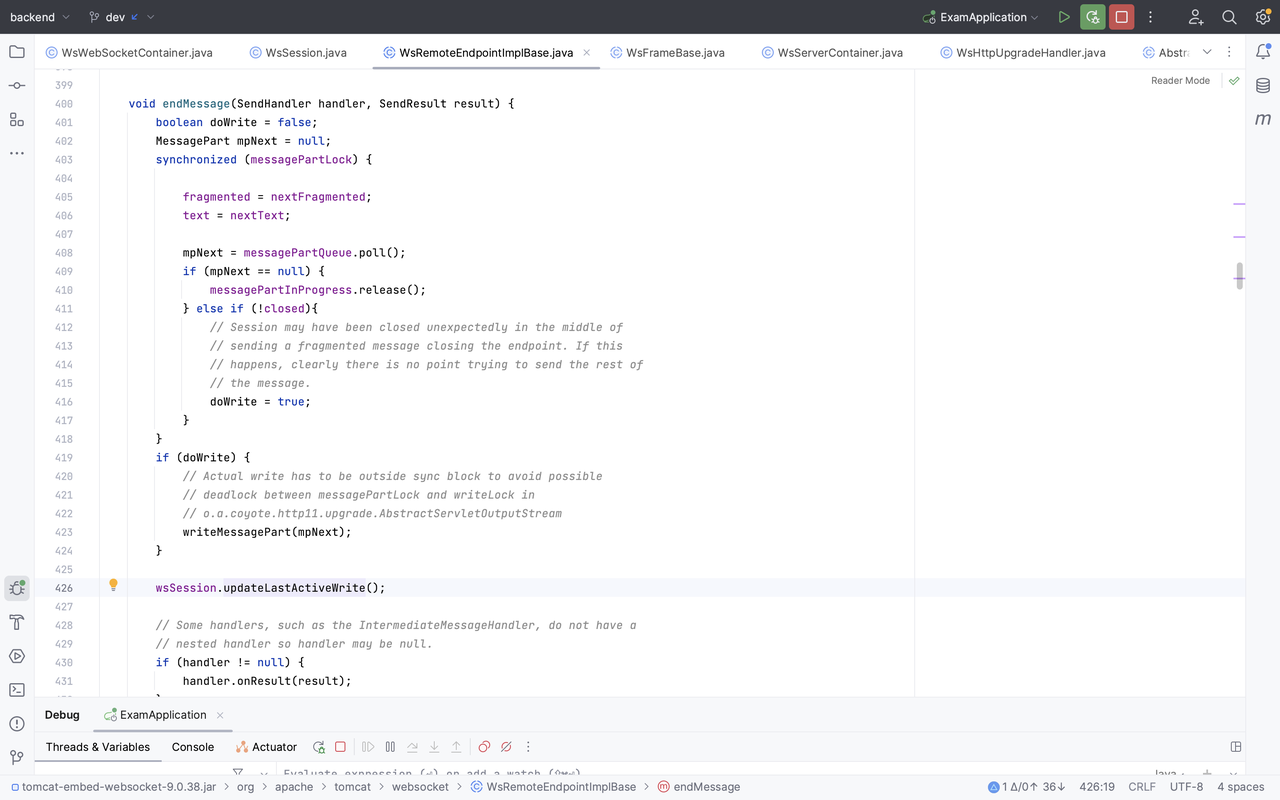
@Override publicvoidbackgroundProcess() { // This method gets called once a second. backgroundProcessCount ++; if (backgroundProcessCount >= processPeriod) { backgroundProcessCount = 0;
for (WsSession wsSession : sessions.keySet()) { wsSession.checkExpiration(); } } }
protectedvoidcheckExpiration() { // Local copies to ensure consistent behaviour during method execution longtimeout= maxIdleTimeout; longtimeoutRead= getMaxIdleTimeoutRead(); longtimeoutWrite= getMaxIdleTimeoutWrite();
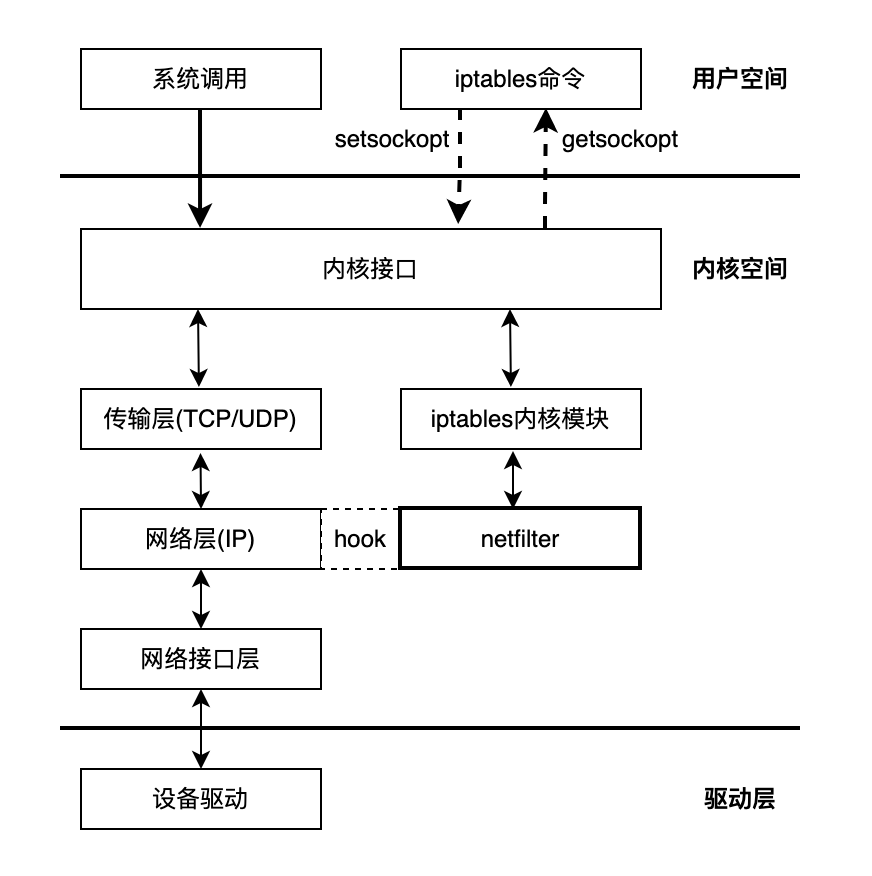
内核还提供了一组链表操作接口,比如 list_add() 加入一个新节点到链表中,他们都有一个统一的特点,就是只接受 list_head 结构作为参数。通过使用宏 container_of()我们可以很方便地从链表指针找到父结构包含的任何变量,因为在 c 语言中,一个给定的结构中的变量偏移在编译时地址就被 ABI 固定下来了。
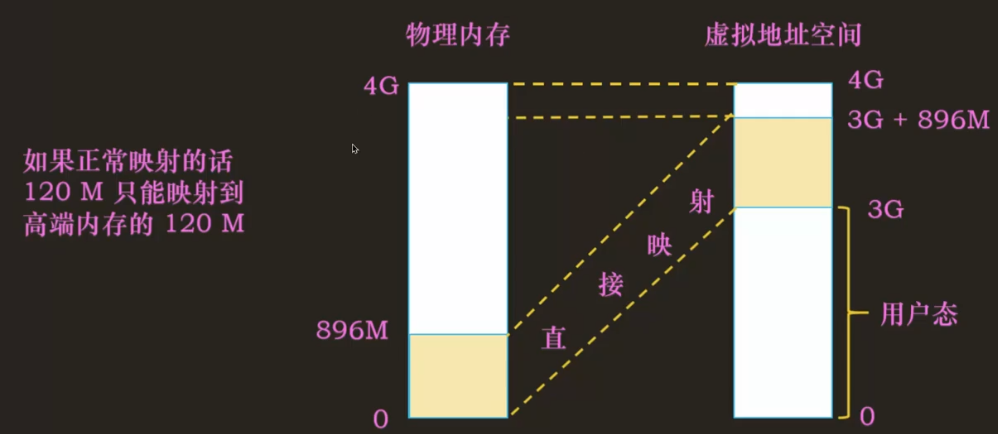
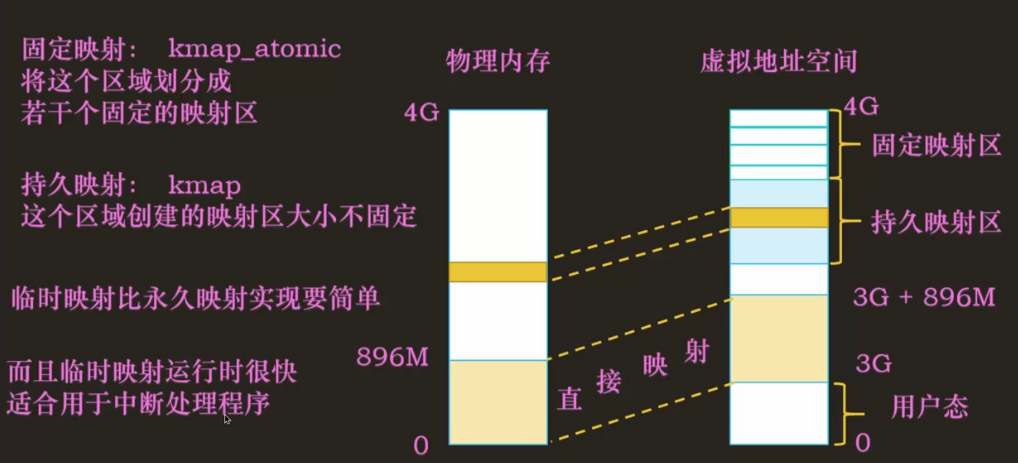
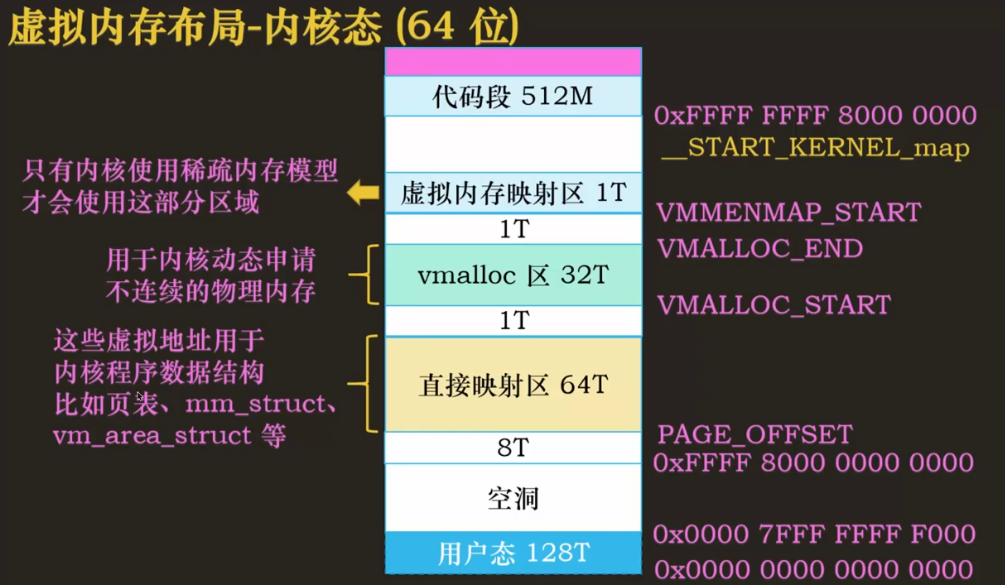
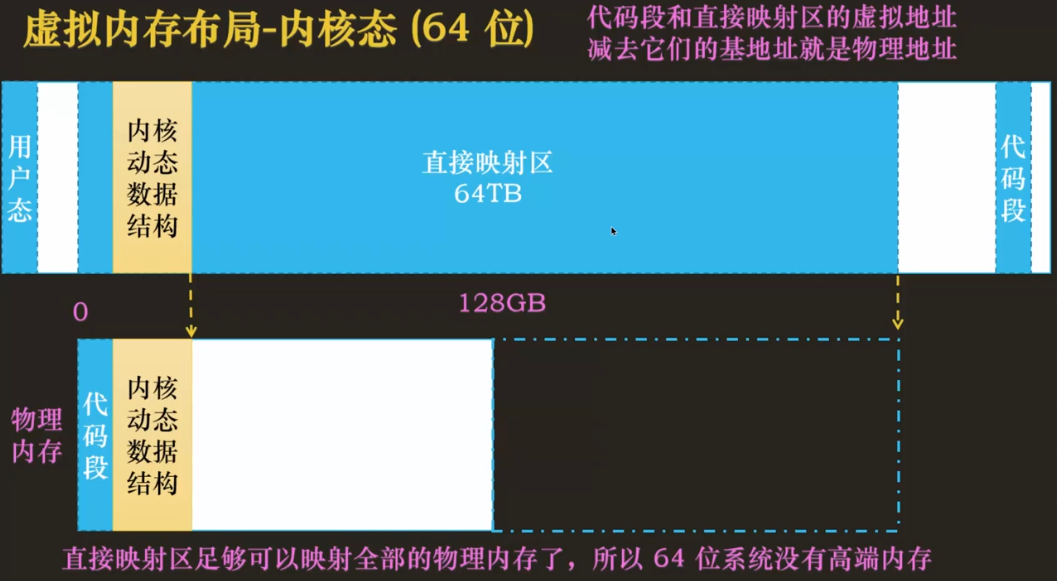
当一个进程被调度时,该进程 mm 字段指向的地址空间被加载到内存中,task_struct 的 active__mm 会更新,指向新的地址空间。当一个内核线程被调度时,内核会发现它的 mm 字段为 NULL,所以会保留前一个进程的地址空间,active_mm 指向前一个进程的地址空间,在内核线程需要的时候就能通过前一个进程的地址空间去使用一些关于内核内存相关的信息。
Linux 中使用三级页表完成地址转换,利用多级页表能够节约地址转换占用的空间。如果用静态页表来实现页表,即使不存放数据,光是页表也会占用大量空间。Linux 对所有体系结构(包括不支持三级页表的体系结构)都用三级页表管理,因为三级页表结构可以利用最大公约数思想——按照需要在编译时简化使用页表的三级结构,如只使用两级。最大公约数思想我理解为追求共同点,即兼容,使用三级结构时,可以兼容使用二级的情况。
回写策略,也是 Linux 所采用的。写操作直接写到缓存中,后端存储不会立刻更新,而是将页高速缓存中被写入的页标记为脏页,并加入到脏页链表中,由回写进程周期性将脏写链表中的页写回到磁盘,可以保证缓存数据与磁盘数据的最终一致性。这个策略会有数据丢失的风险,而且实现复杂度高,但是能方便以后更多时间内合并更多的数据和再一次刷新,减少磁盘 I/O 次数。
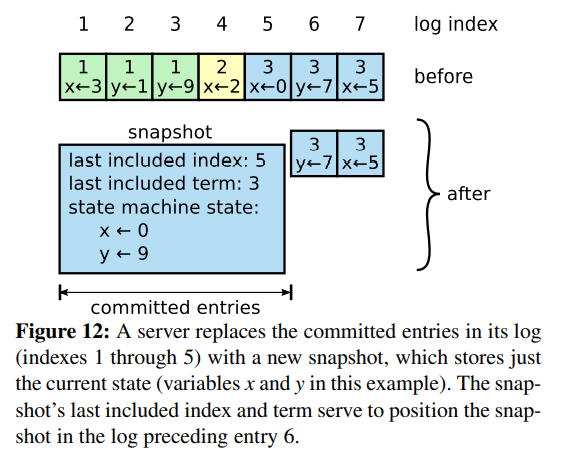
这些 metadata 支持了快照后的第一个 entry 的一致性检查,因为那个 entry 需要先前一个 entry 的 index 和 term。为了支持集群成员变更,快照包含了到 last included index 为止的最新的配置,一旦一个节点完成了写入快照,可能会删除所有在 last included index 之前的日志条目,以及之前的快照。
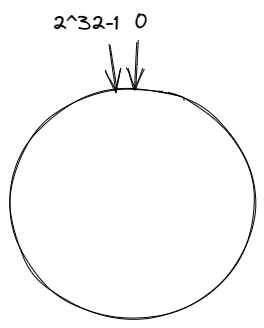
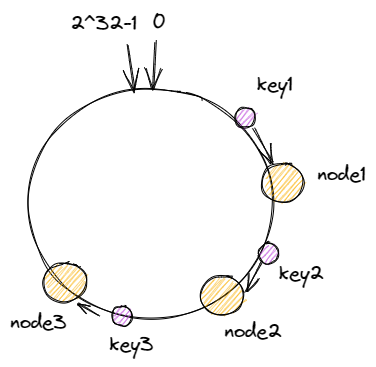
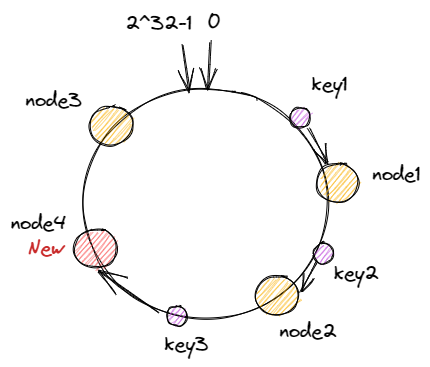
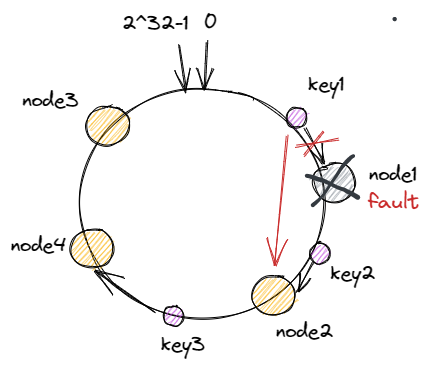
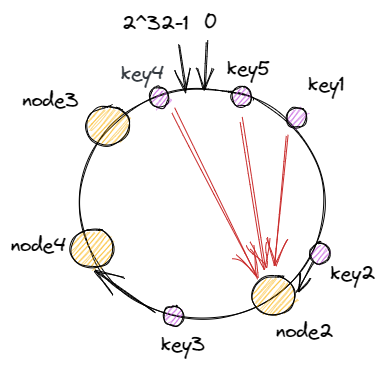
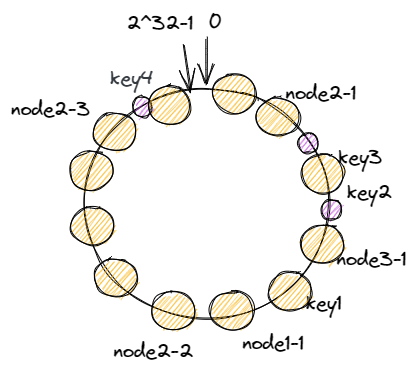
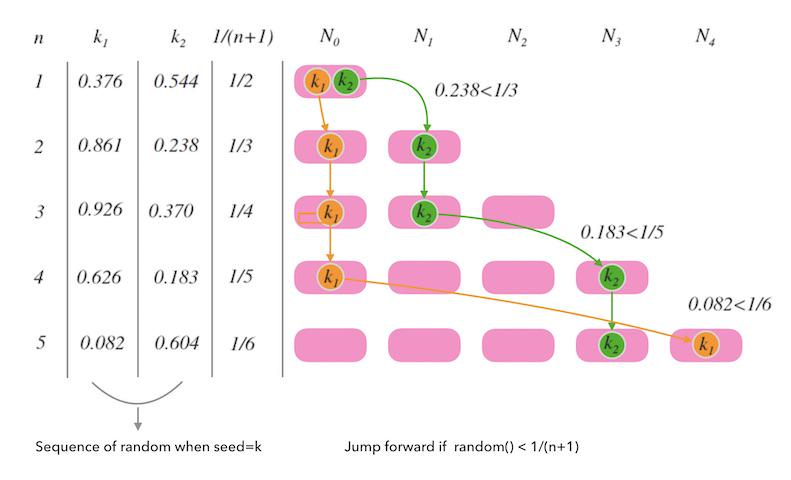
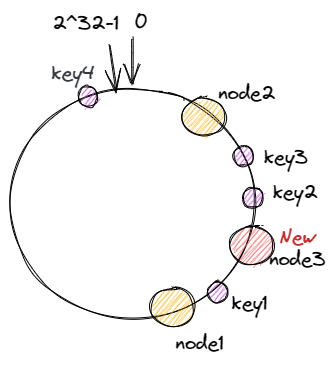
对每一个机器节点计算多个哈希值,在每个计算结果的位置上都放置一个虚拟节点,并将虚拟节点映射到实际节点中,如可以在主机名后增加编号,分别计算 node2-1,node2-2,node2-3…node2-x 的哈希值,为 node2 节点形成了 x 个虚拟节点,如此为所有真实节点都计算 x 个虚拟节点,再分布到哈希环上,这样节点的分布就会显得比较均匀。当然,节点越多分布的会越均匀,此外,使用虚拟节点还可以降低节点之间的负载差异。
intch(int k, int n) { random.seed(k); int b = 0; // This will track ch(k, j+1). for (int j = 1; j < n; j++) { if (random.next() < 1.0/(j+1)) b = j; } return b; }
funcinit() { pool = &sync.Pool{ New: func()interface{} { fmt.Println("creating a new person") returnnew(Person) }, } }
funcmain() { person := pool.Get().(*Person) fmt.Println("Get Pool Object:", person) person.Name = "first" pool.Put(person)
fmt.Println("Get Pool Object:", pool.Get().(*Person)) fmt.Println("Get Pool Object:", pool.Get().(*Person)) }
输出结果如下
1 2 3 4 5
creating a new person Get Pool Object: &{} Get Pool Object: &{first} creating a new person Get Pool Object: &{}
在以上代码中,init()创建了一个 sync.Pool,实现的New()方法为创建一个 person 对象,并打印一句话,main()中调用了三次 Get() 和一次 Put。根据输出结果看来,如果在调用Get()时,pool 中没有对象,那么就会调用New()创建新的对象,否则会从 pool 中的对象获取。我们还可以看到,put 到 pool 中的对象属性依然是之前设定的,并没有被重置。
sync.Pool 广泛运用于各种场景,典型例子是 fmt 包中的 print:
sync.Pool 的底层实现
1 2 3 4 5 6 7 8 9 10 11 12
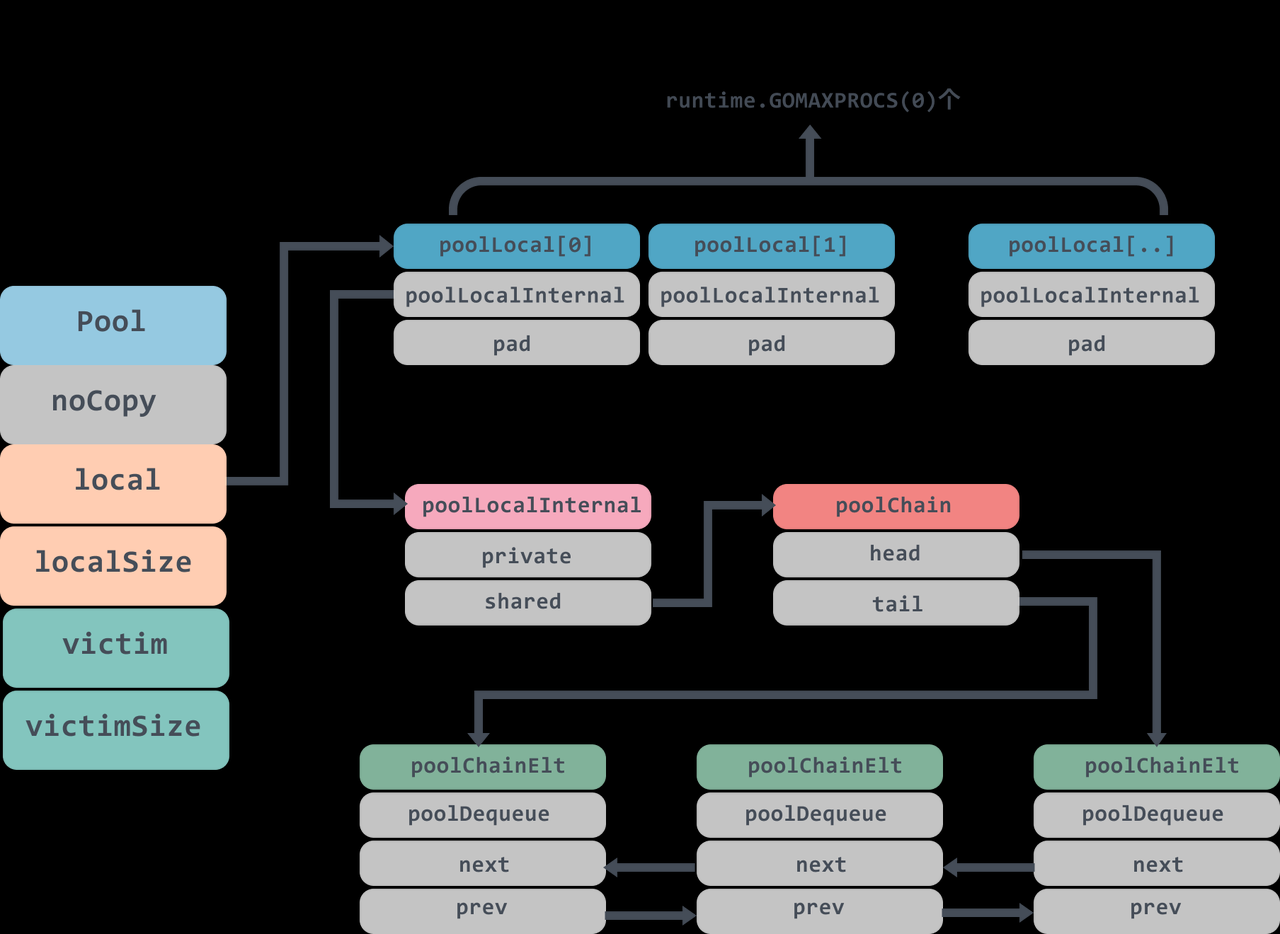
type Pool struct { // go1.7引入的一个静态检查机制,代表该对象不希望被复制,可以使用go vet工具检测到是否被复制 // 在使用时需要实现noCopy保证一个对象第一次使用后不会发生复制 noCopy noCopy local unsafe.Pointer // 每个P的本地队列,实际类型为[P]poolLocal, 一个切片 localSize uintptr// 大小 victim unsafe.Pointer // local from previous cycle victimSize uintptr// size of victims array // 自定义创建对象回调函数,当pool中没有可用对象时会调用此函数 // 当没有可用对象时,如果不设置该函数,get()会返回nil New func() any }
New 函数在创建 pool 时设置,当 pool 中没有缓存对象时,会调用 New 方法生成一个新的对象。
在索引 poolLocal 时,P 的 id 对应[P]poolLocal 下标索引,这样在多个 goroutine 使用同一个 pool 时能减少竞争,提升了性能。在一轮 GC 到来时,victim 和 victimSize 会分别接管 local 和 localSize,victim 机制用于减少 GC 后冷启动导致的性能抖动,使得分配对象更加平滑
Victim Cache 是计算机架构里的一个概念,是 CPU 硬件处理缓存的一种技术,sync.Pool 引入它的目的在于降低 GC 压力的同时提高命中率。
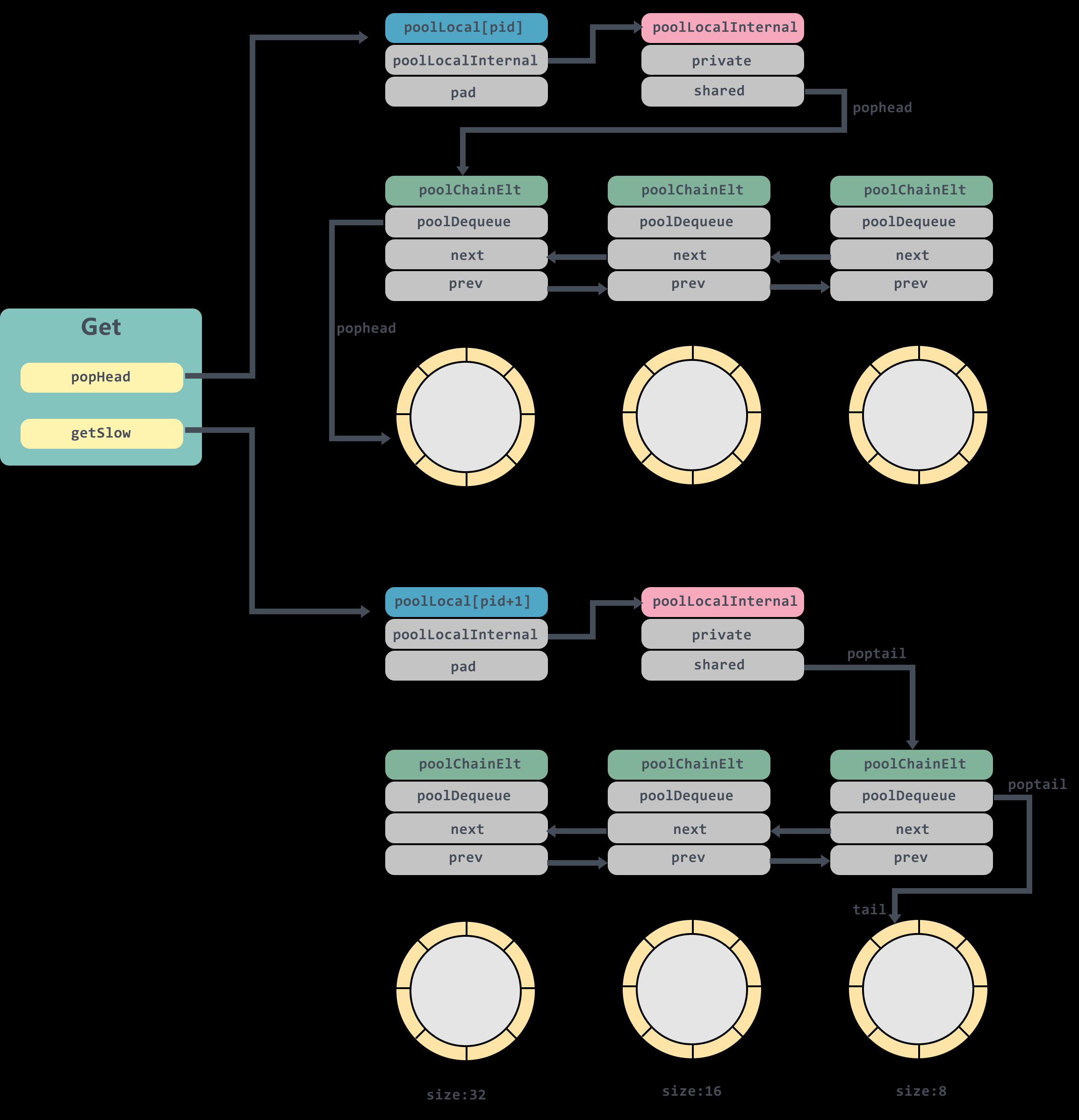
poolLocal
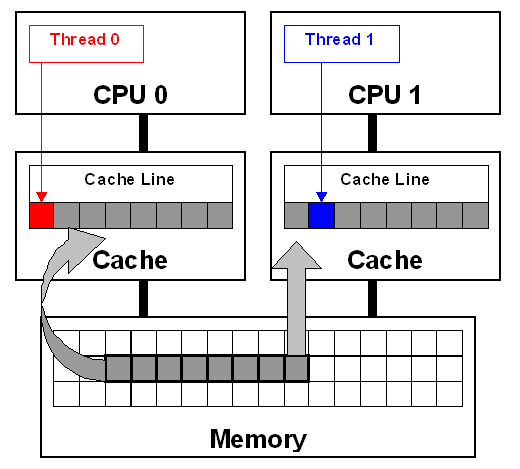
