-
-

devDucky
-

-

Homepage
-
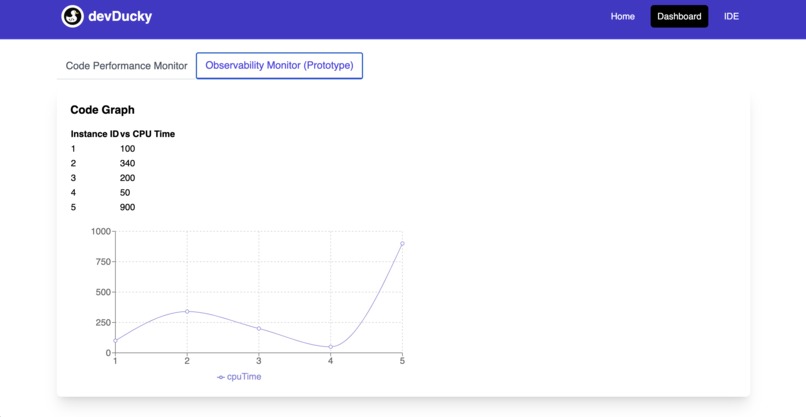
Observability Chart




Inspiration
The idea for devDucky came from the classic rubber duck debugging technique, where programmers explain their code to a rubber duck to find solutions. We thought: What if the duck could talk back? Imagine a duck that not only listens but also warns you about errors, suggests optimizations, and acts as a knowledgeable pair programmer. This led us to envision a smart duck powered by a fine-tuned LLM that combines hardware and software, constantly monitoring your code - it's even proven better than Copilot!
What it does
devDucky is your intelligent duck friend & IDE that sits on your desk observing your codebase. It gives you suggestions, diagnostics, fixes and anything else you might need!
How we built it
We built devDucky from the ground up - literally! We fine-tuned the brains behind devDucky using Unsloth, used a MERN stack to create the frontend, along with Python and Flask for the backend. Here's a breakdown of what everything does.
- Unsloth: We used Unsloth to fine-tune and quantize our model. We fine-tuned three different models (llama3.1 @ 375 steps, tinyllama @ 1 epoch, phi3 @ 375 steps) before settling on phi3 due to hardware constraints. We utilized the alpaca-cleaned 52k dataset by Yahma, and quantized all of our models to Q4_K_M.
- Express: Our Express implementation forms the backbone of our API architecture, handling backend logic for audio recording and data analysis/cleaning processes.
- Node: We used Node to power our server-side operations, providing a fast and scalable foundation for our backend.
- Vite: This is the main piece of our frontend. Vite is a key factor in enabling rapid UI implementation and efficient routing across our interface.
- Flask: We ran Flask as a dedicated microservice, managing our Python-based backend components, mainly the Ollama integration.
- Ollama: We used the Ollama python library along with the Ollama cli and desktop instance to run inference on our model.
- Mongoose: This streamlines our database operations, storing critical backend information, LLM responses, and user transcripts with efficiency and reliability.
Challenges we ran into
We had originally planned to use an RP2040 to give devDucky some ears, but it turns out there was no compatible microphone hardware. Luckily, we had an Arduino nano with a built-in mic, and 8 hours of troubleshooting later - it was working! Except, there was tons of static interference... So, our final option was to use a USB microphone, which worked perfectly! We also ran into issues with our laptops not being powerful enough to run our heavily fine-tuned models, forcing us to adapt and fine-tune phi3, a lightweight model, at the last minute.
Accomplishments that we're proud of
We're very proud of devDucky's efficiency compared to other code assistants like Copilot. When compared to Copilot, devDucky's base model is approximately 15% more efficient (without RAG or fine-tuning). With fine-tuning and RAG in the picture, expect that figure to be closer to 35%! We're also very proud of the fact that NONE of your data gets sent to a third party - devDucky's model is fully local! It's free, private, and fast - what more could you ask for?
What we learned
Throughout the development of devDucky, everyone on the team learned a lot. Everyone stuck to parts of the project that fit their own expertise - the biggest thing that came from this was proper file handling of file structure. Surprisingly, we barely had any merge conflicts, mainly due to us having a few different branches open at once. We also learned the importance of testing hardware before implementing it, because you never know if a component will be faulty, and we could have saved at least 8 hours of troubleshooting a faulty microphone. Lastly, find an idea you all agree with - we mulled over ideas for a while, but in the end it was worth it because we ended up finding something that we were all passionate about.
What's next for devDucky
The next steps for devDucky are moving model hosting to servers which would enable us to use even bigger models like codegeex4-all-9b as well as run inference faster, leading to an all around smoother experience. Aside from that, integrating the app with something like Datadog to enable a higher level of observability is another high priority. We have many small tweaks to make as well, but those are the main things!
Built With
- deepgram
- express.js
- flask
- mongoose
- node.js
- ollama
- react
- tailwindcss
- typescript
- unsloth
- vite




Log in or sign up for Devpost to join the conversation.