-
-
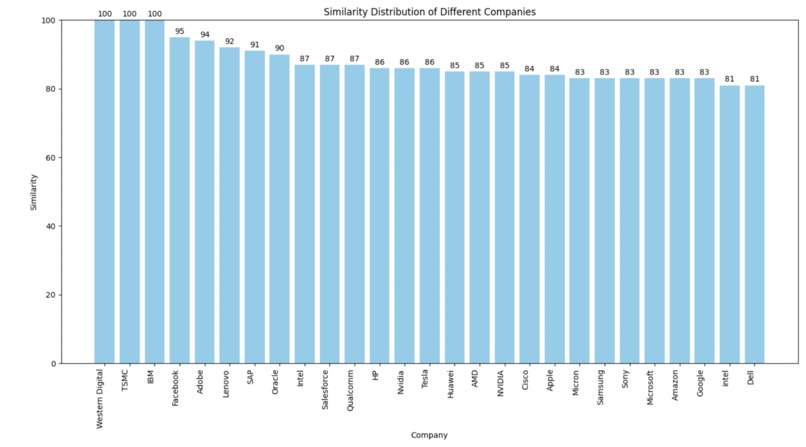
This bar graph displays the similarity scores for each company in descending order.
-
The EnviroInvest Web Interface


Inspiration 🌱🌲♻️🌿
This project was inspired by my recent experiences researching technology companies to invest in. Given the growth in artificial intelligence and computing, many technology developers and manufactures are expected to realize significant growth. As an investor, one of the many criteria I consider is a company's ESG risk rating. Companies with higher ESG ratings tend to perform better in the future, as they are more efficient in managing environmental, social, and governance risks. However, many of the companies I found were especially exaggerating their products, policies, and initiatives as environmentally friendly to boost their environmental risk rating and appeal to eco-conscious investors like me. This really frustrated me, as it lowered the credibility of ESG ratings, making it even more difficult for me to decide what companies to invest in. Hence, I decided to create my own rating system. Rather than score these giant tech companies on just their environmental goals and self-proclaimed achievements, EnviroInvest actually verifies these claims, ensuring they are actually implementing successful sustainable initiatives. By quantifying companies' transparency with the public on their environmental efforts, I hope EnviroInvest can help investors like me see which companies lie about their initiatives and which companies actually walk the talk.
What it does 🌱🌲♻️🌿
EnviroInvest is an environmentally friendly investment advisor chatbot that helps ethical investors make informed decisions about investing in giant tech companies, one of the areas expected to see the greatest growth in the near future. The chatbot is built off of a natural language processing model that analyzes and compares the environmental claims to the actual efforts of various companies based on their sustainability reports, news articles, and executive statements. The model then quantifies each company's transparency and honesty using a scale from 1-100 where 1 is totally dishonest and 100 is perfectly honest. Through a web interface, investors can see the transparency scores for selected tech companies and receive suggestions for alternative high-growth companies with more ethical environmental practices.
How we built it 🌱🌲♻️🌿
To build this project, I first set up a development environment and organized the project directory structure. Then, I employed a NEWSAPI for data collection. I used various queries to find sustainability reports, executive statements, and news articles relating to the environmental efforts of major technology companies. Next, I processed the data and cleansed it so that all the data followed a comprehendible, standardized format. Then, I developed a natural language processing model using BERT to analyze and compare companies' environmental claims in their sustainability reports and executive statements with their actual environmental impact recorded in news articles. But first, I had to implement a named-entity recognition spaCy model to sort all the data by company. I then used a BERT cosine similarity function to detect similarities in text/semantics between company claims and actual impact. I developed another algorithm to quantify this similarity, or lack thereof, on a scale of 1-100 for each company. Following this, I created a flask web application to serve as the chatbot's backend, and designed a frontend using HTML, CSS, and JavaScript. Finally, I integrated a dropdown menu for company selection and added a button that allows investors to see the environmental transparency scores of a company of their choice.
Technologies and why we chose them & any notable algorithms or methodologies implemented 🌱♻️
- Languages: python, html, css, javascript
- I used NEWSAPI because I wanted to collect a wide variety of up-to-date news articles. Also, it would not be practical at all to manually add articles.