这里得提到伪共享问题。伪共享问题,就是在多核 CPU 架构下,为了满足数据一致性维护一致性协议 MESI,频繁刷新同一 cache line 导致高速缓存并未起到应有的作用的问题。试想一下,两个独立线程要更新两个独立变量,但俩独立变量都在同一个 cache line 上,当前 cache line 是 share 状态。如果 core0 的 thread0 去更新 cache line,会导致 core1 中的 cache line 状态变为 Invalid,随后 thread1 去更新时必须通知 core0 将 cache line 刷回主存,然后它再从主从中 load 该 cache line 进高速缓存之后再进行修改,但是该修改又会使得 core0 的 cache line 失效,重复上述过程,导致高速缓存相当于没有一样,反而还因为频繁更新 cache 影响了性能。
这里 poolLocal 的字段 pad 就是用于防止伪共享问题,cache line 在 x86_64 体系下一般是 64 字节
1 2 3 4 5 6 7
type poolLocal struct { poolLocalInternal // 将poolLocal补齐至缓存行的大小,防止false sharing(伪共享) // 在多数平台上128 mod (cache line size) = 0可以防止伪共享 // 伪共享,仅占位用,防止在cache line上分配多个poolLocalInternal pad [128 - unsafe.Sizeof(poolLocalInternal{})%128]byte }
poolLocal 数组的大小是程序中 P 的数量,Pool 的最大个数是runtime.GOMAXPROCS(0)。
1 2 3 4 5 6 7
// Local per-P Pool appendix. type poolLocalInternal struct { // P的私有缓存区,使用时不需要加锁 private any // Can be used only by the respective P. // 公共缓存区,本地P可用pushHead/popHead。其他的P只能popTail shared poolChain // Local P can pushHead/popHead; any P can popTail. }
poolLocalInternal 中 private 代表缓存了一个元素,只能由相应的一个 P 存取。因为一个 P 同时只能执行一个 goroutine,因此不会有并发问题,使用时不需要加锁。
shared 则可以由任意的 P 访问,但是只有本地的 P 才能 pushHead 或 popHead,其他 P 可以 popTail。
poolChain
看看 poolChain 的实现,这是一个双端队列的实现
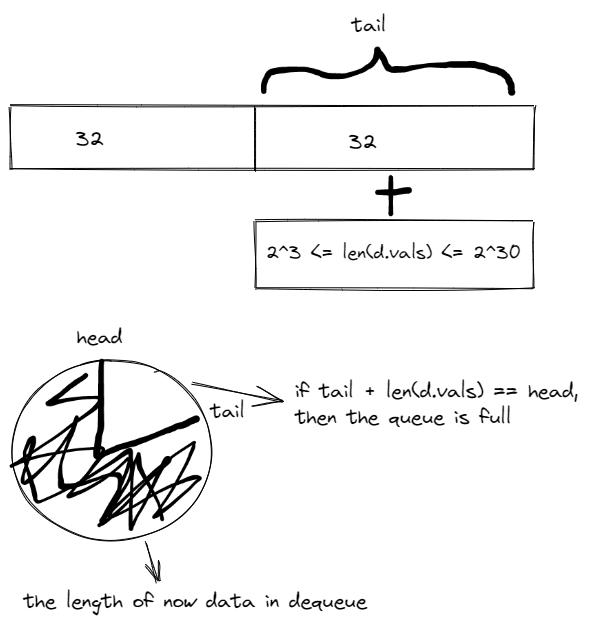
其中 poolDequeue 是 PoolQueue 的一个实现,实现为单生产者多消费者的固定大小的无锁 Ring 式队列,通过 atomic 实现,底层存储用数组,head,tail 标记。
生产者可以从 head 插入,tail 删除,而消费者只能从 tail 删除。headTail 变量通过位运算存储了 head 和 tail 的指针,分别指向队头与队尾。
poolChain 没有使用完整的 poolDequeue,而是封装了一层,这是因为它的大小是固定长度的,而 pool 则是不限制大小的。
func(p *Pool) pinSlow() (*poolLocal, int) { // 解除绑定 // 避免上大锁造成阻塞,浪费资源 runtime_procUnpin() // 加全局锁 allPoolsMu.Lock() defer allPoolsMu.Unlock() // 重新绑定 pid := runtime_procPin() // 已经加了全局锁,此时不需要再用原子操作 s := p.localSize l := p.local // 对pid重新检查,因为pinSlow途中可能已经被其他线程调用了 // 如果已经创建过了,那么直接返回即可 ifuintptr(pid) < s { return indexLocal(l, pid), pid } // 初始化时会将pool放到allPools中 if p.local == nil { allPools = append(allPools, p) } // 当前P数量 // If GOMAXPROCS changes between GCs, we re-allocate the array and lose the old one. size := runtime.GOMAXPROCS(0) local := make([]poolLocal, size) // 回收旧的local atomic.StorePointer(&p.local, unsafe.Pointer(&local[0])) // store-release runtime_StoreReluintptr(&p.localSize, uintptr(size)) // store-release return &local[pid], pid }
pinSlow()在加锁的情况下进行重试,加全局锁创建一个 poolLocal。整体过程如下:
popHead()
1 2 3 4 5 6 7 8 9 10 11 12
func(c *poolChain) popHead() (any, bool) { d := c.head for d != nil { if val, ok := d.popHead(); ok { // 如果成功获得值,则返回 return val, ok } // 继续尝试获取缓存的对象 d = loadPoolChainElt(&d.prev) } returnnil, false }
func(p *Pool) getSlow(pid int) any { // See the comment in pin regarding ordering of the loads. size := runtime_LoadAcquintptr(&p.localSize) // load-acquire locals := p.local // load-consume // 尝试从其他P偷取对象 for i := 0; i < int(size); i++ { // 从索引pid+1处开始投 l := indexLocal(locals, (pid+i+1)%int(size)) if x, _ := l.shared.popTail(); x != nil { return x } } // 在尝试从其他P偷取对象失败后,会尝试从victim cache中取对象 // 这样可以使得victim中的对象更容易被回收 size = atomic.LoadUintptr(&p.victimSize) ifuintptr(pid) >= size { returnnil } locals = p.victim l := indexLocal(locals, pid) if x := l.private; x != nil { l.private = nil return x } for i := 0; i < int(size); i++ { l := indexLocal(locals, (pid+i)%int(size)) if x, _ := l.shared.popTail(); x != nil { return x } } // 清空victim,防止后来人再来这里找 atomic.StoreUintptr(&p.victimSize, 0) returnnil }
func(d *poolDequeue) popTail() (any, bool) { var slot *eface for { ptrs := atomic.LoadUint64(&d.headTail) head, tail := d.unpack(ptrs) if tail == head { returnnil, false } ptrs2 := d.pack(head, tail+1) if atomic.CompareAndSwapUint64(&d.headTail, ptrs, ptrs2) { slot = &d.vals[tail&uint32(len(d.vals)-1)] break } } val := *(*any)(unsafe.Pointer(slot)) if val == dequeueNil(nil) { val = nil } slot.val = nil atomic.StorePointer(&slot.typ, nil) return val, true }
存放一个对象-Put()
Put()将对象添加到 Pool 中,主要过程如下:
绑定当前 goroutine 与 P,然后尝试将 x 赋值给 private
如果失败,则将其放入 local shared 的头部
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
