-
-
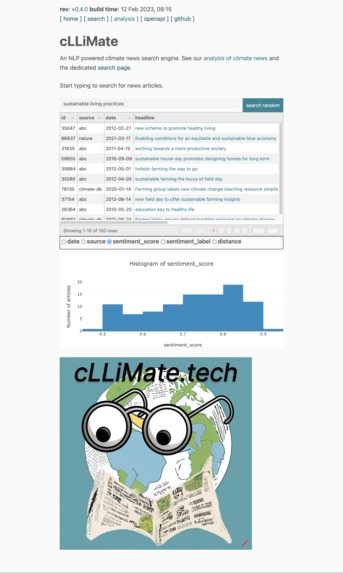
Home Screen
-
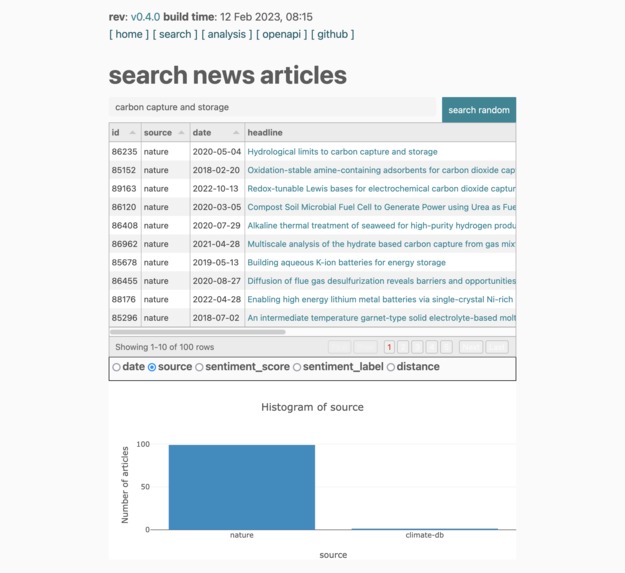
Search Page
-
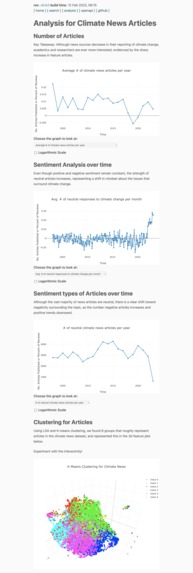
Analysis Page
-
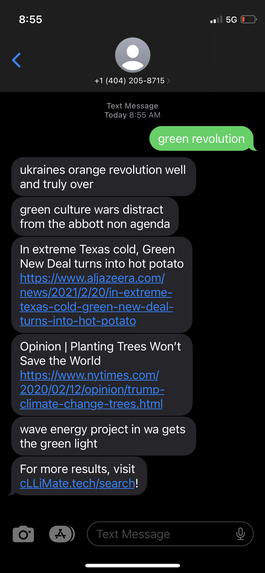
Twilio Output
-