- I used BERT because it has extremely powerful natural language processing capabilities and is already pre-trained. BERT is very much capable of understanding and analyzing texts to detect similarity.
- Implemented a spaCy named-entity recognition algorithm to classify all the times the selected companies were mentioned in all the data
- Implemented a cosine similarity algorithm with BERT to find similarities between company claims and actual impact
Challenges we ran into 🌱🌲♻️🌿
I ran into many challenges throughout the entire process related to syntax and other errors. It took a great deal of time and effort searching online to find meaningful and effective advice. However, the greatest challenge I faced had to have been data collection. I spent many hours brainstorming ways to gather as much data as possible about sustainability reports, company statements, and company environmental impacts. Initially, I knew I was going to use the NEWSAPI, but I could only get 100 articles per request. I tried iterating through different pages, which did not work, so I was stuck with only 300 articles for press releases, executive statements, and general news in total (100 for each). Because I had such poor data, the model had an extremely hard time finding companies and giving scores. To fix this issue, I attempted many other methods such as trying to add a SECAPI to the data collection to access SEC EDGAR filings and web scraping for press releases through company websites; however, I could not get these strategies to work. Then, I decided to experiment with multiple queries with the NEWSAPI. While I had already tested iterating through different pages to no avail, I did not try iterating through the same page but with different queries. Using this method where each query was a different tech company, I was able to find hundreds of reports, articles, and press releases for each company all the while staying under the 100 article limit per request and remaining on the same page. With around 2000 articles in my dataset, my NLP model performed with much greater success.
Accomplishments that we're proud of🌱🌲♻️🌿
This is my first ever hackathon. I am extremely proud of myself for working through the struggles and preserving. There were definitely times when I felt defeated and hopeless, especially when my code was filled with errors; however, I continued to sift through the internet and was ultimately able to develop a functional application similar to what I had envisioned. My goal was to develop a project that shows my curiosity for AI, and I am happy to have achieved that.
What we learned🌱🌲♻️🌿
- Learned how to perform cosine similarity with BERT
- Learned how to create visual representations using code (python)
- Became familiar with Jupyter notebooks
What's next for EnviroInvest🌱🌲♻️🌿
If I had more time, I would definitely go back and improve upon the data collection. Sometimes, when I generated data from the NEWSAPI, the articles I got back were almost totally unrelated to the queries I had searched with. There was definitely nonsense data that I should have replaced with actual data in relation to tech companies and sustainability. I would spend more time figuring out how to use SECAPI and how to web scrape company websites for press releases. Also, with more data, I would be able to fully develop a more interactive chatbot that can actually provide responses to investors' questions. Right now, EnviroInvest's chatbot only allows investors to compare the scores of selected tech companies. In the future, I hope to develop the chatbot so that investors can actually ask and learn why certain companies have certain scores. I would also like the chatbot to be able to provide more tailored recommendations to investors. Right now, recommendations are solely based on transparency scores. Companies with high scores are recommended. But I would also like alternative investments to be industry and product-specific. For example, if an investor sees potential in Micron but it has a low transparency score, the model should recommend similar companies such as Samsung, Intel, etc.
Team Information🌱🌲♻️🌿
Kevin Zhang (solo): performed data collection, data interpretation, model development, results visualization, and chatbot development
Instructions on how to set up and run our project🌱🌲♻️🌿
Updated code is in the master branch. Download the code from git. To generate companies and scores data file:
- Set up python environment v3.12
- Optional: set up jupyter lab and work through jupyter notebook
- Download packages from requirements.txt using pip
- Open terminal window
- Run 'python collect_news.py'
- Run 'python collect_statements.py'
- Run 'python collect_reports.py'
- Run 'python download_stopwords.py'
- Run 'python process_json.py'
- Run 'python clean_text.py'
- Run 'python score_calc.py'
- Run 'python visual_results.py' After all these steps, a csv file named company_similarity_results_bert.csv will be created in /data/output To set up the chat bot:
- Open terminal and cd to subfolder chatbot_env
- Run 'python app.py'
- Open http://127.0.0.1:5000/? in browser
- Select a company and click get score
Built With
- bert
- css
- html
- javascript
- jupyter
- newsapi
- python

Log in or sign up for Devpost to join the conversation.