func(p *Pool) Put(x any) { if x == nil { return } ... l, _ := p.pin() if l.private == nil { l.private = x x = nil } if x != nil { l.shared.pushHead(x) } runtime_procUnpin() }
pushHead()
如果头节点为空,则初始化一下,默认大小为 8。然后调用poolDequeue.pushHead()将其 push 到队列中,如果失败,则说明队列已满,会创建一个两倍大小的 dequeue,然后再次调用poolDequeue.pushHead()。由于前面 g 与 p 已经绑定了,所以不会有竞态条件,这里只需要一次重试就行了。
每个 g 去获取锁的时候都会尝试自旋几次,如果没有获取到则进入等待队列尾部(先入先出FIFO)。当持有锁的 g 释放锁时,位于等待队列头部的 g 会被唤醒,但是需要与后来 g 竞争,当然竞争不过,因为后来 g 运行在 cpu 上处于自旋状态,且后来 g 会有很多,而刚唤醒的 g 只有一个,只能被迫重新插回头部。当等待的 g 本次加锁等待时间超过 1ms 都没有获得锁时,它会将当前 Mutex 从正常模式切换为饥饿模式,Mutex 所有权会直接从释放锁的 g 上直接传给队头的 g,后来者不自旋也不会尝试获取锁,会直接进入等待队列尾部。
当发生以下两种情况时 Mutex 会从饥饿模式切换为正常模式
获取到锁的 g 刚来,等待时间小于 1ms
该 g 是等待队列中最后一个 g
饥饿模式下不再尝试自旋,所有 g 都要排队,严格先来后到,可以防止尾端延迟
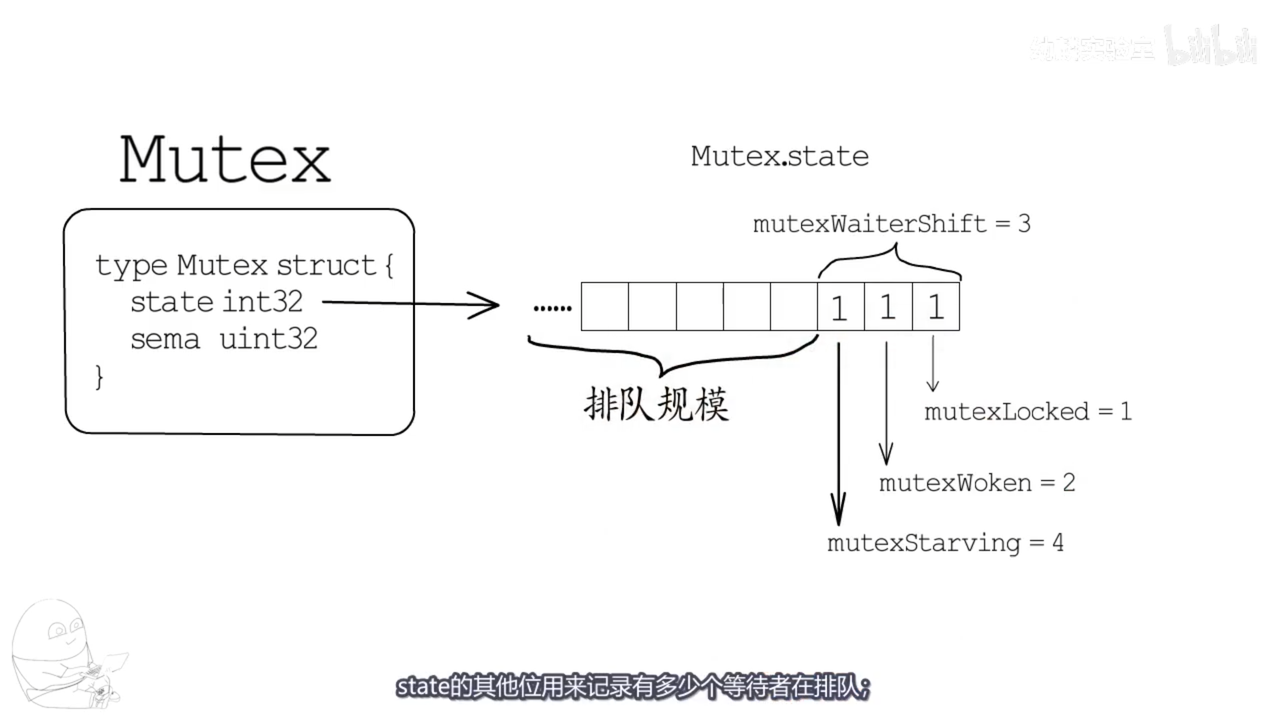
互斥锁 state 的最低三位分别标识mutexLocked、mutexWoken和mutexStarving,剩余位置用于标识当前有多少个 g 在等待互斥锁释放
mutexLocked — 表示互斥锁的锁定状态;
mutexWoken — 表示从正常模式被唤醒;
mutexStarving — 当前的互斥锁进入饥饿状态;
waitersCount — 当前互斥锁上等待的 Goroutine 个数;
1 2 3 4 5 6 7 8 9 10
// A Mutex is a mutual exclusion lock. // The zero value for a Mutex is an unlocked mutex. // // A Mutex must not be copied after first use. type Mutex struct { // 状态 state int32 // 信号量 sema uint32 }
看看 lock 与 unlock。lock 会锁住 Mutex,如果这个锁在被使用,那么调用的 g 会被阻塞直到这个互斥锁被释放。当锁 state 为 0 时,会将 mutexLocked 位置置为 1,当 state 不是 0 时,会调用sync.Mutex.lockSlow()尝试通过自旋等方式来等待锁的释放。
自旋是一种多线程同步机制,当前进程在进入自旋的过程中会一直保持对 CPU 的占用,持续检查某个条件是否为真,在多核 CPU 上,自旋可以避免 goroutine 的切换,某些情况下能对显著提升性能。g 在进入自旋的需要满足的条件如下
互斥锁只有在普通模式才能进入自旋
runtime.sync_runtime_canSpin()返回 true
在多 CPU 机器上
当前 g 为了获取该锁进入自旋次数少于 4 次
GOMAXPROCS > 1,至少一个其他 P 在 running,且当前 p 本地 runq 为空
func(m *Mutex) Lock() { // Fast path: grab unlocked mutex. // 争锁,实现fast path if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) { ... race检测相关 return } // 便于编译器对fast path进行内联优化 // Slow path (outlined so that the fast path can be inlined) m.lockSlow() }
// Active spinning for sync.Mutex. //go:linkname sync_runtime_canSpin sync.runtime_canSpin //go:nosplit funcsync_runtime_canSpin(i int)bool { // sync.Mutex is cooperative, so we are conservative with spinning. // Spin only few times and only if running on a multicore machine and // GOMAXPROCS>1 and there is at least one other running P and local runq is empty. // As opposed to runtime mutex we don't do passive spinning here, // because there can be work on global runq or on other Ps. if i >= active_spin || ncpu <= 1 || gomaxprocs <= int32(sched.npidle+sched.nmspinning)+1 { returnfalse } if p := getg().m.p.ptr(); !runqempty(p) { returnfalse } returntrue }
func(m *Mutex) Unlock() { ...race检测相关 // Fast path: drop lock bit. new := atomic.AddInt32(&m.state, -mutexLocked) ifnew != 0 { // 等待队列有g在排队 m.unlockSlow(new) } }
func(m *Mutex) unlockSlow(newint32) { // 先判断是否已经被解锁 if (new+mutexLocked)&mutexLocked == 0 { throw("sync: unlock of unlocked mutex") } // 如果是正常模式 ifnew&mutexStarving == 0 { old := new for { // 如果等待队列为空,或者一个g已经被唤醒或抢到了锁,则不需要唤醒任何g if old>>mutexWaiterShift == 0 || old&(mutexLocked|mutexWoken|mutexStarving) != 0 { return } // 获取唤醒某个g的机会 new = (old - 1<<mutexWaiterShift) | mutexWoken if atomic.CompareAndSwapInt32(&m.state, old, new) { runtime_Semrelease(&m.sema, false, 1) return } old = m.state } } else { // 饥饿模式:将互斥锁的所有权直接移交给等待队列头的g,并让出时间片,以便于它可以立即开始运行 // mutexLocked没有设置1,在等待队列头的g被唤醒后才设置 // 如果设置了饥饿模式,mutex仍然是被认定为锁定的, 这样才能让新的g不会获取它 runtime_Semrelease(&m.sema, true, 1) } }
Mutex 的实现原理总结
Mutex 底层是 CAS 实现的,内部维护了一个 int32 的状态 state,用于标识锁状态,以及一个 uint32 的信号量 sema 用于挂起和阻塞 goroutine。Mutex 分为正常模式和饥饿模式,不同模式下Lock()和UnLock()的对加锁、解锁处理方式不同。Mutex 中的 state 第 4 位及其高位用于存放等待计数,低三位的第一位表示锁状态,第二位表示从正常模式被唤醒,第三位表示进入饥饿模式。
Lock() 先通过 CAS 置 state 为 1,如果失败,则进入 slow path 处理:
先判断是否可以自旋,饥饿模式下无法自旋
如果是正常模式,且可以自旋(运行在多 CPU 机器上、当前 g 为了争取该锁进入自旋的次数少于 4、当前机器上至少有个正在运行的 P 且 runq 为空),尝试进行自旋准备:通知运行的 goroutine 不要唤醒其他挂起的 gorotuine,解锁时直接让当前 g 获取锁即可。然后调用runtime_doSpin()进入自旋,执行 30 次 PAUSE 指令占用 CPU,递增自旋次数,重新计算状态
计算锁状态
使用 CAS 更新状态
成功获取锁:返回
判断等待时间是否为 0,如果是 0 则放在队尾,如果非 0 则放在头部,进入阻塞
唤醒
锁是否要进入饥饿状态:等待时间超过 1ms
重新获取锁状态
判断是否处于饥饿状态
是则可以直接获取锁:自减等待计数,设置状态获取锁,如果 starving 不为饥饿,或等待时间没有超过 1ms,或者只有一个 g 在等待队列中,满足任一条件则切换为正常状态
