-
-
Multi-agent analyzing
-
Self-envolving versions
-

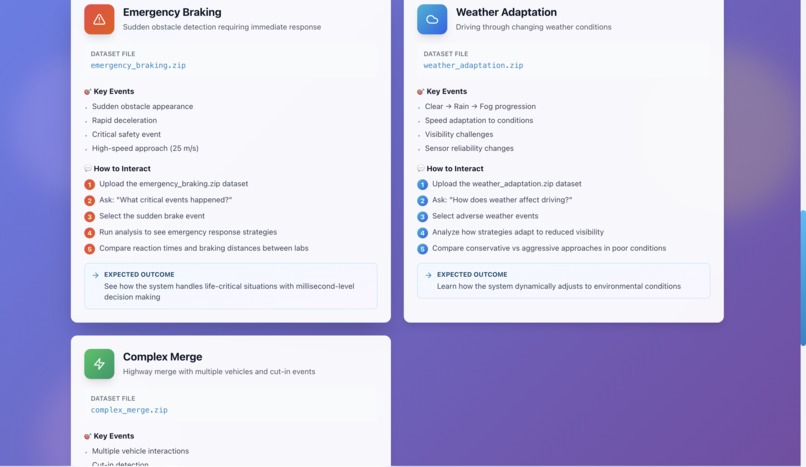
Scenorias for self-driving car
-
More scenorias for self-driving car




