-
-
Landing page
-
Voice Enabled Control
-
Voice Enabled Control
-
Voice Enabled Control
-
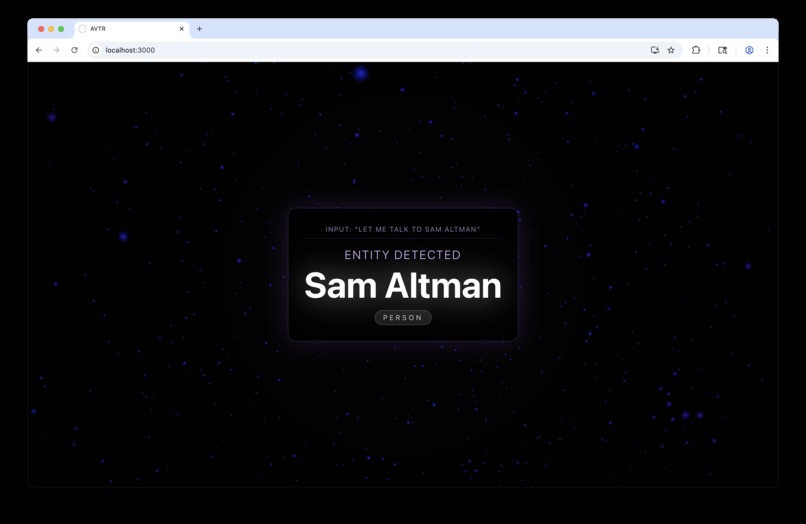
Matching to your contacts list
-
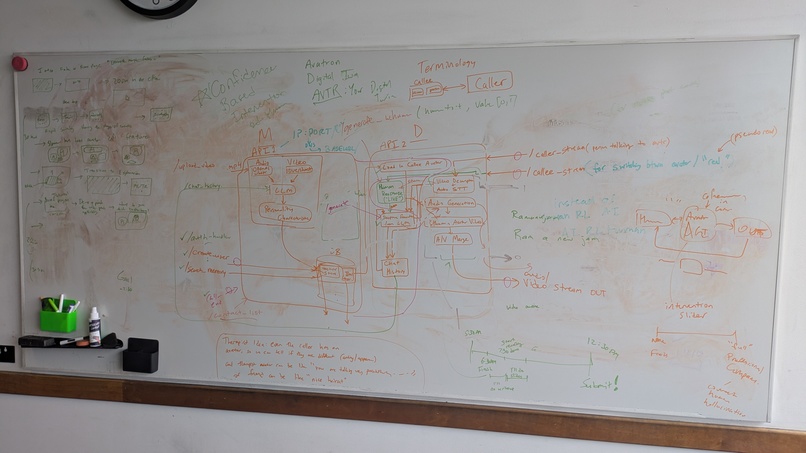
AVTR Architecture
-
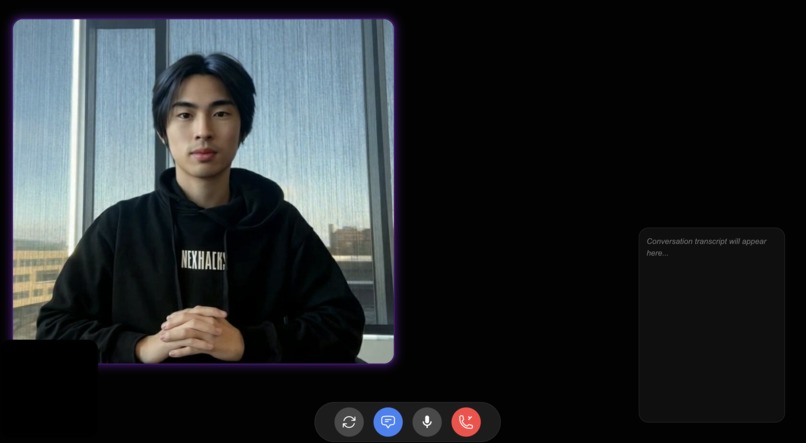
David as an AVTR
-









Inspiration
Now that AGI is widespread in Turing city, what will humans do?. Some people say the fear of losing all physical and mental advantages means we need to isolate and contain them. We believe that human intelligence and AGI should work together to raise the floor of both intelligences. We advocate for a human–AGI symbiotic model in which AGI systems compensate for human cognitive and physical limitations, while humans provide judgment, context, and emotional intelligence that AGI lacks.
What it does
AVTR is a platform hosting the next paradigm of human–AGI systems defined by shared agency and interchangeable control, enabling humans and AGIs to fluidly co-inhabit digital or physical embodiments in order to optimize attention, creativity, and decision-making across domains.
Here are some futuristic ideas to explain what we mean: Education: Imagine a teacher who wants to give full attention to every student—but that’s impossible for a single human. Now imagine a future where a human and an AGI can seamlessly move in and out of shared avatars. The teacher could instantly shift her presence to where it’s needed most, deciding how to divide her attention while the AGI maintains continuity everywhere else. Entertainment: This same idea could transform movies. You and your friends could watch a film together, and at any moment, one of you could step into a character and start acting from within the story. When you’re done, you step out, and the AGI continues the role seamlessly. Movies become shared, living experiences rather than fixed recordings. Healthcare: In medicine, AGI surgeons may surpass humans in precision and consistency. However, they may struggle with judgment calls—reading subtle conditions, adapting to unexpected environments, or expressing empathy. Human doctors would focus on high-level decisions and human understanding, while AGIs handle the technical execution.