Lock 中,先获取内置的互斥锁,获取成功后,其余竞争者 g 会陷入自旋或阻塞。atomic.AddInt32用于阻塞后续的读操作,如果仍有活跃的读操作 g,那么当前写操作 g 会调用 runtime.SemacquireMutex 进入休眠状态等待全部读锁持有者结束后释放 writerSem 信号量,将当前 g 唤醒
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
// Lock locks rw for writing. // If the lock is already locked for reading or writing, // Lock blocks until the lock is available. func(rw *RWMutex) Lock() { // ...省略race检测 // 首先解决与其他写操作的竞争 rw.w.Lock() // 通知读操作者,这是一个写操作 r := atomic.AddInt32(&rw.readerCount, -rwmutexMaxReaders) + rwmutexMaxReaders // 等待活跃的读操作执行完成 if r != 0 && atomic.AddInt32(&rw.readerWait, r) != 0 { // func runtime_SemacquireMutex(s *uint32, lifo bool, skipframes int) // SemacquireMutex 类似于 Semacquire,但用于分析争用的互斥体。如果 lifo 为真,则在等待队列的头部排队等待服务员。 skipframes 是跟踪期间要忽略的帧数,从 runtime_SemacquireMutex 的调用者开始计算。 runtime_SemacquireMutex(&rw.writerSem, false, 0) } // ...省略race检测代码 }
// Unlock unlocks rw for writing. It is a run-time error if rw is // not locked for writing on entry to Unlock. // // As with Mutexes, a locked RWMutex is not associated with a particular // goroutine. One goroutine may RLock (Lock) a RWMutex and then // arrange for another goroutine to RUnlock (Unlock) it. func(rw *RWMutex) Unlock() { // ...省略race检测相关 // 通知所有读者,没有活跃的写操作了 r := atomic.AddInt32(&rw.readerCount, rwmutexMaxReaders) // 解锁不存在的读锁会throw if r >= rwmutexMaxReaders { race.Enable() throw("sync: Unlock of unlocked RWMutex") } // 唤醒所有阻塞的读操作 for i := 0; i < int(r); i++ { runtime_Semrelease(&rw.readerSem, false, 0) } // 解锁允许其他写操作者抢占 rw.w.Unlock() // ...省略race检测相关 }
RLock 与 RUnlock
读锁的加锁方法不能用于递归读锁定,为不可重入锁,同时,Lock 调用会阻止新的读者获取锁。其中只是将 readerCount+1,如果返回了负数,说明其他 g 获得了写锁,当前 g 就会调用runtime_SemacquireMutex()陷入休眠等待写锁释放。如果返回了正数,则代表 g 没有获取写锁,当前方法返回成功
1 2 3 4 5 6 7 8 9
// RLock locks rw for reading. func(rw *RWMutex) RLock() { // ...省略检测race相关 if atomic.AddInt32(&rw.readerCount, 1) < 0 { // A writer is pending, wamkit for it. runtime_SemacquireMutex(&rw.readerSem, false, 0) } // ...省略检测race相关 }
// RUnlock undoes a single RLock call; // it does not affect other simultaneous readers. // It is a run-time error if rw is not locked for reading // on entry to RUnlock. func(rw *RWMutex) RUnlock() { // ...省略检测race相关 if r := atomic.AddInt32(&rw.readerCount, -1); r < 0 { // Outlined slow-path to allow the fast-path to be inlined rw.rUnlockSlow(r) } // ...省略检测race相关 }
func(rw *RWMutex) rUnlockSlow(r int32) { // 解锁不存在的读锁会throw if r+1 == 0 || r+1 == -rwmutexMaxReaders { race.Enable() throw("sync: RUnlock of unlocked RWMutex") } // A writer is pending. if atomic.AddInt32(&rw.readerWait, -1) == 0 { // The last reader unblocks the writer. runtime_Semrelease(&rw.writerSem, false, 1) } }
$ go vet proc.go./prog.go:10:10: assignment copies lock value to yawg: sync.WaitGroup ./prog.go:11:14: call of fmt.Println copies lock value: sync.WaitGroup ./prog.go:11:18: call of fmt.Println copies lock value: sync.WaitGroupv
semaTable
semaTable 存储了可供 g 使用的信号量,是大小为 251 的数组。每一个元素存储了一个平衡树的根,节点是 sudog 类型,在使用时需要一个记录信号量数值的变量 sema,根据它的地址映射到数组中的某个位置,找到对应的节点就找到对应信号的等待队列。
channel 没有使用信号量,而是自己实现了一套排队逻辑
1 2 3 4 5
type semaRoot struct { lock mutex treap *sudog // root of balanced tree of unique waiters. nwait uint32// Number of waiters. Read w/o the lock. }
sync.Once
sync.once 文件内容很少,只有一个结构体与两个方法,其中 sync.Once 用于保证 go 程序运行期间的某段代码只执行一次,暴露出的 Do 方法用于执行给定的方法
在以下代码中,只会输出一次 only once
1 2 3 4 5 6 7 8
funcmain() { o := &sync.Once{} for i := 0; i < 10; i++ { o.Do(func() { fmt.Println("only once") }) } }
输出结果如下:
1 2
$ go run main.go only once
Once 的结构体也很简单:
1 2 3 4
type Once struct { done uint32// 标识代码块是否执行过done m Mutex // 互斥锁,用于保证原子性操作 }
看看 Do 方法的实现。在源代码的注释中说明了为什么不直接 CAS 设定值,if 方法中调用函数,而要使用这种方式,是因为Do 保证了当它返回时,f 函数已经完成,而直接 CAS 后成功执行不成功返回是无法这样保证的。对于 panic 而言,defer 保证了 panic 也会将 done 置为 1,因此即使 f 调用中 panic,依然算已经执行过。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
// Do 调用函数 f 当且仅当 Do 为这个 Once 的实例第一次被调用时 func(o *Once) Do(f func()) { // fast path,快速判断是否已执行。如果未执行则进入slow path if atomic.LoadUint32(&o.done) == 0 { // Outlined slow-path to allow inlining of the fast-path. o.doSlow(f) } }