Inspiration
Autonomous driving research is exploding—thousands of new perception, prediction, and planning papers appear every year. But real self-driving teams still struggle to answer one critical question:
“Which method actually works for our scenario, on our real driving data?”
We imagined a system that connects these two worlds:
Real driving logs (cut-ins, pedestrians, adverse weather)
Live research intelligence (relevant methods, limitations, safety notes)
Self-evolving agents that improve with every scenario
Inspiration came from real AV workflows (Waymo, Cruise, Tesla), self-play methods from DeepMind, and multi-agent systems that can learn from each other.
So we built something no AV engineer has today: a self-evolving research co-pilot that analyzes your driving logs, finds the right research, tests paper logic on the video, and gets smarter over time.
What it does
Our system takes a self-driving dataset (zip of camera frames + driving CSV) and does three things:
- Detects real driving scenarios
Cut-in events, pedestrians, close following, rain conditions, lane merges, etc.
- Spins up two competing multi-agent research labs
SafetyLab → focuses on robustness, edge cases, failure modes
PerformanceLab → focuses on SOTA metrics, speed, compute, accuracy
Each lab independently:
Plans research queries
Retrieves relevant papers
Reads and extracts method logic
Critiques each paper for the specific scenario
Synthesizes a scenario-specific recommendation
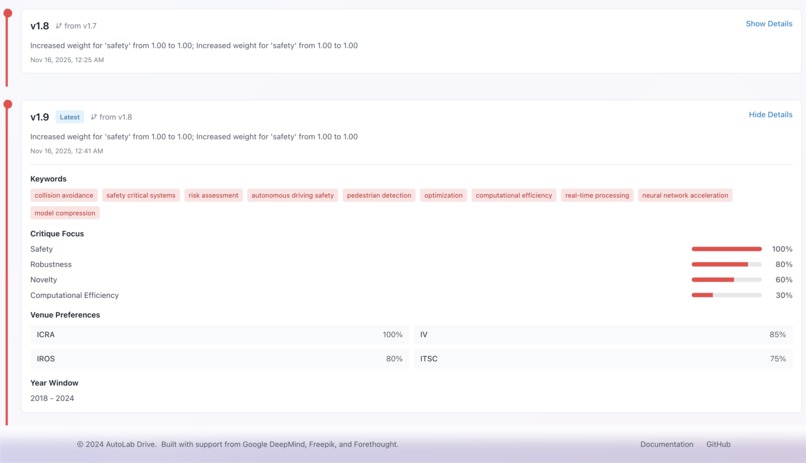
- Evolves after each scenario
A Judge agent compares the two labs’ outputs and explains why one is better. A Meta-Learner uses that feedback to mutate each lab’s strategy genome, making them smarter for the next event.
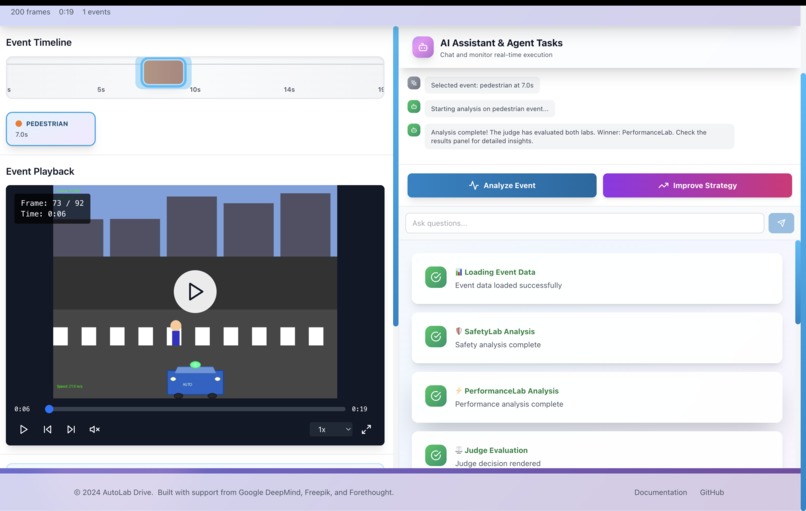
Then we overlay everything directly onto the real driving video:
recommended methods
paper limitations
logic checks (green/red indicators)
evolving agent strategies
It’s like watching your driving data being analyzed by an intelligent research team, live.
How we built it
Multi-agent framework
We built:
Planner
Retriever
Reader
Critic
Synthesizer
Judge
Meta-Learner
Each agent powered by LLM reasoning (Google DeepMind + LiquidMetal/MCP-like engines).
Strategy Genome (self-evolving brain)
Each lab has a structured JSON config with:
retrieval heuristics
reading templates
critique dimensions
synthesis preferences
The Meta-Learner updates these after every scenario.
Real-time event detection
From the CSV we detect:
cut-ins
pedestrian crossings
sudden risk events
speed changes
weather transitions
Video/animation renderer
Using the uploaded image frames, Freepik icons, and scenario metadata, we built:
real-time video replay
overlays for detected events
paper-logic pass/fail indicators
Backend + Frontend
FastAPI backend
React/Vite frontend
Frontegg for auth & multi-tenant support
S3 bucket for dataset storage
Everything integrates smoothly so users can:
Upload logs
Watch the replay
Trigger a research analysis
Watch their “AI research team” evolve
Challenges we ran into
Mapping papers to real driving conditions Papers don’t come structured; extracting “logic contracts” from them is difficult.
Building realistic scenario detection from sparse CSV data We had to design smart heuristics to trigger cut-in / pedestrian / risk events.
Making evolution meaningful but simple enough to demo We designed a strategy genome flexible enough to improve, but lightweight for a 1–2 day build.
Multi-agent orchestration Managing 10+ agents (across two labs) required careful pipeline and memory management.
Video + research synchronization Getting overlays to show at the exact moment of the event was tricky.
Accomplishments that we're proud of
We created a fully functioning multi-agent research lab tailored to self-driving.
We achieved real-time analysis of driving logs.
We implemented self-evolving strategies that genuinely improve across scenarios.
We visualized research insights directly on top of the driving video.
We integrated multiple sponsors (Google DeepMind, Freepik, Frontegg) into one polished system.
And most importantly: We built a tool that solves a real pain point for self-driving researchers.
What we learned
Self-driving pipelines are extremely complex — but with the right abstractions, LLM agents can truly help.
Multi-agent systems benefit massively from competition and cooperation (SafetyLab vs PerformanceLab).
Evolutionary strategies don’t require model training; prompt-level adaptation works surprisingly well.
Real driving data (frames + CSV) is a goldmine when paired with LLM-based research analysis.
Visualization matters: a simple video + icon overlay makes agents feel alive.
What's next for Untitled
Live BEV (Bird’s Eye View) visualization Convert camera frames into BEV maps for higher clarity.
Add LiDAR support Using point clouds for scenario detection & logic checking.
Connect to real paper APIs Move from stubs to full arXiv/Semantic Scholar integration.
Add domain-specialized critics Weather critic, occlusion critic, collision-risk critic.
Train a mini-simulator So paper logic can be tested by running simple virtual scenarios.
Switch from dual-lab to multi-lab tournaments More labs → more evolution → richer strategies.
Enterprise features Team workspace, dataset comparison, model regression testing.
Built With
- docker
- fastapi
- freepik
- python
- sqlite
- typescript







Log in or sign up for Devpost to join the conversation.