-
-

Dichatter
-
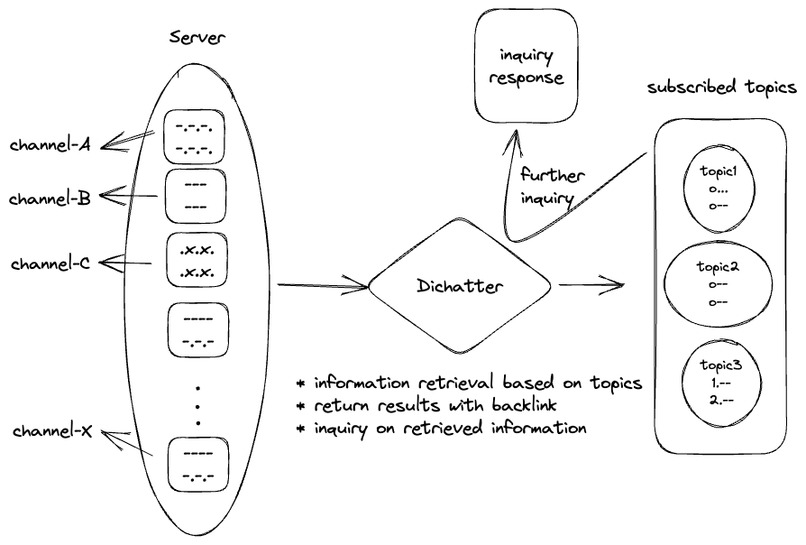
Application Logic
-
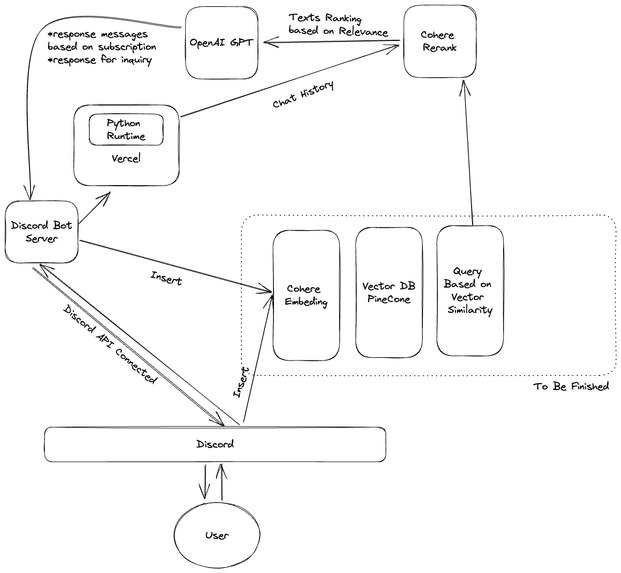
Tech Stack



Inspiration
In the age of information overload, the need for an intelligent tool to effectively manage and retrieve topic-based information has become more critical than ever. We saw the vast potential of AI and Machine Learning in this area and were inspired to develop Dichatter, a discord message bot designed to tackle this issue head-on and bring a more organized and simplified experience to users.
What it does
Dichatter is a discord message bot based on large language models (LLMs) that offer users topic-based information retrieval. Leveraging the power of AI, Dichatter is capable of understanding and categorizing a wide range of topics, making it easier for users to find relevant information in their discord channels.
How we built it
We utilized a variety of cloud services, including the Vercel Python runtime, the Cohere API, and the GPT API, to ensure the scalability of our application. We incorporated the Cohere rerank in our preprocessing stage to assure a more reliable input and output for our LLM. In the future, we plan to use Pinecone to store all messages and context into a vector database for better data retrieval capabilities.
Challenges we ran into
Building Dichatter was not without its challenges. Our primary obstacle was ensuring the scalability of our application, which we tackled using various cloud services. Ensuring a reliable input and output for our LLM by using the Cohere rerank was another challenge we faced. Lastly, handling the instability of the LLM generated content proved to be a tough task.
Accomplishments that we're proud of
Despite the challenges, we are proud to have developed an effective tool that addresses the information explosion problem in the digital world. We have successfully implemented and integrated LLMs into our discord bot to offer users a unique and efficient solution for topic-based information retrieval. In addition, the successful deployment of our application using cloud services is a significant achievement that guarantees its scalability.
What we learned
Throughout this journey, we learned a great deal about leveraging LLMs, utilizing cloud services for deployment, and the importance of preprocessing in AI applications. We also gained insights into managing the instability of LLM generated content and the potential of vector databases for effective data retrieval.
What's next for Dichatter
Our plans for Dichatter include utilizing Pinecone to store all messages and context into a vector database, enhancing the overall data retrieval process. We also aim to continually refine and improve our LLM's stability to ensure that Dichatter remains a reliable tool for topic-based information retrieval.



Log in or sign up for Devpost to join the conversation.