Build your avatar’s personality
AVTR is a platform that embraces the fast evolving world of wearable smart tech, from Meta Ray Ban glasses, smart contacts, and brain implants, your personal AVTR can get an insight into your life in a non-intrusive manner, while also keeping your life private as all processing is done on-device. Depending on the capability of the technology your daily data is then understood by several modes: video, brain waves, energy expenditure, speech, body language; and tone. The objective is to construct a computational model that mirrors an individual’s cognitive patterns, enabling their reasoning and decision-making processes to be extended into machine intelligence.This is then saved locally to your device, serving as a growing dataset of you.
Let your avatar interact for you
Your avatar is able to answer calls for you, talk to other avatars on the AVTRverse and do all of the mundane tasks, leaving you with answering the questions that actually matter.
How we built it
For personality modeling, we used Overshoot to process the visuals from wearable inputs (we tested with Meta Ray Ban glasses) and Open AI Whisper to process the audio input in real time. These are fed into an LLM(Grok 4) to extract phonetic and language patterns as well as documenting activities, body language patterns, and conversations in a vector store for a RAG pipeline when the AVTR is representing you as well as a JSON store for dialect estimations, speech rate, and several other personality characteristics, both in MongoDB Atlas.
The AI controls the live avatar by leveraging Overshoot to process environmental and visual inputs, ElevenLabs for real-time speech recognition and synthesis, and ChatGPT-4o to reason over the combined sensory data and generate responses. The BitHuman virtual avatar serves as the embodiment layer, enabling the AGI to be experienced as a real-time, human-like presence. Humans control the avatar through real-time speech input, with the avatar serving as the human’s virtual embodiment. This is achieved using BitHuman’s live diffusion model for visual rendering, combined with ElevenLabs voice emulation to reproduce the user’s natural voice. Dynamic avatar animations are triggered through keyword- and gesture-based events, where Overshoot analyzes live webcam input to detect user motions and maps them to corresponding actions within BitHuman’s dynamic animation library. To achieve low-latency transitions between human-controlled and AI-controlled avatar behavior. The system is designed such that the LLM remains continuously active, even while the human is speaking and directly controlling the avatar. During human control, the AI operates in a parallel “shadow” state, receiving the same multimodal inputs—including live audio, visual context, and conversational history—and performing full reasoning and response generation.
The frontend utilized React and JavaScript at its core, with CSS and Tailwind used for styling and design. Three.js was the core 3D library used for rendering graphics. Socket.io was used for real time bi-directional communication and a hosted Render server was used as the signaling server in the WebRTC. Finally, we also used openrouter’s API to call grok to clean inputs for who the user wants to talk to, removing filler and identifying the entity.
Challenges we ran into
Real time video calling: Learning WebRTC was challenging as it was our first time formally building a project with it. Getting all the moving parts to talk to each other live with elements like Overshoot and Open AI Whisper as you interact with the avatar required robust, detailed planning before we even started building. One of the primary challenges in live avatar systems is minimizing end-to-end latency across perception, reasoning, and rendering. In the absence of a fully integrated, agentic real-time pipeline, our system required the orchestration of multiple specialized APIs—each responsible for a distinct sensory or cognitive function resulting in 13.4 second average latency. Additionally, certain components, particularly visual rendering, lack truly low-latency solutions, as they rely on diffusion-based models that impose inherent computational delays.
Accomplishments that we're proud of
Our main focus was developing a novel approach for reducing the latency of such complex pipelines to reach a normal conversation speed.
Futuristic and engaging frontend: We themed our app around being futuristic to match the theme of Turing City, a destination that is set in the (hopefully not-so-far) far future. This was also one of our early attempts at using Three.js so we’re proud of how the particle effects look. We are proud of our intentionally different user experience. By reducing reliance on buttons and visual controls, we minimize friction and let users get straight to the point using the most natural form of human input: voice.
We are very proud that we got down to 3.1 second average latency by only running the diffusion model on hands, eyes, and the mouth. we employed a predictive language model to anticipate upcoming tokens in the user’s speech, allowing response generation and rendering to begin ahead of the audio buffer and further reduce perceived latency.
What we learned
Improved UI/UX: After iterating and prototyping, we scrapped a lot of initial ideas that implemented a side bar with lists of people, professionals, and companies. We realized that needing to click a bunch of times just to navigate to a call screen introduced unnecessary friction. By utilizing voice controls and being able to type who to talk to, the user can easily dive into the AVTR experience. Finally, we learned to follow familiar designs for the call interface and inputting who to speak to as users intuitively understand how to use the app e.g. dynamic circle for users to say who to speak to, familiar video call layout and buttons.
What's next for AVTR
AVTR is a peek into the future of human-AGI interaction, where we get maximum benefit from such a high signal to noise ratio. AVTR’s applications can expand to completely asynchronous avatar-avatar interactions, which show benefits across many industries: Recruiting industries can be reformed with recruiter agents hosting interviews with candidates’ avatars, wasting no time, and only requiring the final round. Sales and IT can be transformed with human-AGI interaction converging closer to human-human interaction, allowing a single sales/IT specialist to help multiple people at once by weaving in and out of call with their avatar when necessary.
Expanding Interaction: We want to expand the horizons of human-AGI interactions. Updating our WebRTC infrastructure by utilizing a multipoint control unit structure would allow group meetings and calls between many different avatars and people, not just 1:1 interactions.
Response Confidence Indicator: LLM’s are still prone to hallucinating thus if they are to act like avatars and respond to another individual, we want to fact check every response with the data we have so future human-to-human interaction isn’t made confusing by previous human-to-avatar interaction



Log in or sign up for Devpost to join the conversation.