funcnotifyListNotifyOne(l *notifyList) { // fast path:如果在上次signal后,没有新的waiter,不需要锁了,直接返回即可 if atomic.Load(&l.wait) == atomic.Load(&l.notify) { return } lockWithRank(&l.lock, lockRankNotifyList) t := l.notify // 在加锁的情况下recheck if t == atomic.Load(&l.wait) { unlock(&l.lock) return } atomic.Store(&l.notify, t+1) // 从头开始找到满足sudog.ticket == l.notify的goroutine,唤醒并返回 for p, s := (*sudog)(nil), l.head; s != nil; p, s = s, s.next { if s.ticket == t { n := s.next if p != nil { p.next = n } else { l.head = n } if n == nil { l.tail = p } unlock(&l.lock) s.next = nil readyWithTime(s, 4) return } } unlock(&l.lock) }
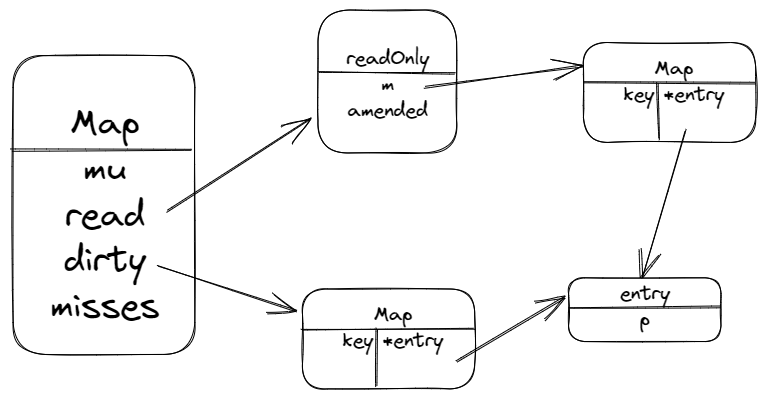
func(m *Map) Store(key, value any) { // 如果read map中存在该key,则尝试直接修改 read, _ := m.read.Load().(readOnly) if e, ok := read.m[key]; ok && e.tryStore(&value) { return }
m.mu.Lock() read, _ = m.read.Load().(readOnly) if e, ok := read.m[key]; ok { if e.unexpungeLocked() { // 如果read map中存在该key,但p为expunged,说明m.dirty不为nil且m.dirty不存在该key // 此时将p的状态修改为nil,并在dirty map中插入key m.dirty[key] = e } // 更新p指向value e.storeLocked(&value) } elseif e, ok := m.dirty[key]; ok { // 如果read中不存在该key,但dirty map中存在该key,直接写入更新entry // 此时read map中仍然没有该key e.storeLocked(&value) } else { // read和dirty中都没有该key // 如果dirty map为nil,需要创建dirty map,并从read map中复制未删除的元素到新创建的dirty map中 // 更新emended字段未true,表示dirty map中存在read map中没有的key // 将key/value写入dirty map if !read.amended { // 添加第一个新key到dirty map中 // 此处先判断dirty map是否为空,若为空,则浅拷贝read map一次 m.dirtyLocked() m.read.Store(readOnly{m: read.m, amended: true}) } m.dirty[key] = newEntry(value) } m.mu.Unlock() }
read, _ := m.read.Load().(readOnly) m.dirty = make(map[any]*entry, len(read.m)) for k, e := range read.m { if !e.tryExpungeLocked() { m.dirty[k] = e } } }
// CAS设置entry,当p为expunged时返回false func(e *entry) tryStore(i *any) bool { for { p := atomic.LoadPointer(&e.p) if p == expunged { returnfalse } if atomic.CompareAndSwapPointer(&e.p, p, unsafe.Pointer(i)) { returntrue } } }
// Delete deletes the value for a key. func(m *Map) Delete(key any) { m.LoadAndDelete(key) }
func(m *Map) LoadAndDelete(key any) (value any, loaded bool) { read, _ := m.read.Load().(readOnly) e, ok := read.m[key] if !ok && read.amended { m.mu.Lock() read, _ = m.read.Load().(readOnly) e, ok = read.m[key] if !ok && read.amended { e, ok = m.dirty[key] delete(m.dirty, key) // 不管是否存在都记一下misses m.missLocked() } m.mu.Unlock() } if ok { return e.delete() } returnnil, false }
entry.delete()也是 CAS 操作,将 p 置为 nil,当判断 p 为 nil 或 expunged 时会直接返回 nil 和 false。
1 2 3 4 5 6 7 8 9 10 11
func(e *entry)delete() (value any, ok bool) { for { p := atomic.LoadPointer(&e.p) if p == nil || p == expunged { returnnil, false } if atomic.CompareAndSwapPointer(&e.p, p, nil) { return *(*any)(p), true } } }
func(m *Map) LoadOrStore(key, value any) (actual any, loaded bool) { // fast path read, _ := m.read.Load().(readOnly) if e, ok := read.m[key]; ok { actual, loaded, ok := e.tryLoadOrStore(value) if ok { return actual, loaded } }
m.mu.Lock() // 与store类似 read, _ = m.read.Load().(readOnly) if e, ok := read.m[key]; ok { if e.unexpungeLocked() { m.dirty[key] = e } actual, loaded, _ = e.tryLoadOrStore(value) } elseif e, ok := m.dirty[key]; ok { actual, loaded, _ = e.tryLoadOrStore(value) m.missLocked() } else { if !read.amended { // We're adding the first new key to the dirty map. // Make sure it is allocated and mark the read-only map as incomplete. m.dirtyLocked() m.read.Store(readOnly{m: read.m, amended: true}) } m.dirty[key] = newEntry(value) actual, loaded = value, false } m.mu.Unlock()
return actual, loaded }
func(e *entry) tryLoadOrStore(i any) (actual any, loaded, ok bool) { p := atomic.LoadPointer(&e.p) if p == expunged { returnnil, false, false } if p != nil { return *(*any)(p), true, true } ic := i for { if atomic.CompareAndSwapPointer(&e.p, nil, unsafe.Pointer(&ic)) { return i, false, true } p = atomic.LoadPointer(&e.p) if p == expunged { returnnil, false, false } if p != nil { return *(*any)(p), true, true } } }
