-
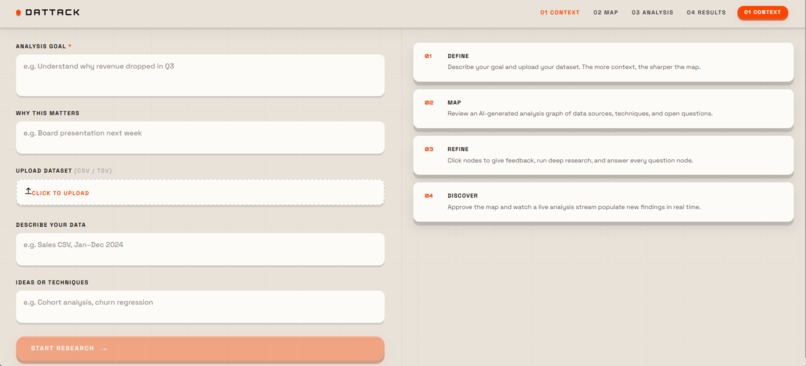
Onboarding Screen
-
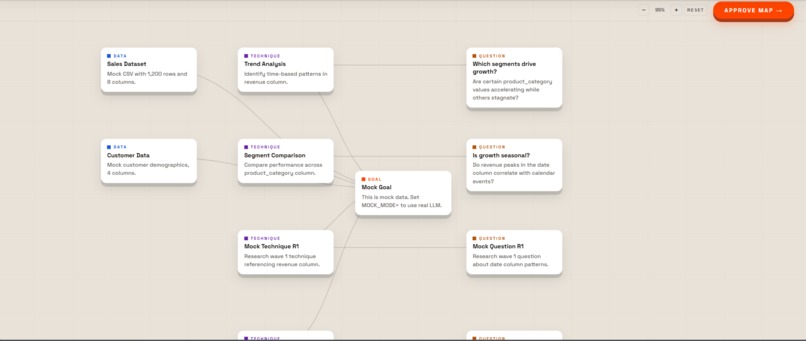
Data Exploratory Screen
-
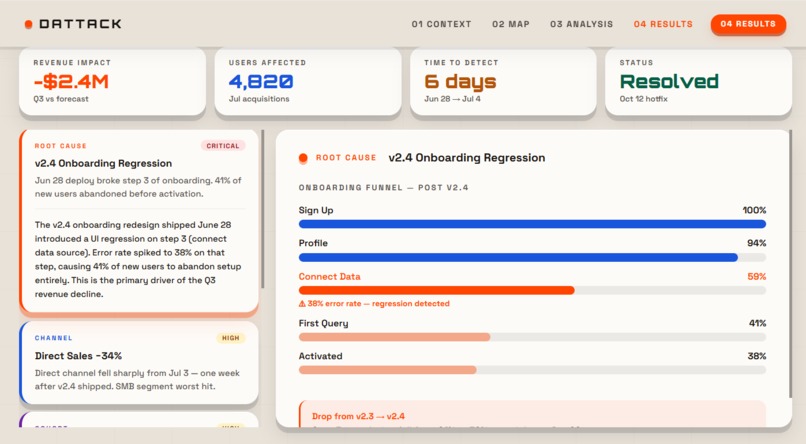
Data Finding Screen



Dattack
Dattack is a Human-in-the-Loop AI data consultant.
In simple terms: you upload a CSV, describe what you want to learn, and Dattack helps you explore the data, build an investigation map, and generate findings you can act on.
It is designed to feel like collaborating with a smart analyst, not just running a black-box report.
What Problem This Solves
Most data tools do one of two things:
- They are simple dashboards that answer only obvious questions.
- They are advanced platforms that are powerful but hard to use quickly.
Dattack sits in the middle:
- Easy enough to start with one CSV and one goal.
- Advanced enough to run a structured analysis pipeline and produce explainable findings.
How It Works (High-Level)
- You provide context and optional CSV data.
