-
-

Path finder avoiding all the objects :D
-
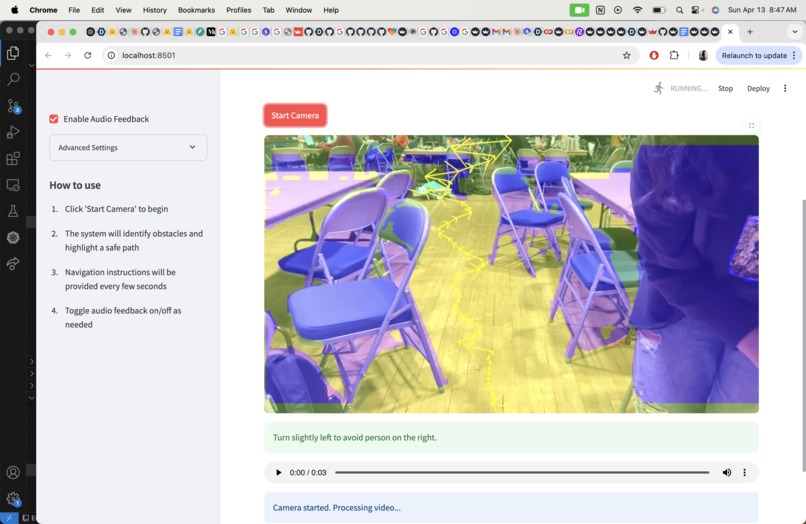
Video and Audio Integration
-

Path finder part 3
-

Another angle of path finder :)
-
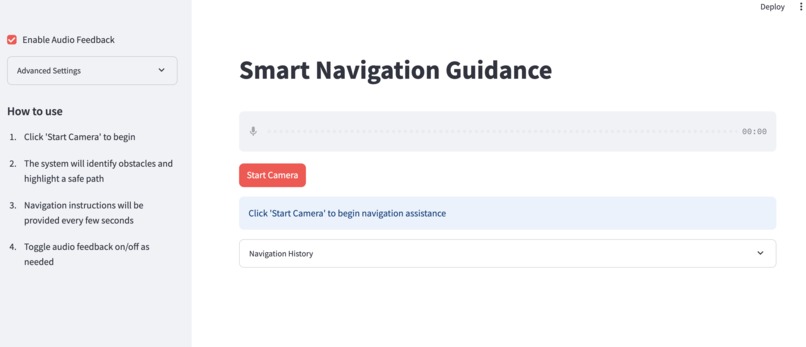
The Speech-To-Text (STT) and Text-To-Speech (TTS) Implementation for Low Vision Users!
-

AR Glasses Implementation
-
Variety of cameras to choose from for path detection







Inspiration
We asked ourselves: "What if AI could see the world and speak it for someone who can’t?"
Millions of blind and visually impaired people face uncertainty every time they navigate public spaces. Most assistive tools rely on GPS or limited object detection — but they don't provide the kind of real-time, spatially-aware guidance a sighted person takes for granted.
We wanted to change that. We set out to build a tool that acts like a co-pilot — one that sees, thinks, and speaks.
What it does
EchoRoute is a smart, real-time navigation assistant designed for the visually impaired. It combines computer vision, AI-generated natural language, and audio feedback to help users move through complex environments safely. The system captures live video from a webcam, detects obstacles and walkable areas using segmentation, computes a "safe path" visually, and delivers spoken instructions like "veer slightly left to avoid a chair."
Every few seconds, the camera feed is analyzed, a dynamic path is generated, and a fresh voice instruction is spoken aloud. Users can also interact with EchoRoute using voice input to describe their destination, which is transcribed using speech-to-text and used to inform future movement decisions.
How We Built It
We combined multiple technologies to make EchoRoute work:
- YOLOv8 (segmentation mode) for real-time object and floor detection, used to identify obstacles and walkable regions from the webcam feed.
- Custom masking and pathfinding logic to interpret YOLO segmentation masks and draw a visual "safe route" through the environment.
- Google Gemini 2.0 Flash to analyze both the raw image and structured scene data and produce natural language instructions on how to safely move forward.
- Text-to-Speech (TTS) using gTTS, enabling real-time verbal feedback with clear, actionable guidance.
- Speech-to-Text (STT) using the speech_recognition library, allowing users to describe their destination through voice input.
- Streamlit for rapid UI prototyping, live video display, and real-time audio/image interaction.
Every few seconds, a frame is analyzed, safe zones are highlighted, and Gemini generates a fresh voice instruction — creating a continuous feedback loop between vision, language, and action.
What We Learned
We dove deep into:
- Real-time computer vision with YOLO and OpenCV
- Multimodal prompting with image and structured data inputs
- Converting raw mask data into intuitive navigation paths
- Voice interface engineering using both TTS and STT
- Prompt engineering and instruction clarity for large language models
- Managing real-time UI in Streamlit without breaking the video loop
We also learned how much precision and timing matter when safety is involved. It’s one thing to detect a chair — it’s another to describe how to move around it in plain English, in real time.
Challenges We Faced
- Latency vs. Quality tradeoffs: We wanted our visual and auditory feedback to be as quick as possible to maximize how useful it is to the user. Balancing frame rate, model inference time, and speech synthesis without GPU acceleration was a recurring challenge.
- Webcam handling in Streamlit: Streamlit re-renders on every interaction, which doesn't play nicely with persistent video capture. We implemented throttled inference and session state management to keep the stream responsive and stable.
- Segmentation-based pathfinding: Translating segmentation masks into dynamic paths required a lot of tweaking — including grid-based area detection and arrow-based path rendering.
- Real-time TTS and STT integration: Ensuring that speech input and audio output didn’t block UI responsiveness took some careful orchestration of temp files, audio buffers, and threading.
What's next for EchoRoute
- AR or Smart Glasses Hardware: Our immediate next step would be porting the system to smart glasses for real world use (with a los res wifi camera centered in front of the glasses frame, and bluetooth/wifi speakers on the side)
- Map building: Integrating SLAM or depth estimation to build a local floor map as the user walks
- Accessibility testing: Partnering with organizations for the visually impaired to collect feedback and iterate
- Danger assessments: Expanding our model to recognize threats such as incoming cars or bicyclists, and according actions to take
- Connecting to GPS: integrating our project with location to have large-scale direction
Our goals is that EchoRoute will be more than a project, and more a step toward a world in which AI actively amplifies independence, mobility, and safety for everyone.



Log in or sign up for Devpost to join the conversation.