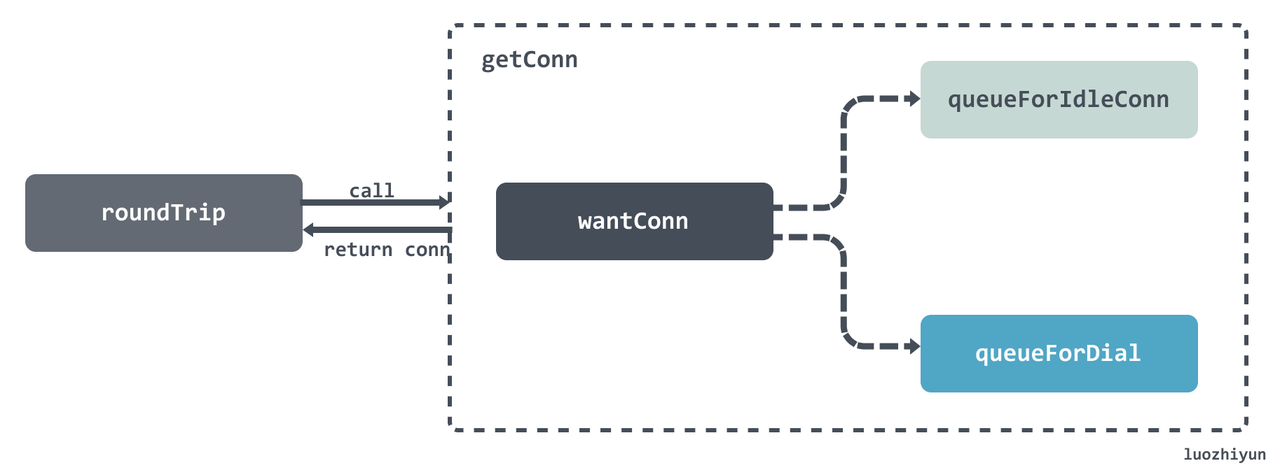
// Queue for idle connection. if delivered := t.queueForIdleConn(w); delivered { pc := w.pc // Trace only for HTTP/1. // HTTP/2 calls trace.GotConn itself. if pc.alt == nil && trace != nil && trace.GotConn != nil { trace.GotConn(pc.gotIdleConnTrace(pc.idleAt)) } // set request canceler to some non-nil function so we // can detect whether it was cleared between now and when // we enter roundTrip t.setReqCanceler(treq.cancelKey, func(error) {}) return pc, nil }
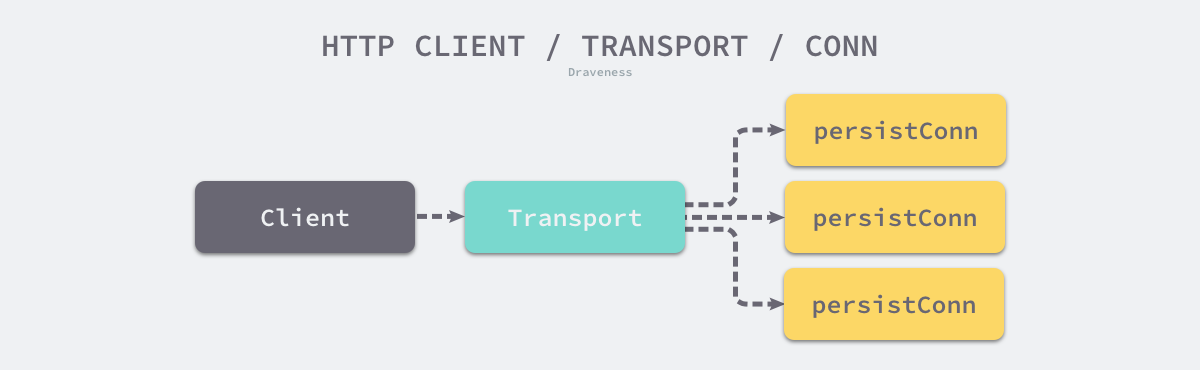
// Deprecated: Use DialContext instead, which allows the transport // to cancel dials as soon as they are no longer needed. // If both are set, DialContext takes priority. Dial func(network, addr string) (net.Conn, error)
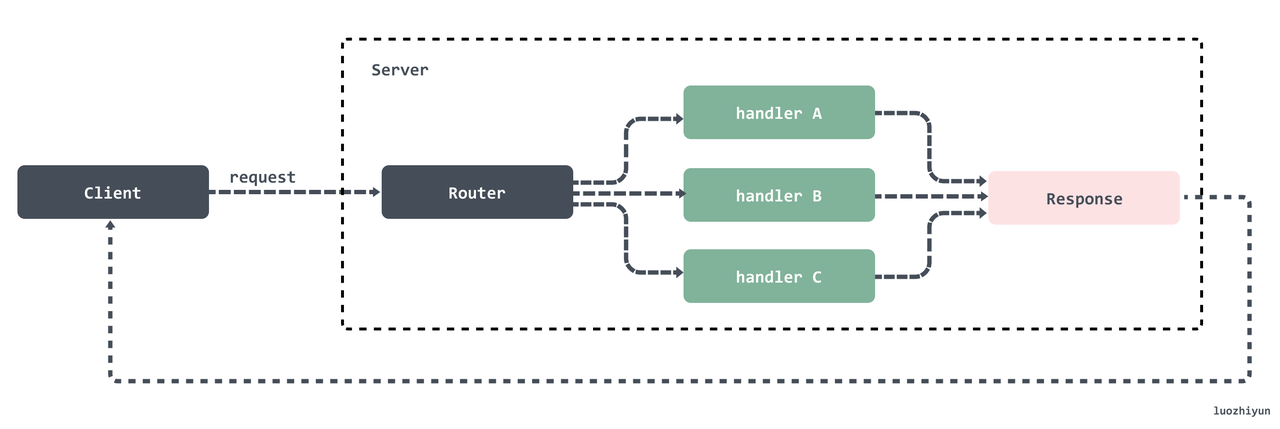
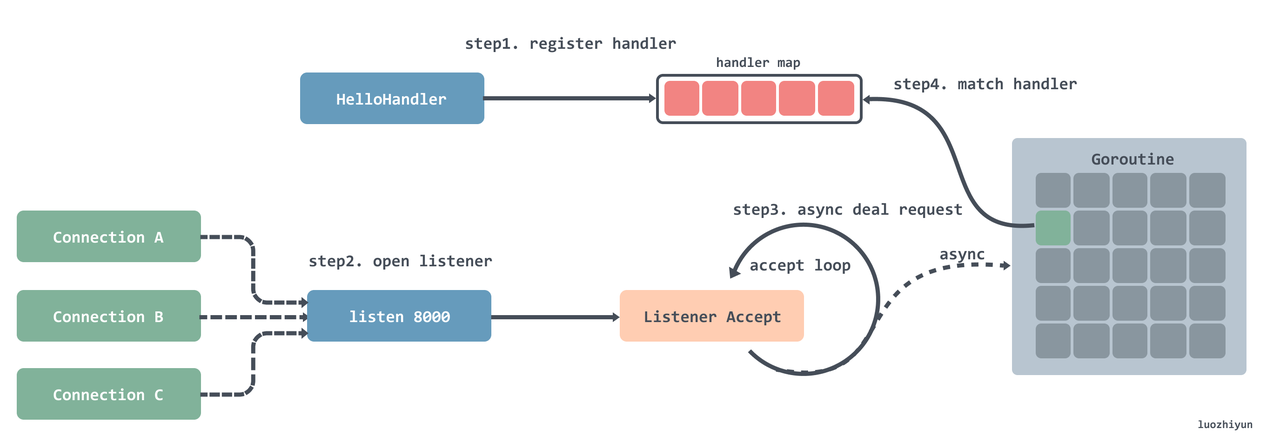
// HandleFunc registers the handler function for the given pattern. func(mux *ServeMux) HandleFunc(pattern string, handler func(ResponseWriter, *Request)) { if handler == nil { panic("http: nil handler") } mux.Handle(pattern, HandlerFunc(handler)) }
funcappendSorted(es []muxEntry, e muxEntry) []muxEntry { n := len(es) i := sort.Search(n, func(i int)bool { returnlen(es[i].pattern) < len(e.pattern) }) if i == n { returnappend(es, e) } // we now know that i points at where we want to insert es = append(es, muxEntry{}) // try to grow the slice in place, any entry works. copy(es[i+1:], es[i:]) // Move shorter entries down es[i] = e return es }
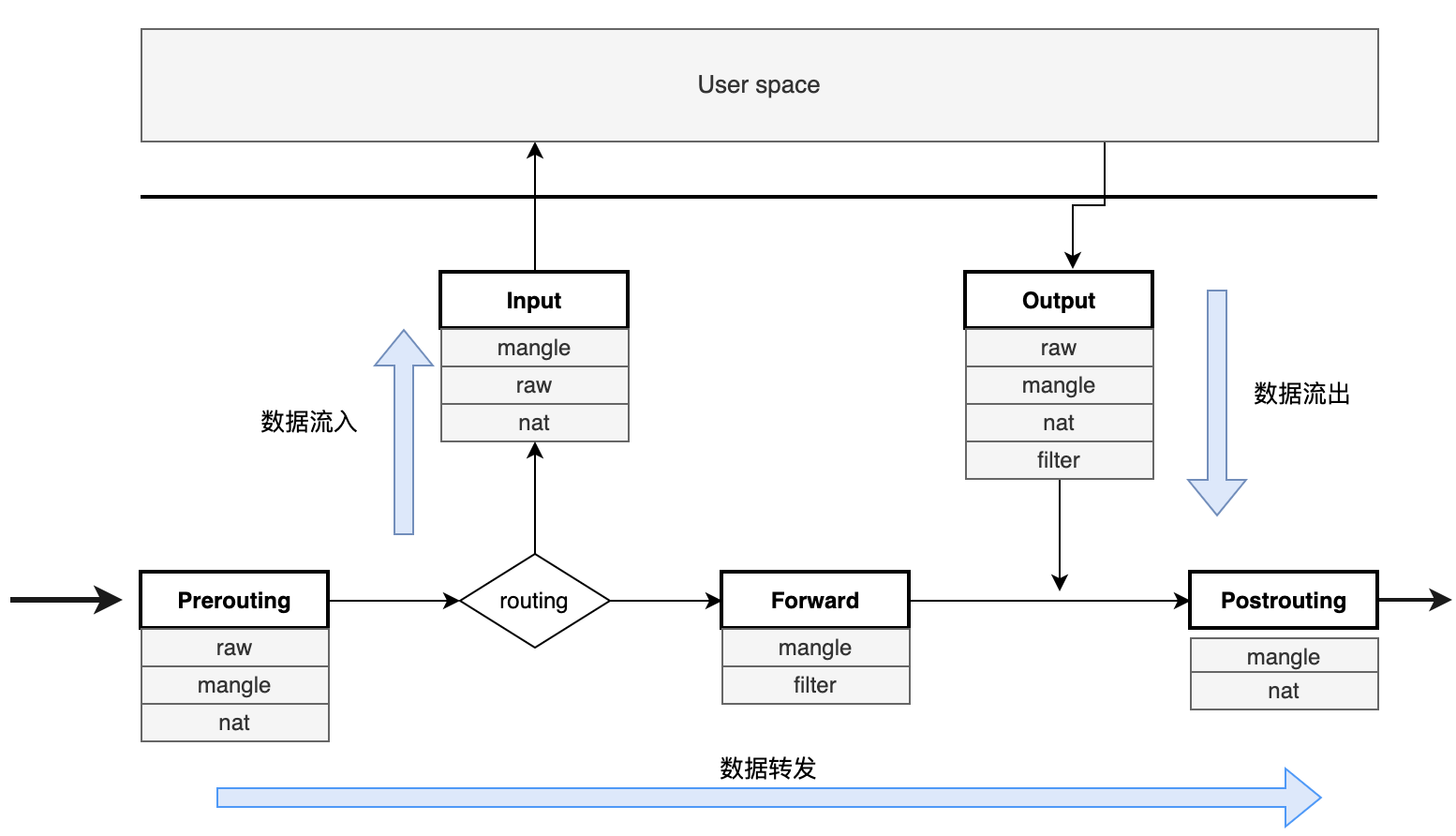
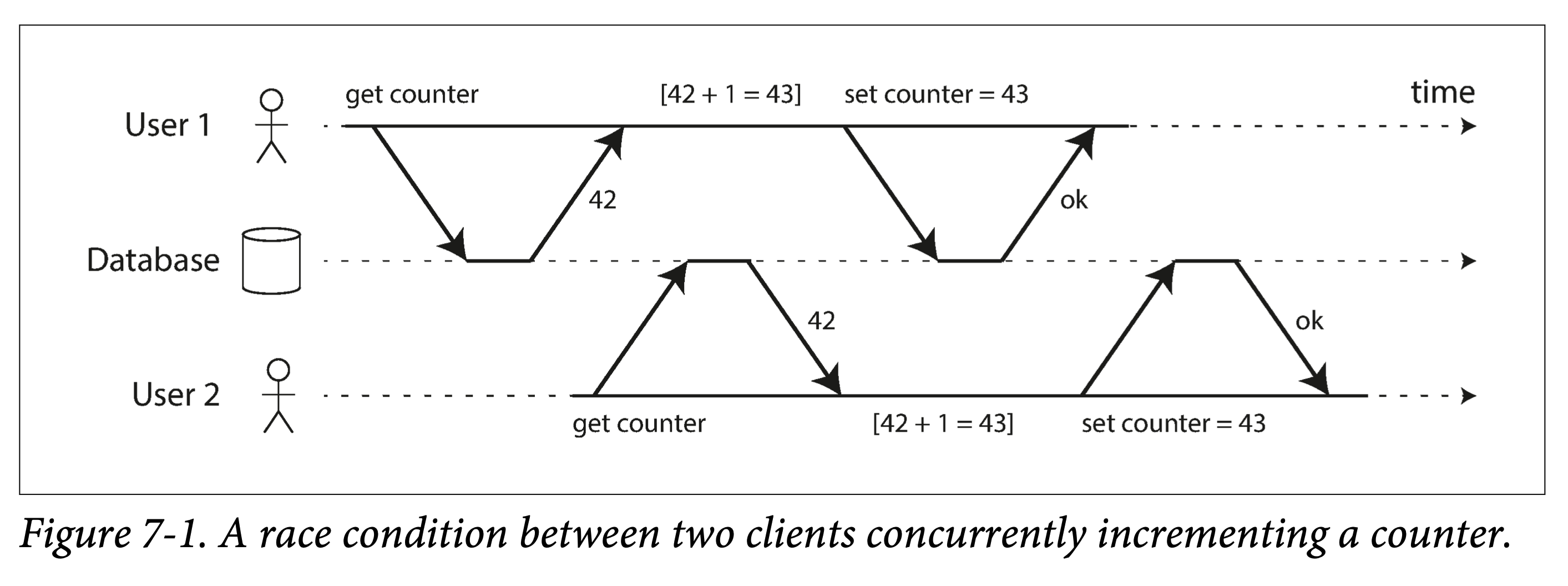
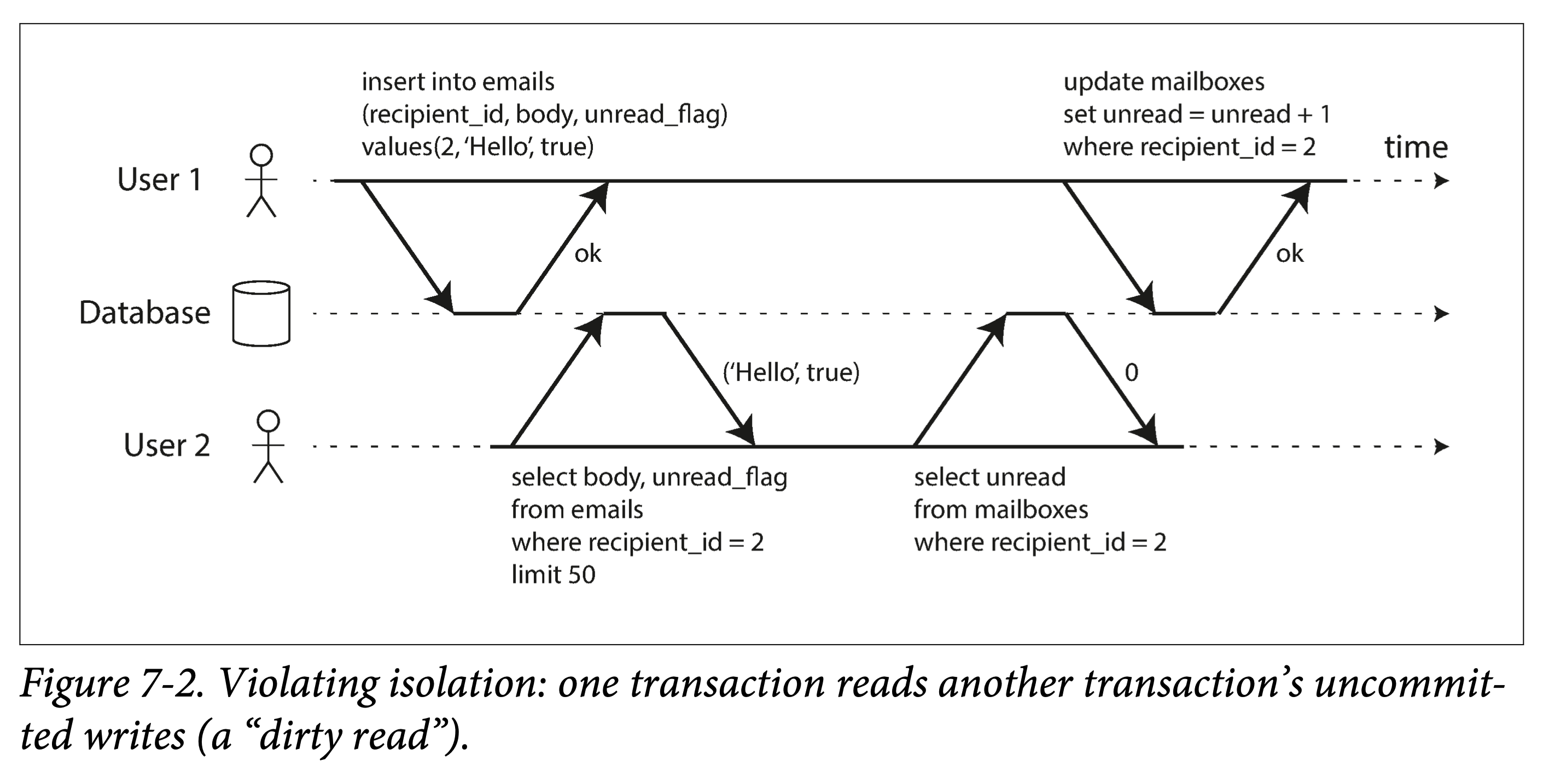
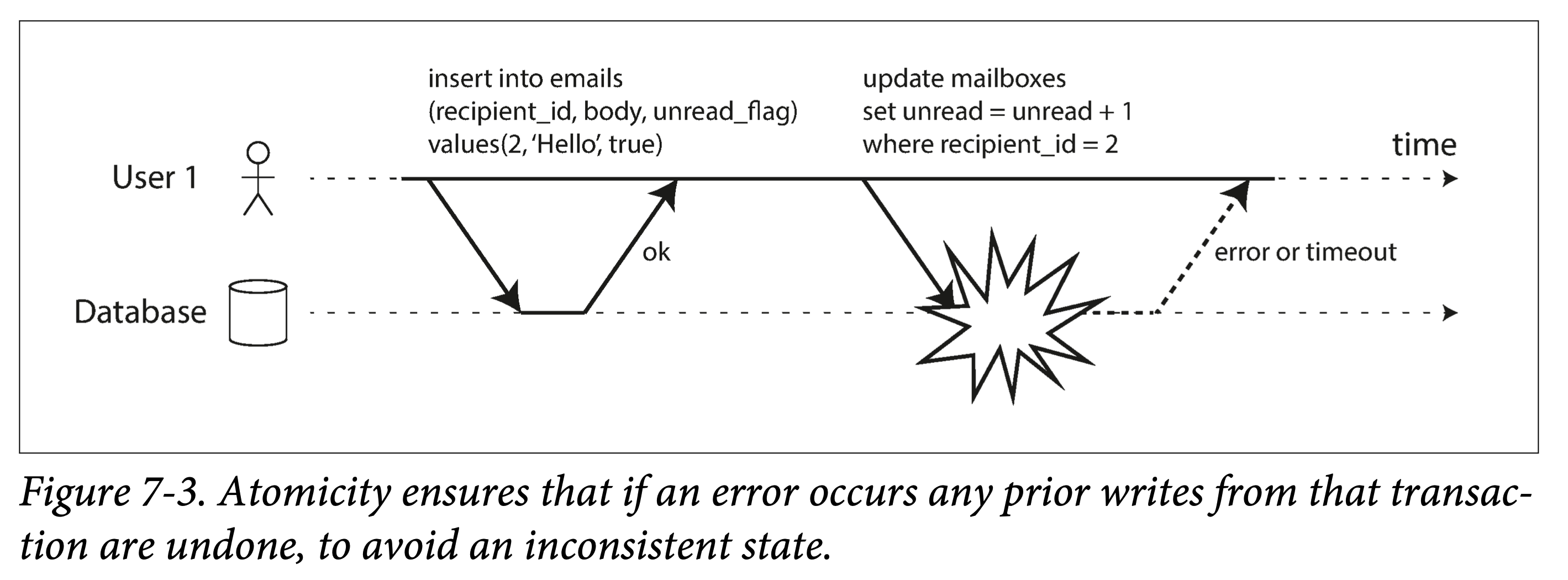
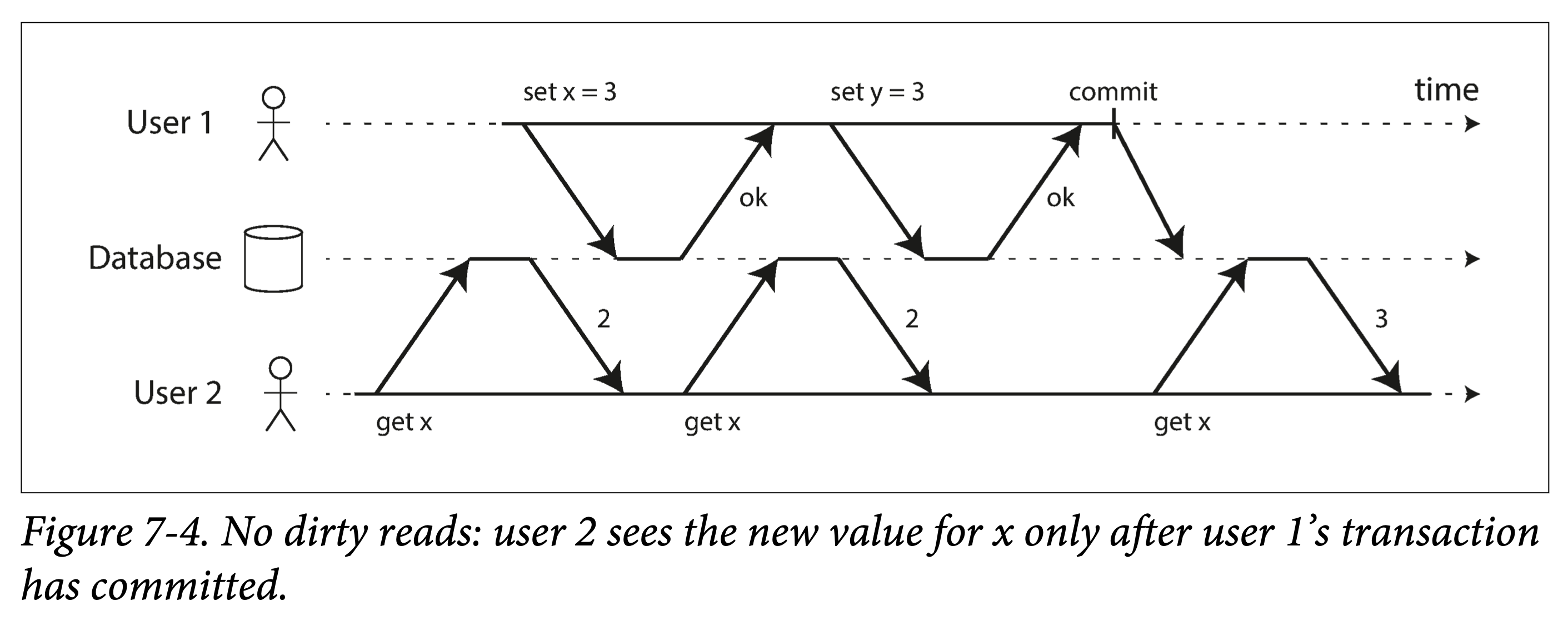
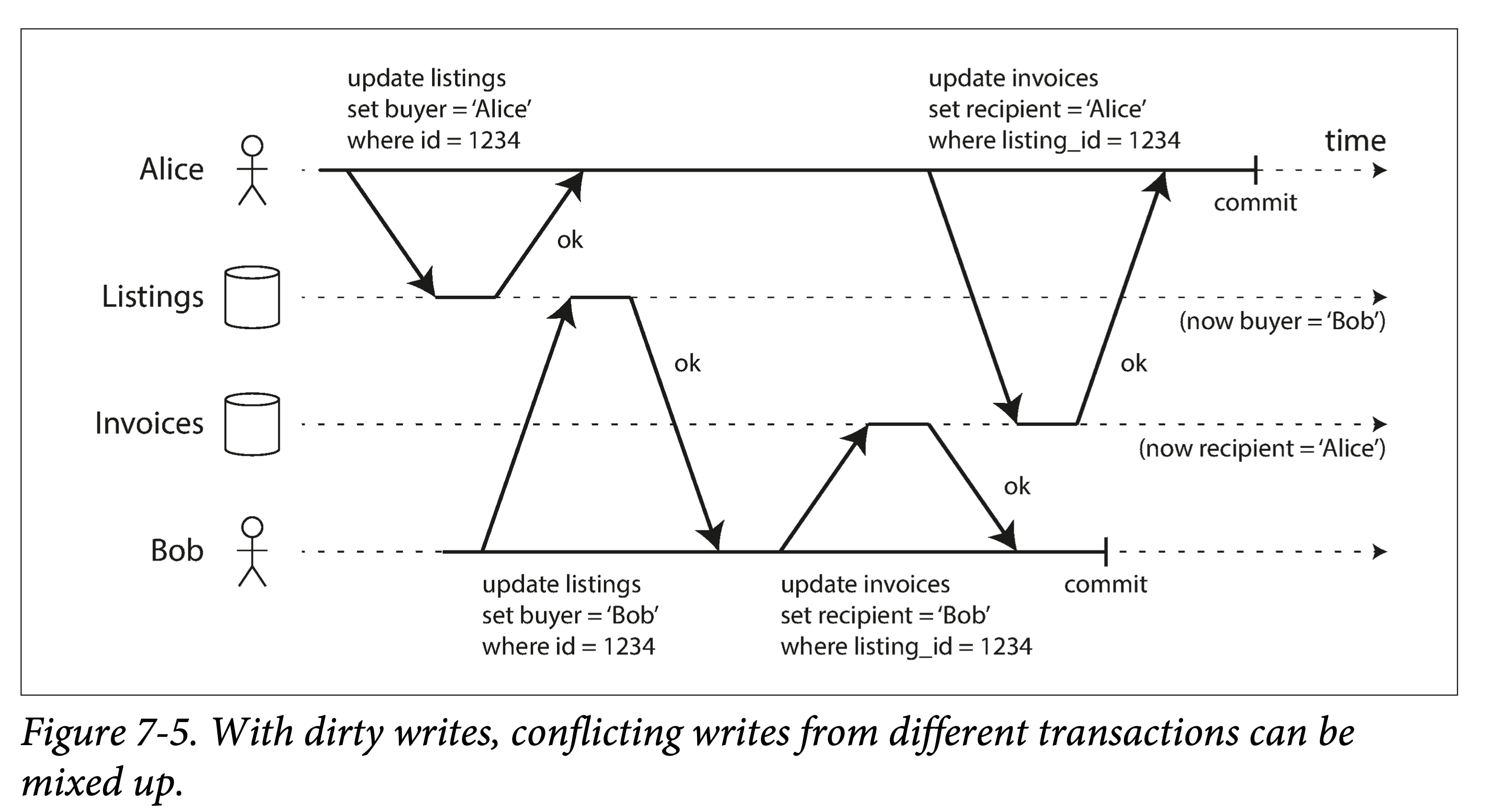
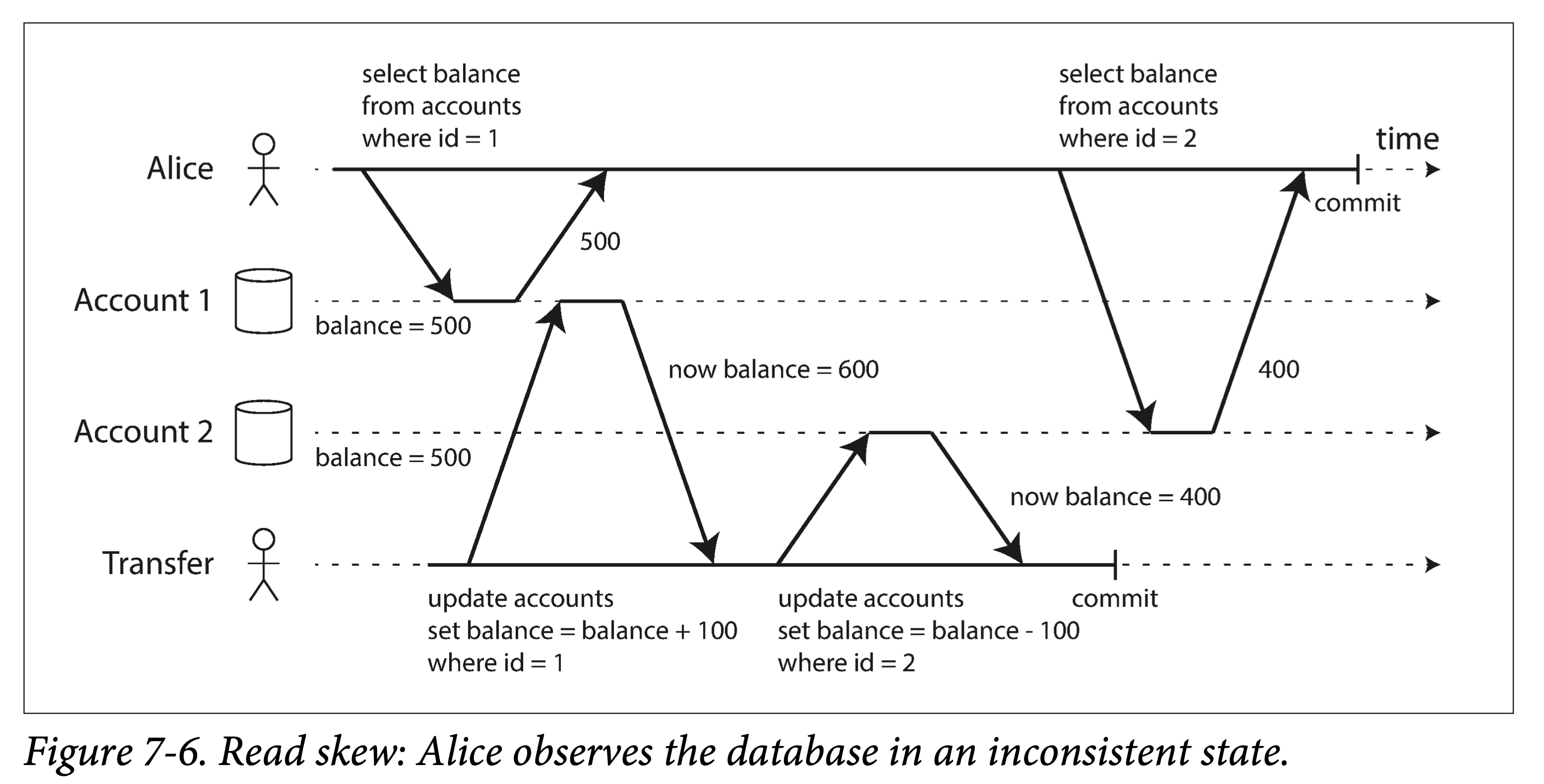
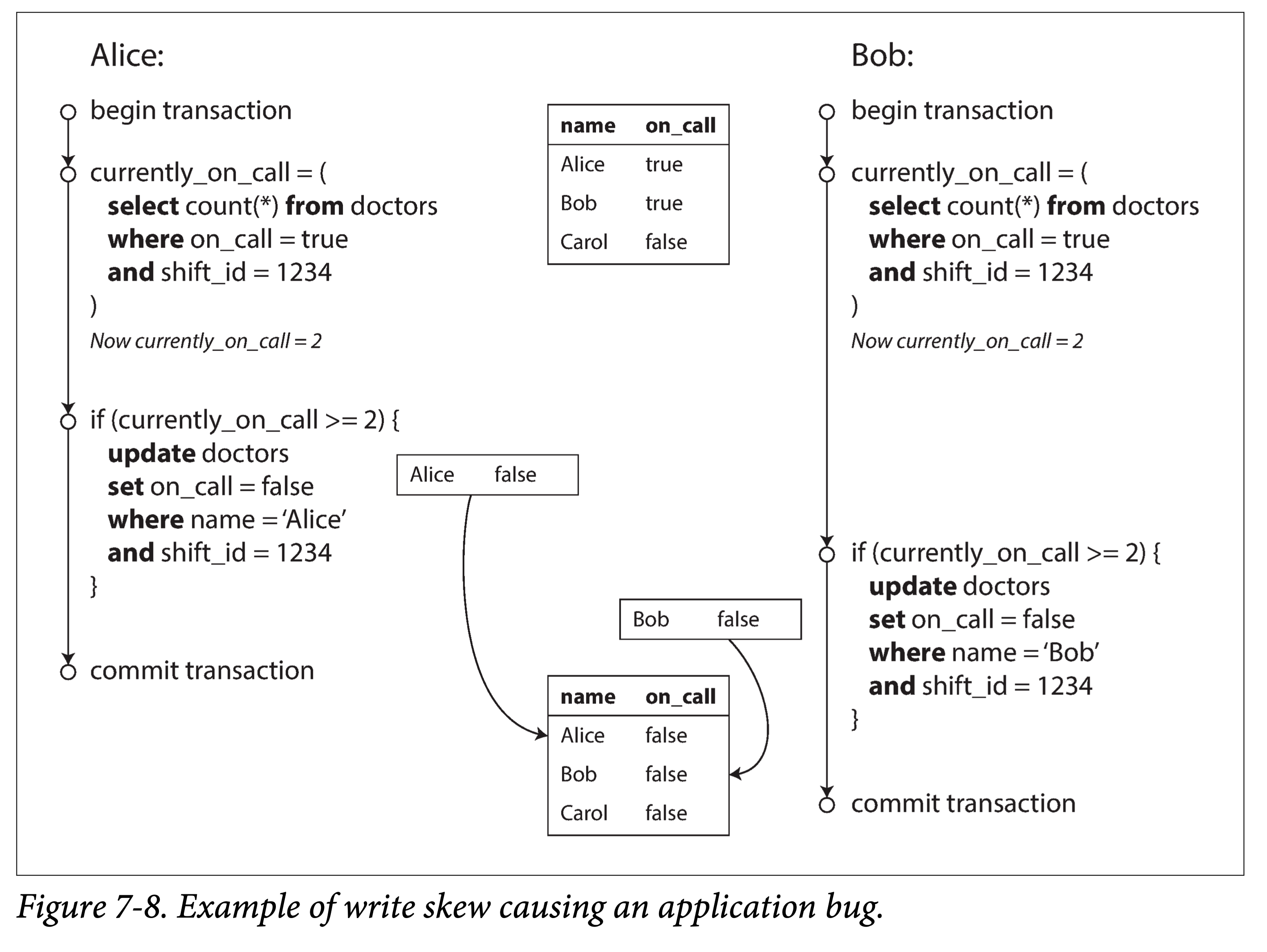
最强隔离性的隔离级别——可串行化,可以理解为一把全局的排它锁,每个事务启动时使用,在提交、回滚或终止时释放,这种隔离级别无疑性能最差。这侧面反映了其它几种弱隔离级别的意义:提高性能,缩小加锁的粒度、减小加锁的时间,从而牺牲一部分事务保证来换取性能。从上锁的强度考虑,有互斥锁(Mutex Lock,也称为写锁)和共享锁(Shared Lock,又称为读锁);从上锁的长短来考虑,有长时锁(Long Period Lock,在事务开始时获取锁,尽管中途需要保证事务的动作已经执行完成,也要到事务结束时才释放锁)和短时锁(Short Period Lock,执行动作前申请锁,执行结束后立即释放锁);从上锁的粗细来考虑,有对象锁(Row Lock,在关系型数据库中描述为锁住一行数据)和谓词锁(Predicate Lock,锁住一个范围内的数据)。
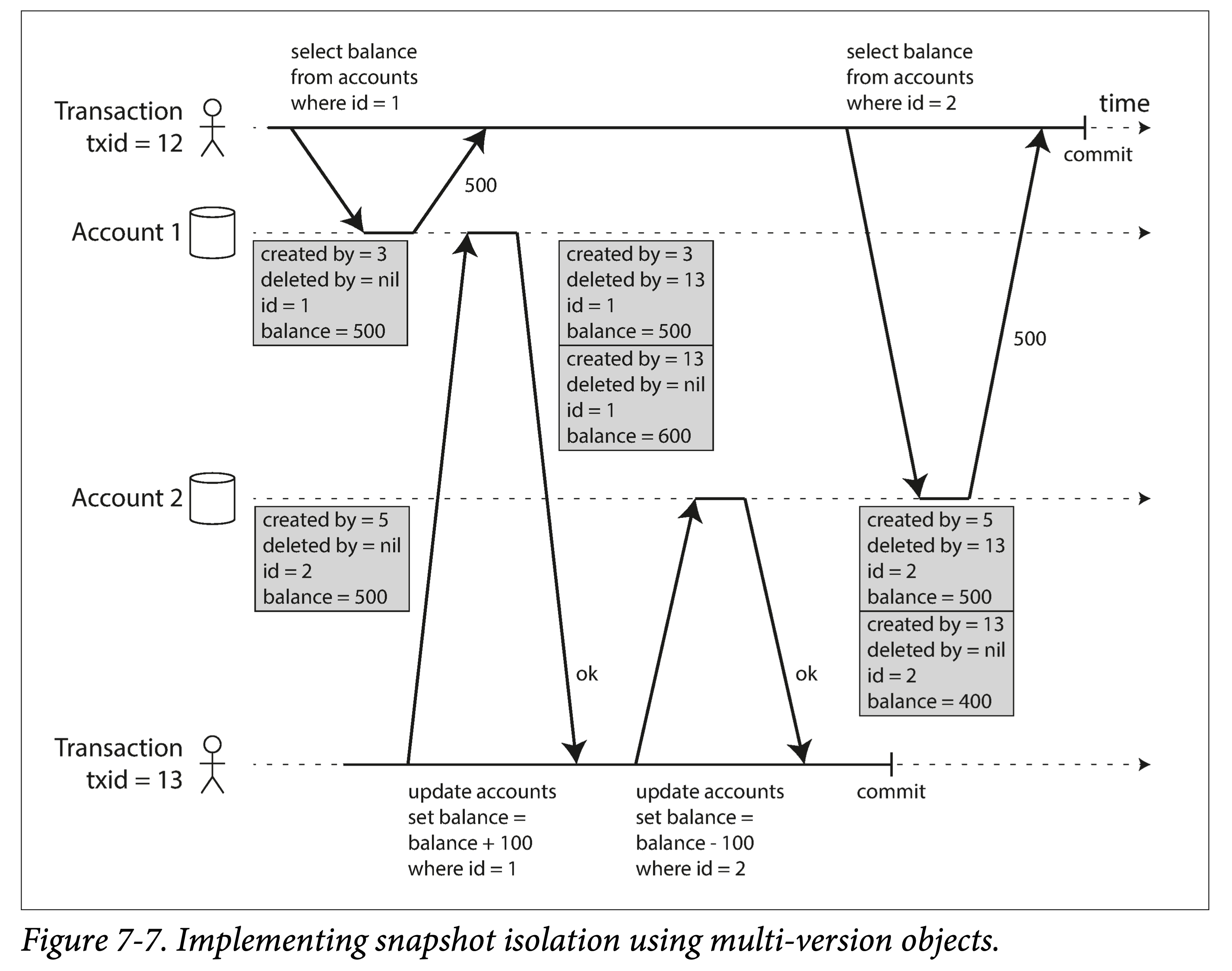
CouchDB、Datomic 和 LMDB 使用的是另一种方式,仅 追加 / 写时拷贝(append-only/copy-on-write) 的 B 树变体,是一种多版本技术的变体。boltdb就是参考的 LMDB,也可以归为此类。此类 B 树每次修改,都会引起叶子节点(所有数据都会落到叶子节点)到根节点的一条路径级联更新(叶子节点变了,其父节点内容——指针,也要跟着修改,因此引起级联更新),如果引起节点的分裂或合并,会引发更大范围的更新和修改。
这种修改不会覆盖旧的页面,每个修改页面都会创建一份副本,更新的节点会指向其子页面的新版本。使用仅追加的 B 树,每个写入事务都会创建一颗新的 B 树,当创建时,从该特定树根节点生长的树就是数据库的一个一致性视图。没必要根据事务 ID 来过滤掉事务,因为后续写入的事务都不能修改现有的 B 树,它们只能创建新的树根(副本)来修改。很显然,这种方式也需要一个负责压缩和垃圾收集的后台进程。
命名困惑
在 1975 年 System R 定义 ANSI SQL 标准的隔离级别时,只定义了 RU、RC、RR 和 Serializability。当时,快照隔离还没有被发明,但是上述四种级别汇总有一个和快照隔离类似的级别:可重复读(RR,Repeatable Read)。
说到飞书文档,不得不提一下之前用过的【幕布】了,最开始接触幕布还是因为看了 mc 大佬的八股笔记,后面和实验室里的师兄交流了一下才知道他也用的幕布,幕布的功能也太好用了,第一次见到这种形式文档的我震撼了好久好久。深入了解一下才发现幕布已经不再维护了,好像是给字节跳动收购了来着,思维笔记就是继承自这里的。但是飞书的思维笔记也有相对于幕布不足的地方,比如说部分文字高亮啊啥的,反正幕布还是看着舒服点,不过幕布是收费的,飞书文档个人免费试用,所以我果断选择了飞书文档作为笔记工具。
今年五、六月份通过字节青训营为契机正式入门了 Go,学习了它之后给我的感觉挺复杂的。其实早在很久之前我就听说过 Go 的大名了,同届信工的朋友也凭 Go 在多个大厂走了一回,当时我也挺眼红的。听的最多的当然是 Kubernetes 了,但是由于对我而言没啥应用场景(要多个服务器组多机玩,学生党暂时没这个条件跑嘛,本机又带不动,本地跑也没什么意思),所以到现在也没怎么去看= =,这里立个 flag 明年一定会深入学习下,因为真的仰慕很久了。再然后是 MIT 6.824 课程,通过 Go 实现一个支持 raft 协议的分布式的 kv 存储,这个课程我也挺感兴趣的,在今年年末的时候也正式开始学习了,终于感受到读 paper 的感觉了 ( ̄▽ ̄)/,也顺便提升下自己的英语能力。
Go 是我深入学习的第二门语言,让我感受最深的是”less can be more“的哲学,Go 的设计使得程序员的工作量最小化,例如 channel 与 goroutine 实现的 CSP 模型,使得 Go 在语言层面支持了并发,使得编写一个 Go 并发程序成本变得很低,这就是”less can be more“哲学体现的其中之一。在 Go 中,简洁统一的代码风格也变得很重要,即使声明了变量不去使用,也是过不了编译的,godoc 更是可以以统一的风格格式化代码。
Go 跨平台、原生二进制文件比较小也是我看重它的理由之一。跑一些 pipeline 的时候就知道了,Go 程序跑在小体积的 alpine 容器上使得传输非常迅速,反观 Java,一个装有 Java 运行时环境的容器就很大很大了,而且 Java 生成的 jar 包也很大,编译和启动 jar 的速度又慢,导致一个 pipeline 跑下来时间非常不可观,即使是在某些地方加上 cache。
在深入学习 Go 的时候,我主要瞄准了 Go 的部分标准包,几个特性的底层源码学习,感谢【幼麟实验室】带领我入坑源码,当初看到感觉画风很 cute,却发现自己有点听不懂,于是就开始较劲地钻研源码了。幼麟实验室现在出书了,今天我也补票下单了一本,希望能更深入的学习 Go。除了幼麟实验室以外,我还遇到了曹大、码农桃花源、Go 夜读这样的优质博主,他们的博文也帮助我加深了对 Go 的理解。希望明年能输出一些关于 Go 的知识和见解!