- Dattack builds a visual investigation map of goals, techniques, and questions.
- You review and refine that map with feedback.
- Dattack runs analysis scripts and streams findings back live.
- You end with a navigable graph of the full analysis journey.
Core Experience
- Context-first workflow: start with intent, not just data.
- Interactive map generation: see your analysis strategy as nodes and edges.
- Live research expansion: map grows in rounds.
- Human feedback loop: click nodes and ask for updates/deeper research.
- Streaming synthesis: findings appear in real time as analysis runs.
Quick Start
1) Backend setup
From backend:
pip install -r requirements.txt
uvicorn main:app --reload
Create backend/.env:
GITHUB_TOKEN=your_github_pat_with_models_read_scope
MOCK_MODE=false
2) Frontend setup
From frontend:
npm install
npm run dev
3) One-command local startup (Windows)
From repo root:
run.bat
Product Flow
- Context phase
- User submits goal + optional CSV.
- Deterministic curiosity pipeline extracts candidate questions/techniques.
- Map phase
- LLM generates initial graph and additional research rounds.
- User can provide node-level feedback.
- Approve phase
- Pending session is promoted to final session.
- Analysis phase
- Foundation scripts run, modules are selected, and script waves execute.
- Viz phase
- Findings are streamed in and attached to the graph.
Technical Architecture (Deeper Dive)
Dattack combines deterministic analytics with LLM orchestration in a staged pipeline:
- Frontend: React + TypeScript + Vite
- Backend: FastAPI
- LLM transport: OpenAI-compatible SDK targeting GitHub Models inference endpoint
- Streaming: Server-Sent Events (SSE)
- Execution model: DAG-like script dependencies executed in topological waves
Deterministic + Generative Hybrid
The system intentionally separates concerns:
Curiosity pipeline (deterministic)
- Runs before map generation on uploaded CSV.
- Produces confidence-scored
question_candidatesandtechnique_candidates. - Grounds map generation in observed data signals.
Map/research/synthesis (generative)
- LLM proposes investigative paths and synthesizes findings.
- Structured outputs are parsed into graph nodes/edges and streaming events.
This hybrid pattern improves reliability compared to pure-prompt workflows.
Analysis Runtime
After approval, analysis runs in three layers:
- Foundation layer (always-on)
- Schema detection
- Field profiling
- Data quality reporting
- Module selection layer (LLM-guided)
- Picks up to four domain modules (e.g., ranking, time series, anomaly).
- Module execution layer (parallel waves)
- Scripts respect dependency constraints.
- Parallelized within dependency-safe waves.
Streaming Contract
SSE messages include:
log: pipeline progress updatesnode_add: finding node + edge payloadcomplete: synthesis completion summary
This supports progressive UI updates and observability during execution.
API Surface
Primary endpoints:
POST /contextPOST /researchPOST /feedbackPOST /approveGET /stream?session_id=...
See routers in backend/routers.
Project Structure
- backend: API layer, orchestration, script runtime, session store
- frontend: UI phases, graph rendering, API/SSE client
- backend/analysis: curiosity + analysis scripts, runner, module registry
- backend/services: LLM service, script stream bridge, in-memory session handling
Design Principles
- Human-in-the-loop over full autonomy
- Graph-native reasoning over linear report dumps
- Deterministic signals before generative synthesis
- Progressive disclosure: simple UX, deep technical engine
Current Constraints
- Session store is currently in-memory (non-persistent)
- Performance and throughput depend on model tier/rate limits
- Quality depends on CSV shape and domain context provided by user
Roadmap Ideas
- Persistent session storage (DB-backed)
- Auth + multi-user workspaces
- Better provenance tracing from finding to script-level evidence
- Exportable analysis packs (graph + narrative + raw metrics)
License
Add your preferred license file and update this section.
Built With
- batchfile
- css
- html
- javascript
- python
- typescript

Log in or sign up for Devpost to join the conversation.