-
-
The finished product

What's the Buzz? - Inspiration
The Catalyst:
February 16, 2024: Our hackathon was abruptly interrupted by an emergency notification from Stanford's Department of Public Safety (DPS). An unidentified individual had threatened violence at the campus entrance. As DPS scoured the campus and we were confined indoors. The announcement abruptly shifted our focus from the excitement of innovation to the immediacy of the situation at hand. During this atmosphere of uncertainty, a critical question arose within our team: As engineers, what role could we play?
The Vision:
Our attention was drawn to the presence of drones and robots at the hackathon and the idea was born out of observation. The convergence of our engineering backgrounds and the availability of these advanced tools sparked a unique opportunity for innovation. As we delved into brainstorming sessions, our discussions revolved around the capabilities of these technologies and how they could be leveraged to address the current challenges. The drones, with their aerial perspective, and the robots, capable of navigating ground terrains, presented a multifaceted approach to surveillance and monitoring.
The idea was simple yet ambitious: What if, instead of us having to program these drones and robots to do specific things, they knew what to do? What if they would understand their surroundings - and act accordingly? We knew that ChatGPT has enabled something great for software - but what about hardware?
Building the Dream - What it does
RoboLLVM transforms video streams from various robots into a contextually aware scene. It leverages knowledge about the robot's controls to generate code for executing specific tasks. Users simply select the robot type and their desired action. Our sophisticated interface intuitively interprets the request, activating relevant models to fulfill the task. This method offers a revolutionary way to control robots using natural language. To validate our concept, we've conducted demonstrations, such as using robot feeds to locate objects, aiding the elderly in finding essential items at home. Additionally, we showcased a feature where the video feed narrates what the robot observes, which could enhance mobility for visually impaired individuals by acting as a guide, similar to a support animal. Contrary to the assumption that this requires extensive programming knowledge, our model's strength lies in achieving these outcomes through three simple prompts:
"Hey, I am feeling dizzy" – The model interprets this as a cue to identify objects that could assist the user in feeling better.
"Act as a support dog for visually impaired" – This prompt signals the model to continuously describe the surroundings, enabling visually impaired users to navigate more easily.
"Ensure safety" - Upon receiving this prompt, the model is programmed to adjust its algorithms and focus on identifying any potential hazards within its environment. It meticulously trains its detection capabilities to recognize dangerous objects and is configured to alert users immediately upon their discovery.
This approach simplifies next-generation robot control, making it accessible through intuitive natural language commands.
Gliding Through Storms - How we built it
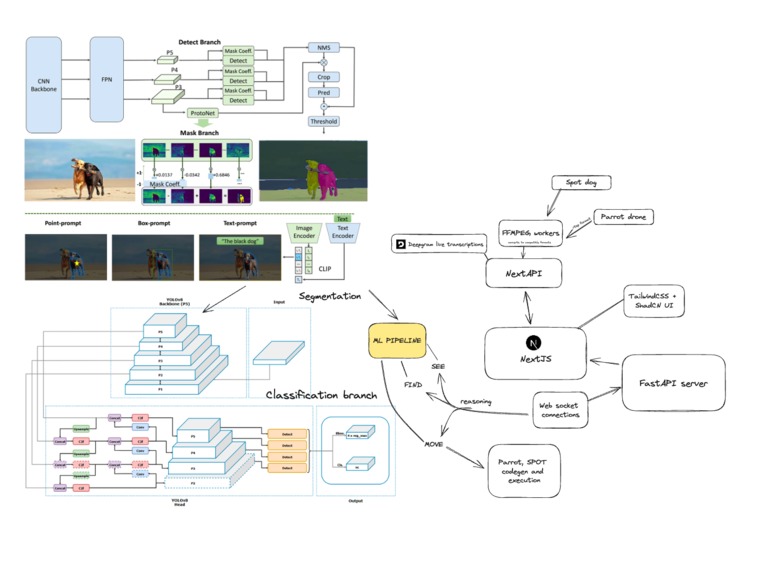
RoboLLVM is an advanced Multimodal Large Language Vision Model that operates on four core components: Segmentation, Classification, Reasoning, and Action, designed to process and interpret video streams from any device or robot efficiently.
Segmentation: At the forefront of RoboLLVM's capabilities is its sophisticated segmentation process. It processes video streams to decompose them into the minutest point clouds. This segmentation prowess is powered by a specialized model trained on the SA-1B dataset, an expansive open-source collection provided by Meta, comprising over 11 billion segmentation masks. This foundational step ensures precise identification and delineation of objects within any visual input.
Reasoning: Following segmentation, RoboLLVM engages in a critical reasoning phase. Users articulate their requirements through prompts, specifying the type of analysis they seek, The model adeptly selects the most appropriate dataset for the task at hand, leveraging its vast knowledge base to apply the correct analytical lens to the segmented data.
Classification: Post-reasoning, the segmented point clouds are forwarded to a classifier. This classifier is dynamically chosen based on the model's reasoning stage to accurately categorize the visual data. It applies sophisticated classification algorithms to understand and interpret the content of the images, setting the stage for actionable insights and responses.
Action: The culmination of RoboLLVM’s process is the action phase. With the classification complete, users can command the model in natural language to perform specific tasks. RoboLLVM translates these commands into precise machine instructions tailored to the selected robot's capabilities, ensuring the execution of desired actions efficiently and effectively.