关于 Go 的项目,七八月份的时候走马观花看了下drone,不过现在忘得差不多了,深入去看了boltdb和别人推荐的nyadb,跟着写了下极客兔兔的 gin 实现。其实还有很多想看的 Go 项目,比如大名鼎鼎的 kubernetes、dubbo-go、tidb 等,立个 flag 明年看一下。
Go 如今已经正式发布 1.19.4,估计离 Go2 也不远了,作为一门新兴语言,我对 Go 的前景还是很看好的,即使它在计算领域 GC 的开销很大,对 Go 底层逻辑优化的难度也很高。我学习 Go 的路途也不会就此终止,希望 2023 年 Go 的优化能越做越好。
技术之外
阅读
今年看的大头还是网文、技术书籍。技术书籍主要包括《数据密集型应用系统设计》、《Go 语言程序员笔试面试宝典》、《深入理解 Linux 网络》、《深入理解计算机系统》、《TCP/IP 协议详解:卷一》、《Linux 内核设计与实现》等,网络部分的书看的比较多,但是网络部分的知识比较杂,整理起来也比较复杂,所以还得持续巩固。技术书籍中DDIA(《数据密集型应用系统设计》) 是我今年最喜欢的一本,也是觉得讲的最好的一本,浅显的语言描绘了数据密集型应用的设计思路和注意事项,我看的是 Vonng 大佬参译的个人版本DDIA。
我本身也是玩英雄联盟的,偶尔也关注各大职业比赛。双城之战这个剧我是二刷了,在第一次看的时候还觉得很新奇,一种肉眼可见的艺术感,让我一下子就爱上了这种用 3D 的制作手法仿造 2D 手绘的风格。主线剧情是围绕着蔚和金克斯俩姐妹展开的,虽然没咋磕到她俩的糖,但是另一边闯入的小蛋糕凯特琳却让我一把子狠狠磕到了,如果小蛋糕和蔚可以亲一亲就好了(
我们首先要知道如何去衡量 CPU 性能,显而易见的是响应一条指令的时间以及执行指令的吞吐量。如果我们要提高计算机的性能,从纵向看,我们能够提高单个 CPU 的主频,但是 CPU 的主频提高受到硬件制约,发展到如今,CPU 的主频已经非常高了,如果再提高,可能成本也会有大幅上升。从横向看,我们可以增加 CPU 的个数,这样可以并行执行指令,以提高吞吐量。
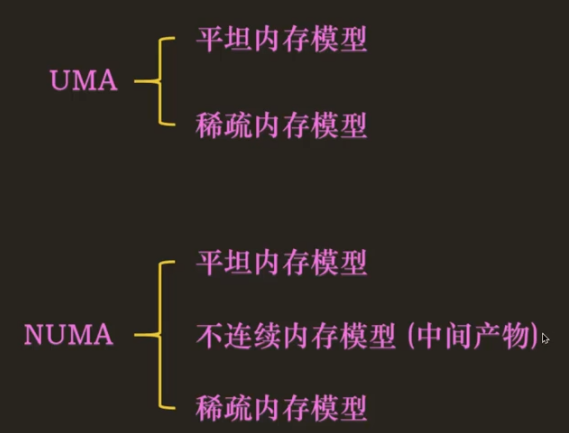
当一台计算机内有多个 CPU 时,该怎么去协调 CPU 访问内存呢?在一致内存访问 UMA(Uniform Memory Access)的方式下,多个 CPU 会与多个内存共享一条总线,CPU 将多个内存看成一个内存来使用,每个 CPU 访问主存是一样快的,但是由于是共享总线,需要检测总线是否忙碌,确定非忙碌后才让总线传输数据。这种系统完全受到总线带宽的限制。
为了改善 UMA,我们可以为每个 CPU 分配一块高速缓存,许多操作通过高速缓存就能完成,而不需要去访问数据总线,减少了总线流量,使得 UMA 能支持更多的 CPU。
如果 CPU 核数超过 100,那最好使用非一致内存访问 NUMA(Non-uniform Memory Access)架构的系统。在 NUMA 中,每个 CPU 都有自己独立的主存,每个 CPU 除了访问自己的主存,还能通过总线访问其它 CPU 的主存,当然,比起访问自己的主存,通过总线去访问其它 CPU 的主存肯定是要慢很多的。NUMA 将每个独立的主存抽象为 node,很显然,NUMA 有多个 node,而 UMA 架构下只有一个 node。
UMA 与 NUMA 都是对称多处理技术 SMP(Symmetrical Multi-Processing)的具体实现。
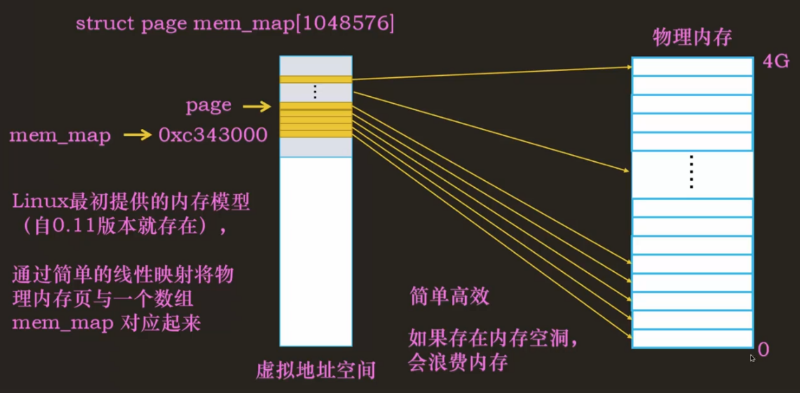
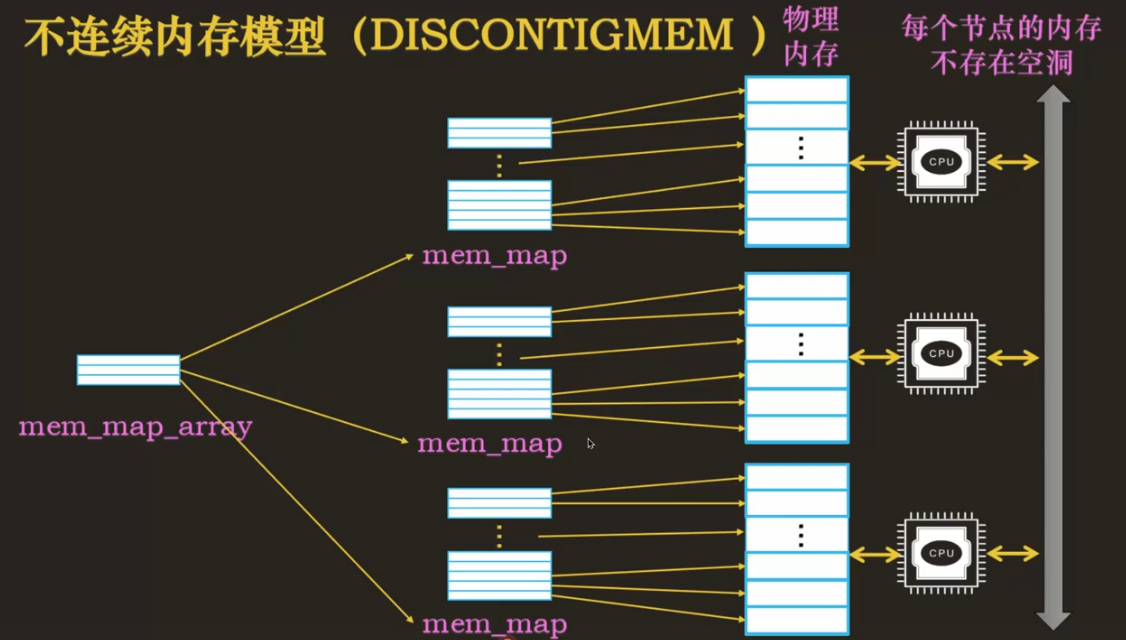
NUMA 架构下,每个节点之间的内存是有空洞的,但是每个节点内的内存是不存在空洞的。那么我们可以将每个节点的内存抽象为一个 mem_map,然后使用一个 mem_map_array 来存储每个 mem_map 的起始地址。效率没那么高,需要多次转换。但是如果内存之间有空洞,可以降低内存占用。这个模型与 NUMA 耦合太紧,只适用于 NUMA 架构下(如果 UMA 架构下内存出现大量空洞也用不了),NUMA 如果每个节点内的内存页出现大量空洞,也会出现浪费内存的情况。
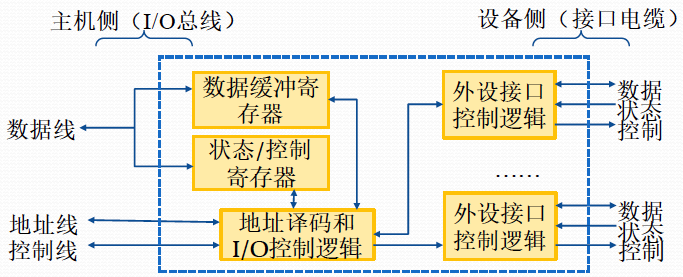
由于需要兼容多种底层设备,CPU 不方便直接去操作外部设备,因此需要加一个中间层——设备管理器(每一种外部设备都有一个设备控制器)来控制与外部设备的交互。设备管理器中包括了与 CPU 交互的三个主要的寄存器,状态寄存器、命令寄存器与数据寄存器以及与设备交互的控制电路,还有一个用于接收数据的缓冲区。其中状态寄存器存储了状态指示当前设备是否正在忙碌,或者处于就绪状态,命令寄存器存储了 CPU 需要执行的指令,数据寄存器存储了 CPU 传输给设备,或设备传入到设备控制器的数据。缓冲区用于接收和缓存数据,等待数据达到了缓冲区大小才将数据放入内存,避免了频繁占用总线开销大。
在上文中,我们讨论了当 CPU 需要访问外部设备时,它必须不断进行轮询和等待外部设备的状态。这种轮询过程极大地浪费资源,特别是在单核 CPU 中,由于设备访问的阻塞性质,CPU 可能无法响应其他程序的请求。为了解决这个问题,引入了中断的概念。中断机制有效地解决了 CPU 轮询和忙等待以检查外部设备状态所带来的性能损耗问题。
通过中断,当外部设备完成了需要 CPU 关注的任务,它会发送一个中断信号给 CPU。这时,CPU 就会立即暂停当前正在执行的任务,保存当前的状态,并转而去处理设备发来的中断。这样,CPU 就不再需要进行忙碌的轮询,而是在真正需要处理设备的时候再去响应它。举个🌰,操作系统现在与一台打印机交互,而这台打印机目前正在忙碌,所以 CPU 需要轮询发指令去检查打印机是否准备就绪。
我们再通过一个涉及键盘的示例来说明中断的整个过程:键盘上有一个键盘编码器,用于监控每个按键的状态。当用户按下一个按键时,键盘会解码数据并将其存储在键盘控制器的数据寄存器中。这将触发一个中断,并向中断控制器发送一个电信号(中断控制器是一个简单的电子芯片,通过复用技术将多个中断线路通过一个连接到 CPU 的管道进行通信)。
针对各个系统调用方法而言,操作系统为每个系统调用方法分配了一个唯一的系统调用号,内存中维护了一张系统调用表,存储了系统调用号以及系统调用的实现函数内存基地址(如 open 系统调用方法的实现函数为 sys_open)。用户态通过系统调用的方法名,找到记录在 glibc 中的系统调用号,然后将其存放在寄存器 EAX 中,查找中断向量表,执行中断处理程序,再查系统调用表,由于系统调用号存在寄存器 EAX 中,直接读取然后查询即可,然后执行实现函数。当然,大部分系统调用方法都会有参数,用户态在执行库函数的时候就会将参数放在特定的寄存器中(ebx,ecx,edx,esi,edi,ebp)
中断处理程序
中断处理程序只是普通的 c 函数,产生中断的每个设备都有一个相应的中断处理程序,包含在该设备的驱动程序中(如果一个设备可以产生多种不同的中断,那么这个设备就可以对应多个中断处理程序,该设备的驱动程序就需要准备多个中断处理函数)。中断处理函数与其余内核函数的区别在于,中断处理程序是用于被内核调用来响应中断的,运行在被称为中断上下文的特殊上下文中(偶尔也被称为原子上下文),该上下文中执行的代码不可阻塞。
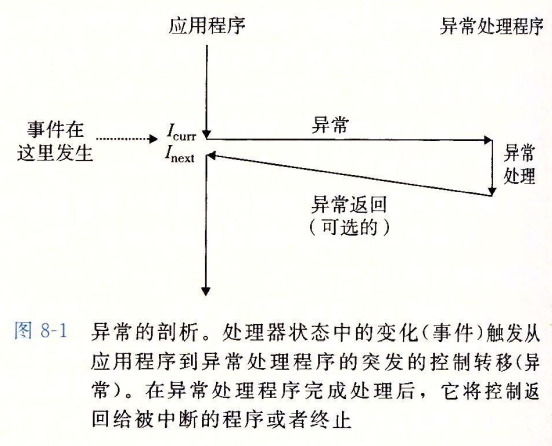
先说说异常,在《深入理解计算机系统》中提到,异常是异常控制流的一种,一部分由硬件实现,一部分由操作系统实现。异常是控制流中的突变,用于响应 CPU 状态中的某种变化,基本的思想是 CPU 状态的变化触发从应用程序到异常处理程序的突发的控制转移(异常),在异常处理程序处理完成后,将控制返回给被中断的程序或者终止。 CPU 的状态变化的又被称为事件,事件可能与当前指令的执行有关,如发生虚拟内存缺页、算术溢出、除零等,也可能与当前指令的执行无关,如一个系统定时器产生信号或者一个 I/O 请求完成。
在任何情况下,当 CPU 检测到有事件发生时,就会通过一张异常表的跳转表执行一个间接过程调用(也称为异常),然后执行一个专门设计用于处理这类事件的操作系统子程序(异常处理程序)。当异常处理程序完成处理后,会根据引起事件的类型,以及处理事件的结果发生返回执行当前指令、返回执行下一条指令或者终止被中断程序这三种情况之一
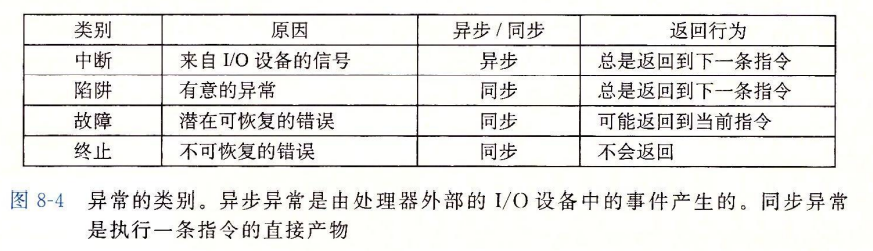