Logo





Our Story
What inspired us:
As climate change worsens, we must face this crisis head-on, taking all necessary measures to combat the devastating effects of a rapidly changing Earth. The best measures and biggest changes begin with small steps, and it all starts with you!
A vital first step for everyone is to become more aware of this dilemma. We can accomplish this by setting a standard for clear and reliable news sources related to the Earth and its climate. This provides an objective view of our planet's state and insights into the many issues climate change encompasses.
As such, we decided to leverage the power of NLP and other machine learning methods to curate a news feed focused on the effects of climate change. It includes highly relevant news headlines to any query, information on climate trends, sentiment analysis, topic clustering, embedding computations, and the ability to interact with data visualization tools to find new insights.
Try it out now at cLLiMate.tech!
What it does
cLLiMate matches queries with curated headlines from reliable news and research articles. Users can send a prompt through the online search feature or via text message and receive factual, evidence-based articles relating to their topic. Additionally, cLLiMate provides visualizations and insights into the data it is based on, as well as a link to download the dataset directly.
How we built it:
Building this project was a rollercoaster of an experience!
Pt1: Fetching Data:
We wanted to ensure that we had a varied, rich, and diverse dataset encompassing many aspects of climate news throughout the years. We found a climate news database and leveraged that data, cosine similarity, and a threshold to filter out non-climate-related news from ABC News (Australian Broadcasting News). To accurately serve in-depth researchers, we used Beautiful Soup on all Nature research papers on climate and sustainability and fetched recent information from the NewsAPI.
You can view, access, and interact with the datasets at cLLiMate.tech/datasets?
Pt2: Processing and Analyzing Data:
The data first went through a series of preprocessors to filter out duplicates, unnecessary information, and anomalies to yield ~90,000 articles and headlines; all focused on climate from >1.3 million original data points.
The analysis encompassed 1) using GLoVe to transform headlines to embeddings, 2) training an LDA model using gensim & Natural Language ToolKit to topic model and cluster the news articles, 3) Hugging Face transformers to perform sentiment analysis, 4) a cluster of sklearn KNN's to find relevant news articles for search queries, and 5) UMAP and plotly to display the data.
It's an ensemble of different models and methods, but together yield a powerful engine to power our search and insights platform.
Users (including you!) can navigate to the site, search for relevant topics and news articles, interact with the plots to represent the data, and download the data for your own use.
Pt3: cLLiMate.tech
Our application is built using svelte-kit for interacting with search and plots. We have a backend written using FastAPI that indexes the article embeddings and to interact with services like Twilio. Locally, we use nginx to reverse proxy between containers and to serve local content.
We run our application on GCP, via Cloud Run. We use Cloud Build to build the containers and deploy the applications when we push to our main branch in GitHub. We use the Cloud Key Manager to manage a sops encrypted file with our tokens (Twilio and OpenAI), and use terraform to sync the tokens in Secrets Manager. Cloud Run is granted access to the tokens in Secrets Manager. We store static assets in Cloud Storage, which is used to store the article dataset, the index models, and various pre-computed plots.
Challenges we ran into
Top Level Issues
- Learning and quickly using new technologies and frameworks
- Continuously ensuring a clean git repo and GCP data-sharing system.
- Managing tasks and timelines to ensure an enjoyable hackathon experience and an amazing project!!!
Technical Issues
- Finding reliable and diverse datasets to find headlines from
- Filtering, transforming, and cleaning data from different types and schemas
- Performing analysis in a fast and efficient manner while still preserving the quality of the output
- Searching for groundbreaking insights from data, with the assistance of data viz and analysis tools
- Creating meaningful plots and data visualization tools to represent the data, as well as displaying them on the frontend
- Creating and Debugging API endpoints and ensuring a smooth E2E platform
Accomplishments that we're proud of
- Finding and scraping headlines while also curating our dataset to ensure each headline is relevant
- Implementing a powerful KNN search mechanism to find relevant news articles for search queries
- Doubling down on search features with a web-based and text-based implementation for user convenience
- Adding beautiful graphs and plots to visualize search data and yield unique insights
- Maintaining professional practices with secrets management, remote gcp bucket, and git version control
What we learned
- Using new technologies across the stack, from ML and data processing to web dev and GCP
- NLP processing libraries, such as gensim, GLoVE, NLTK, and more
- Learned to use powerful frameworks such as svelte-kit, Beautiful Soup, Requests, and Twilio
- Developed project-management, time-management, teamwork, and quick decision-making skills
What's next for cLLiMate
- Adding an automated mechanism for fetching recent climate news articles daily and including them into the database
- Boosting performance via OpenAPI embeddings, larger model size, and more rigorous training
- Creating a much more interactive frontend to serve all users efficiently
Built With
- beautiful-soup
- climate-news-db
- docker
- fastapi
- gcp
- gensim
- glove
- html/css
- huggingface
- javascript
- matplotlib
- newsapi
- nltk
- numpy
- pandas
- pyplot
- python
- requests
- sklearn
- svelte-kit
- twilio
- umap



Log in or sign up for Devpost to join the conversation.