RoboLLVM stands at the forefront of robotics and AI, merging deep learning, computer vision, and natural language processing to create a seamless interface between humans and machines. Its robust architecture and intelligent processing capabilities enable a wide range of applications, from assistive technologies to autonomous robotic operations, by understanding and interacting with the physical world in an unprecedented manner.
All of this combined makes a LLVM which can deploy any kind of use case just based on natural language.
Lessons from the Logbook - Challenges we ran into
Navigating through the technical challenges of implementing real-time object detection was a pivotal aspect of our project's development. Our primary goal was to integrate a machine learning model that excelled in performance and accuracy, essential for the swift identification of potential threats within the dynamic campus environment. This pursuit led us to experiment with various state-of-the-art models, including BLIP and GLIP. However, these models presented distinct challenges: BLIP was hindered by its slow inference times, making it unsuitable for the real-time aspect of our project, while GLIP, despite its promising capabilities, fell short in delivering the expected accuracy levels in our specific application context.
After thorough testing and consideration, we decided on YOLOv8 for its optimal balance between latency and accuracy. YOLOv8 demonstrated an exceptional ability to quickly and accurately analyze images, a critical feature for our system's effectiveness.
We also had a very hard time streaming real-time updates to the front-end using webhooks. And also streaming footage from drone and spot.
Chests of Treasure - Accomplishments that we're proud of
We are immensely proud to have realized our vision, successfully implementing a pioneering large language vision model tailored for robotics. This accomplishment marks a first in the field, setting a new benchmark for the integration of advanced AI with robotic systems. Our achievement not only fulfills our initial aspirations but also opens new avenues for innovation in robotics and AI. Beyond the technical success, our project stands as a testament to the power of interdisciplinary collaboration and the potential of leveraging cutting-edge technologies to solve real-world problems. The journey from concept to execution has enriched our understanding of robotics, artificial intelligence, and their synergistic possibilities, inspiring us to push the boundaries of what can be achieved in this exciting domain.
Gleanings from the Flight - What we learned
The integration of hardware into our project transformed the landscape of our challenge, underscoring the profound difference between embodied machine learning applications and their simulated counterparts in reinforcement learning environments. Working with physical devices introduced a myriad of complexities, notably the management of noisy control systems, which injected multiple layers of error into our long-term language planning and execution strategies. This reality necessitated a highly adaptive approach to development, compelling us to engage in frequent iterations of our system. As we progressed, we continuously refined our algorithms and added new functionalities to address emerging corner cases and ambiguities, ensuring our system's resilience and effectiveness.
Moreover, the project's architecture, which intricately linked drones to laptops and, subsequently, to cloud backends, introduced a unique set of connectivity challenges. The tripartite nature of this setup inherently complicated communication pathways, leading to frequent disruptions in connectivity. These interruptions not only posed significant hurdles to real-time data processing and analysis but also necessitated a reevaluation of our approach to network architecture and data transmission protocols.
To mitigate these issues, we embarked on a rigorous process of optimization and troubleshooting. We developed robust mechanisms to enhance the stability and reliability of the connections between each component of our system. This involved implementing advanced networking techniques to ensure seamless data flow and deploying sophisticated error-handling protocols to preemptively address potential points of failure. Through these efforts, we not only overcame the challenges presented by the hardware and connectivity but also gained invaluable insights into the intricacies of deploying machine learning models in real-world, hardware-integrated scenarios. Our journey through these challenges underscored the critical importance of hardware in the realm of embodied machine learning, highlighting the distinct challenges and opportunities it presents.
Charting New Horizons - What's next for RoboLLVM
Advanced Object Recognition and Handling:
- Integrate more advanced object recognition capabilities that can understand context or the function of objects, not just their appearance. For example, recognizing that a cup is full and needs to be carried more carefully. This involves integrating sensors that can measure weight or detect liquid levels inside a container.
Drone Swarms for Reforestation:
- Develop drone swarms capable of planting trees and vegetation in deforested areas. These drones would use AI to analyze soil conditions, select appropriate species for planting, and then autonomously carry out the planting process. This could significantly accelerate reforestation efforts and ecological restoration projects.
Autonomous Urban Planning and Construction:
- Drones that can not only survey land but also participate in the construction of buildings through 3D printing techniques. Equipped with materials to construct from the ground up, these drones could lay down roads, build small structures, or create emergency shelters in disaster-stricken areas, all orchestrated through high-level instructions.
Space Debris Collection Swarms:
- Extend the concept of drones into space, deploying swarms of space-drones equipped with nets or magnets to collect and deorbit space debris. These AI-guided drones could help address the growing issue of space junk endangering satellites and manned space missions.
Micro-Drones for Medical Applications:
- Develop micro-drones capable of navigating through the human body to deliver drugs directly to disease sites, perform micro-surgeries, or provide real-time diagnostics. Controlled through natural language instructions, these drones could revolutionize minimally invasive treatments and precision medicine.
AI Archaeologist Drones:
- Employ drone swarms to explore, map, and excavate archaeological sites with minimal human intervention. These drones could use ground-penetrating radar, LIDAR, and AI-driven analysis to uncover historical artifacts and structures, opening new windows into past civilizations without disturbing the sites.
This is just the start. We believe that with this technology, we can help a lot of people, and have a positive impact on humanity.
Built With
- deepgram
- fastapi
- nextjs
- node.js
- python
- pytorch
- tailwindcss
- typescript



Log in or sign up for Devpost to join the conversation.