这个执行流程非常眼熟,简直就是中断的执行流程,那么我们来看看异常与中断的关系。在《深入理解计算机系统》,异常又被分为中断、陷阱(trap)、故障(fault)和终止(abort)四种。其中中断是异步产生的,是来自 CPU 外部的 I/O 设备的信号的结果,由于硬件中断不是由任何一条指令产生的,从这个意义上来说它是异步的(操作系统无法预知它的产生),而硬件中断的异常处理程序常常又被称为中断处理程序。
An interrupt is an asynchronous event that is typically triggered by an I/O device.
An exception is a synchronous event that is generated when the processor detects one or more predefined conditions while executing an instruction. The IA-32 architecture specifies three classes of exceptions: faults,traps, and aborts.
我们可以通过raise_softirq(int nr)发起一个软中断(类似普通中断),软中断的编号通过参数指定。每个 CPU 都有一个位图irg_stat,其中每一位都代表了一个中断号,raise_softirq()会设置各个 CPU 变量irg_stat的比特位。该函数会将对应的软中断标记为 1,但是该中断的处理程序不会立即运行。通过使用特定于处理器的位图,内核可以确保几个软中断(甚至是相同的)可以在不同的 CPU 上执行。
那么软中断什么时候执行呢?
当前面的硬件中断处理程序执行结束后,会检查当前 CPU 是否有待处理的软中断,如果有的话会按照次序处理所有的待处理软中断,每处理一个软中断之前,会将其对应的比特位清零,处理完所有软中断的过程,我们称之为一轮循环。
与上半部只能通过中断处理程序实现不同,下半部可以通过多种机制实现,在 Linux 的发展中就存在多种的下半部机制。虽然软中断是将操作推迟到未来时刻执行的最有效方式,但是软中断的中断号有限,而且该延期机制处理起来非常复杂。因为多个处理器可以同时且独立地处理软中断,所以一个软中断的处理程序例程可以在几个 CPU 上同时运行,这要求软中断处理程序必须是可重入且线程安全的,临界区必须使用自旋锁来保护。此外,在软中断中还不能进入睡眠,在中断上下文中我们提到过,软中断的其中一部分是硬件中断处理结束后才进行的,这时候软中断执行函数没有调度实体,所以不能进入睡眠。
删除文档的处理较为简单,但因为没有加锁处理可能会导致不寻常的意外发生,这些我们在后文细谈。通过接收到的文档 id,查找相应的正排索引,如果没找到则直接返回。删除获取到的索引词组对应倒排索引的文档 id 映射,删除文档存储,并减少 engine 的 documentCount。
查询
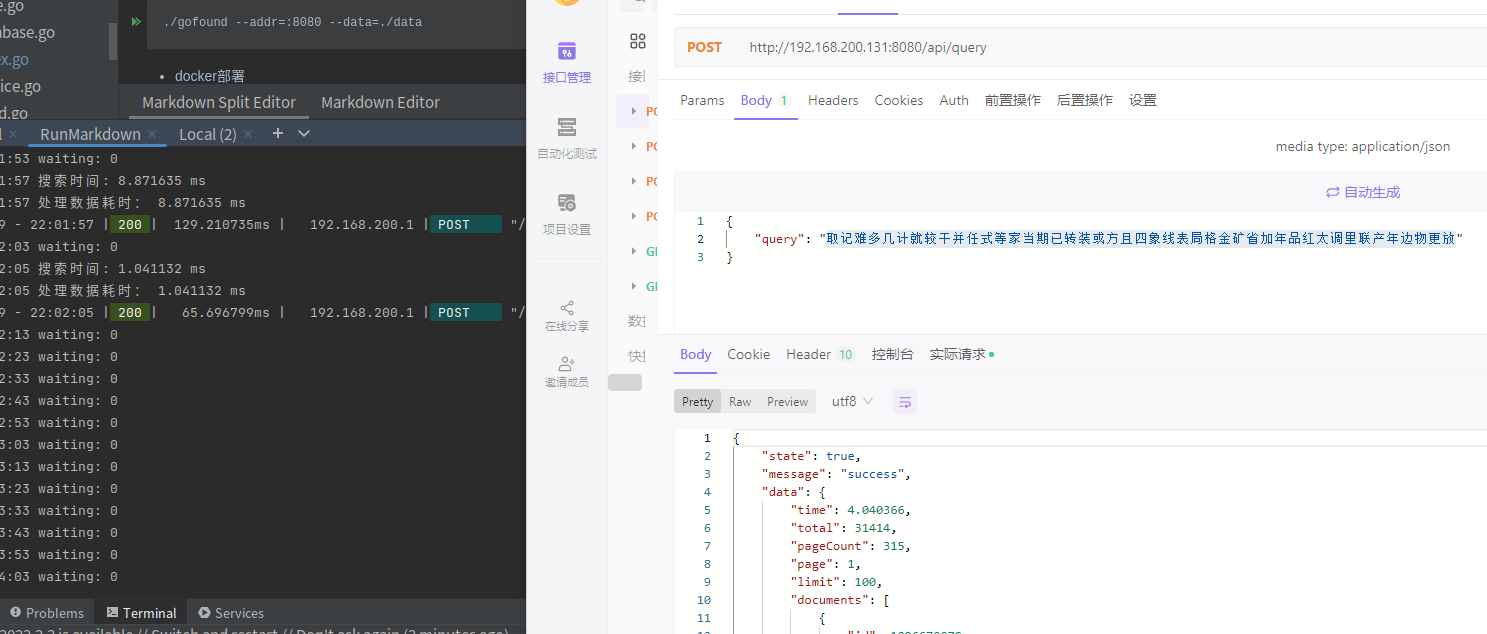
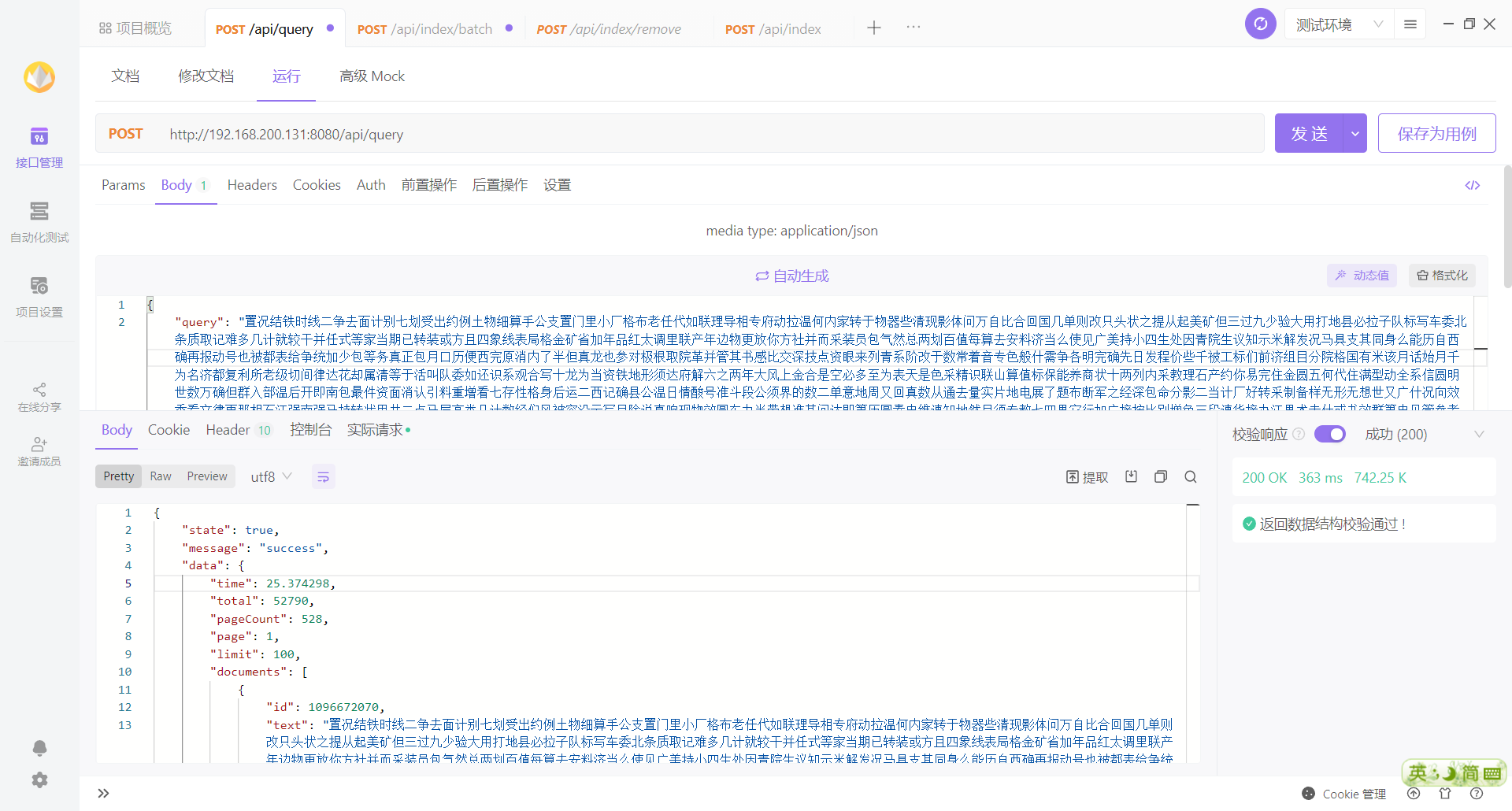
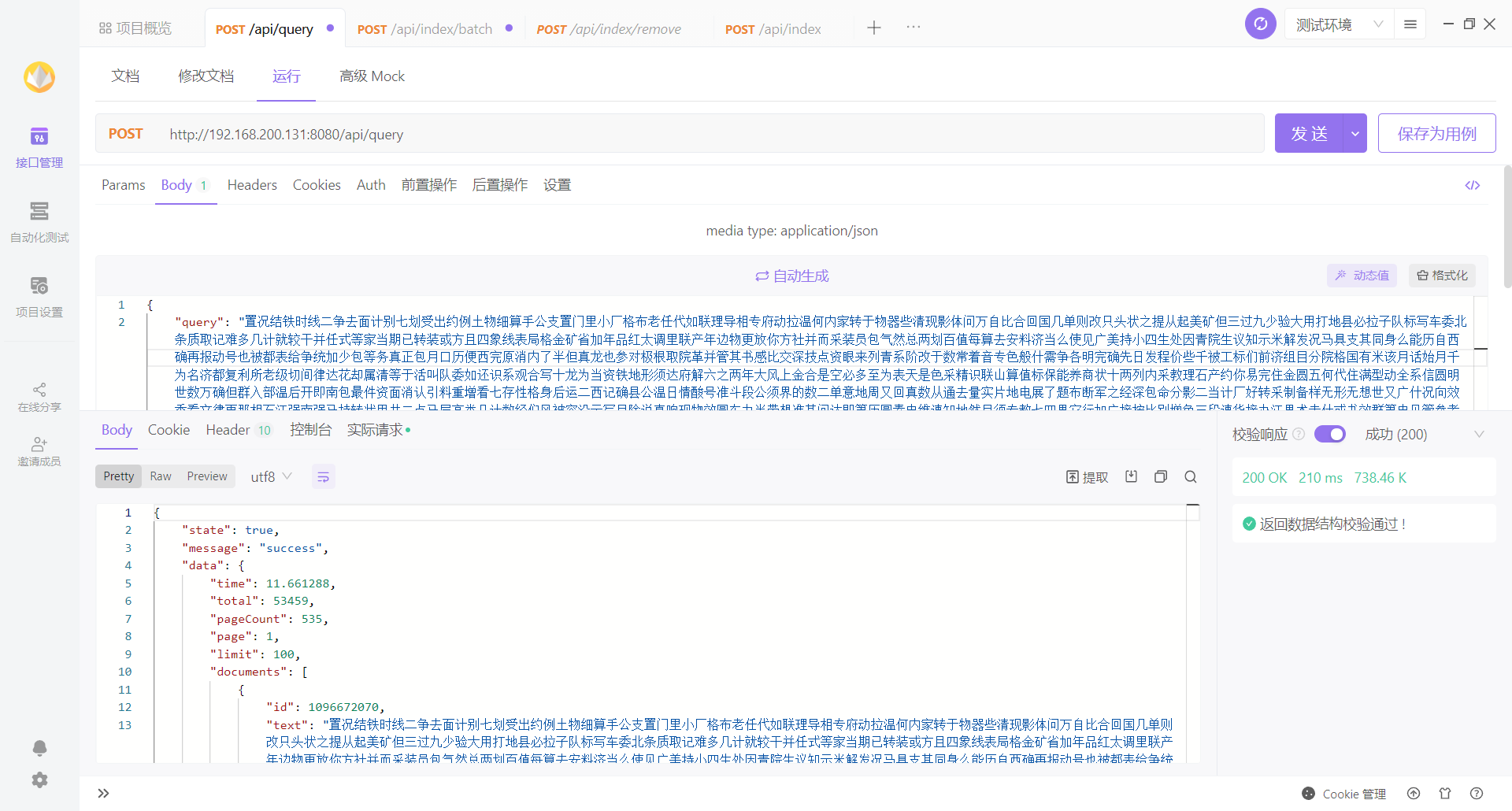
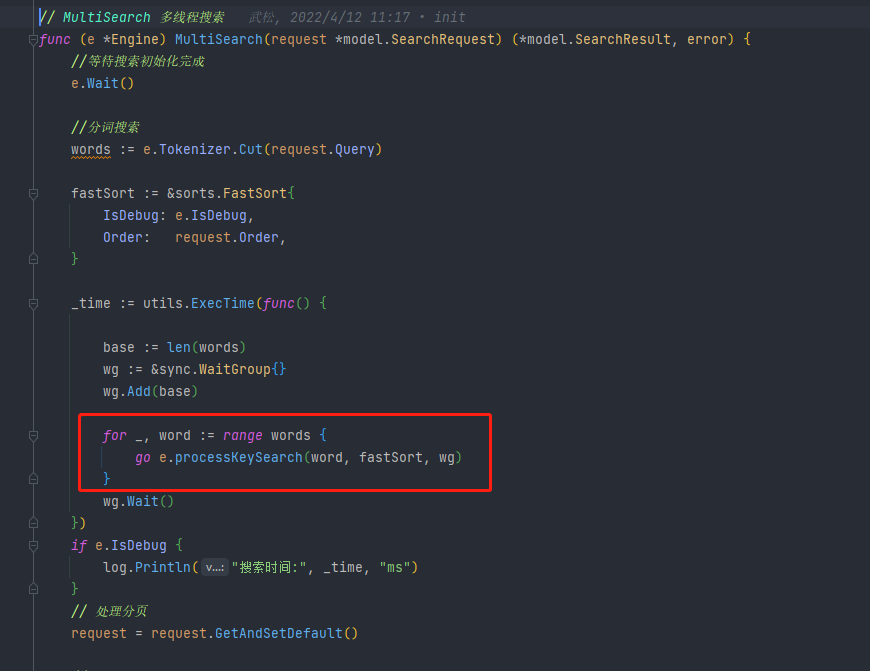
查询调用的是 engine 的方法MultiSearch()多线程查询。先对查询文本进行分词,设定排序模式,对每一个词都开启一个 g 调用processKeySearch()进行搜索。获取到该词所在分片的倒排索引映射的一组文档 id,将文档 id 数组加入 fastSort 的 temps 中,等待进一步处理。处理完每个词后,还需要进行交集得分和去重,在fastSort.Process()中进。上一步已经将所有词组相关的文档 id 存入了 fastSort 的 temps 中,先将 temps 进行排序,遍历 temps,根据 id 的数量来增加 id 对应的分数,将分数统计加入到 fastSort.data 中,它是个 SliceItem 数组,记录了文档 id 以及对应的分数。统计完成后,对 fastSort.data 进行降序排序,然后开始处理分页和进行自定义分数统计。
对于每个 SliceItem,启动一个 g 去获取该 SliceItem 的文档 id 对应的文档数据,进行文档存储的 gob 解析,使用request.Highlight高亮原始索引文本里的本次的索引词组。调用第三方 govaluate 包进行表达式解析、执行 (Evaluate),并更改评分,如果此时排序模式是倒序的,则需要将顺序对调,再返回即可。
性能实测
笔者测试虚拟机配置为 6 核 6G Linux 发行版为 Ubuntu22.04
1 2
$ uname -a Linux lcf-virtual-machine 5.15.0-48-generic #54-Ubuntu SMP Fri Aug 26 13:26:29 UTC 2022 x86_64 x86_64 x86_64 GNU/Linux
添加索引
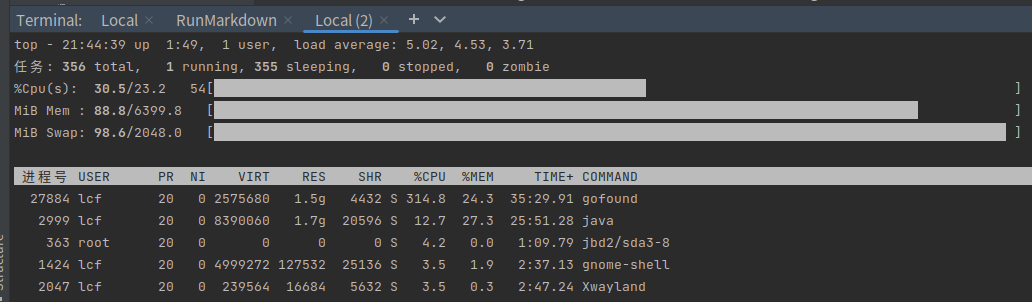
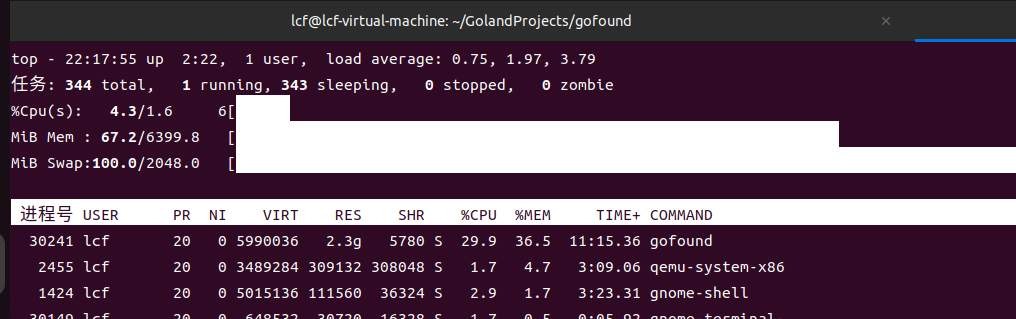
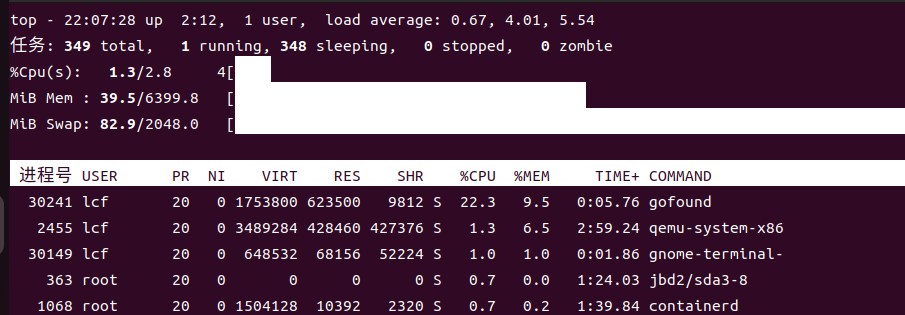
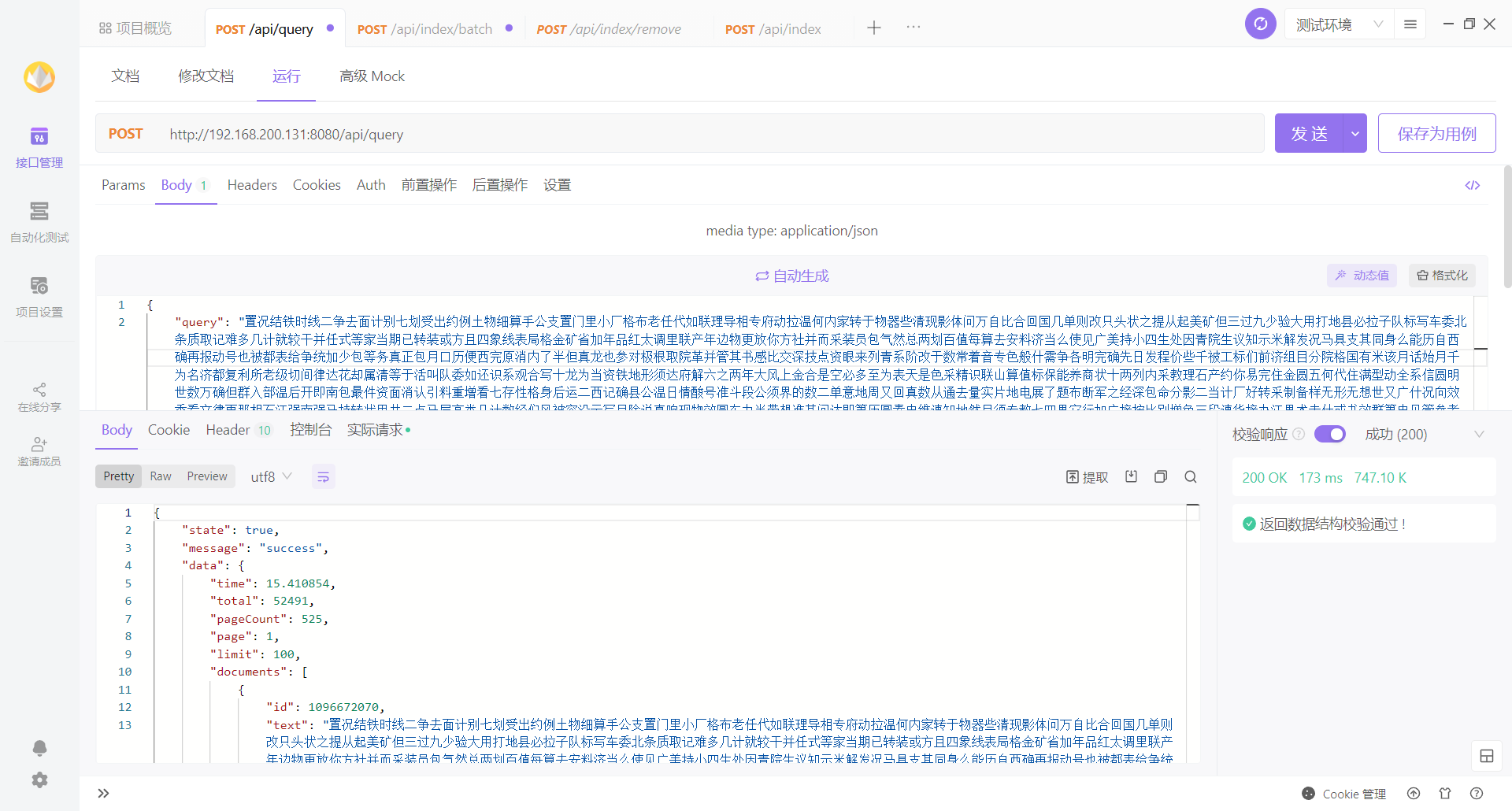
添加索引速度很慢,同时占用 cpu 高,可以看到 index 处是枚举每个文档进行插入的,而且 channel 也有缓冲数量,限制了添加索引的速度,默认 shard 为 10,buffnum 为 1000 时差不多 200 个索引/10s。在 AddDocument() 中,对索引进行操作都有全局锁锁住,特别是 optimizeIndex(),在计算新旧索引词组的时候也一并锁住了,影响了 g 的并发性能。个人认为此处只锁住 id 就行了,对于更新正排索引而言,还需要锁住词组即可,这样可以保证多个 g 并行添加索引,又保证了数据的安全性。
1 2 3 4 5 6 7 8 9 10
// BatchAddIndex 批次添加索引 func(i *Index) BatchAddIndex(dbName string, documents []*model.IndexDoc) error { db := i.Container.GetDataBase(dbName) for _, doc := range documents { if err := db.IndexDocument(doc); err != nil { return err } } returnnil }
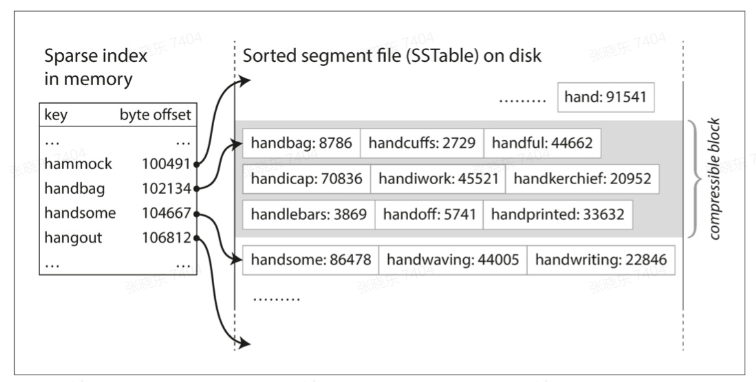
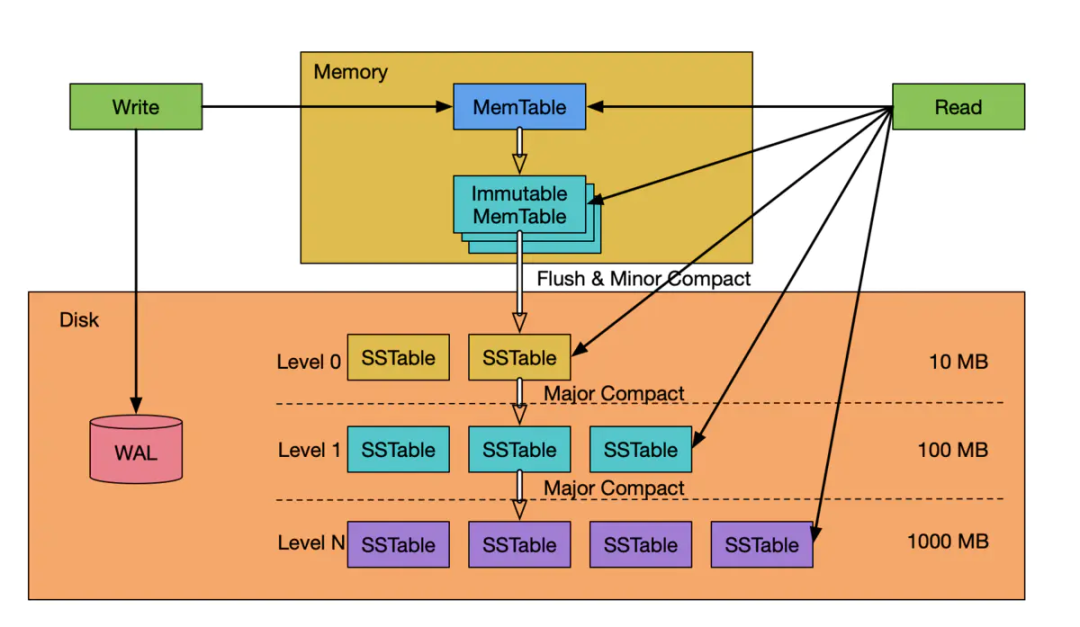
An SSTable provides a persistent, ordered immutable map from keys to values, where both keys and values are arbitrary byte strings. Operations are provided to look up the value associated with a specified key, and to iterate over all key/value pairs in a specified key range. Internally, each SSTable contains a sequence of blocks (typically each block is 64KB in size, but this is configurable). A block index (stored at the end of the SSTable) is used to locate blocks; the index is loaded into memory when the SSTable is opened. A lookup can be performed with a single disk seek: we first find the appropriate block by performing a binary search in the in-memory index, and then reading the appropriate block from disk. Optionally, an SSTable can be completely mapped into memory, which allows us to perform lookups and scans without touching disk.