-
-
landing page
-
-
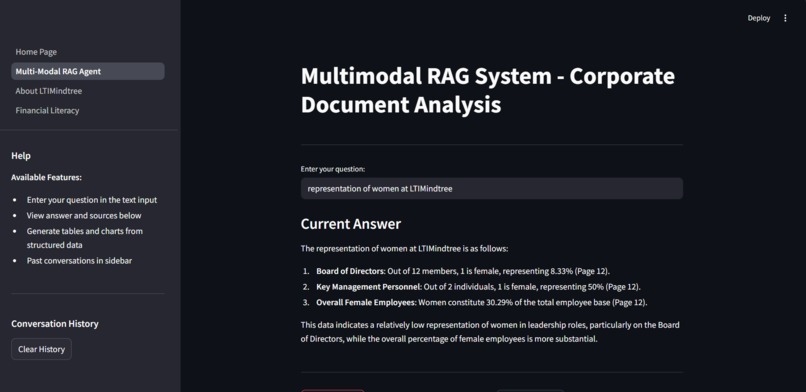
MultiModal RAG System
-

LTIMindtree Story and Analysis
-

financial literacy assistant





Inspiration
We were motivated by the widespread challenge of working with unstructured documents—files filled with text, tables, and images that are difficult to search through or extract meaningful insights from. Many businesses and organizations struggle with managing and understanding such data efficiently.
What it does
EpicRAG is a powerful solution designed to process and understand unstructured documents. It accepts files containing a mix of text, images, and tables, and intelligently breaks them down using a combination of Hugging Face and OpenAI models. The content is then used to train an OpenAI-powered chatbot, which can answer questions related to the document, enabling fast and structured information retrieval from even the most complex files.
How we built it
EpicRAG uses a hybrid chunking strategy to process documents and separate them into text, tables, and images. Text and tables are passed through the Hugging Face BGE-M3 model to generate vector embeddings. Images are processed using the OpenAI CLIP model to extract their vector representations. All embeddings are stored in a Chroma DB vector database, while the original file content is saved in a document database.
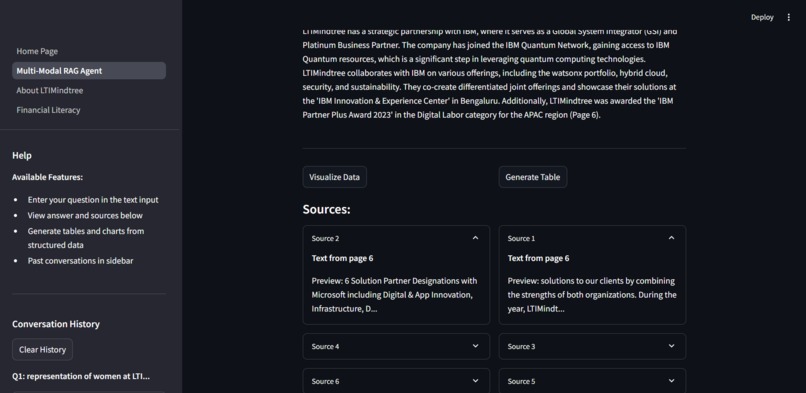
A custom retriever then pulls relevant information and metadata—including confidence scores, image paths, page numbers, and content descriptions—from both databases. This retrieved data is fed into an OpenAI chatbot, enabling it to answer user queries about the document with accuracy and context.
This chatbot is launched on a frontend developed using Streamlit.
Challenges we ran into
While not explicitly mentioned in the provided files, typical challenges for this type of system would include:
Properly handling and processing images from PDF documents Creating effective embeddings for both text and images Balancing retrieval time and answer quality Optimizing parameters such as text chunk count, image count, and temperature settings Integrating all components into a cohesive system Maintaining conversation context while keeping responses relevant
Accomplishments that we're proud of
The system has several notable accomplishments:
Successful integration of both text and image modalities in a RAG system Implementation of a parameter optimization framework that balances performance and quality Comprehensive evaluation metrics to measure system effectiveness Multiple user interfaces for different use cases Calculator tool integration for handling numerical queries Conversation history management for contextual follow-up questions
What we learned
The project demonstrates learning in:
Building effective multimodal retrieval systems Optimizing RAG parameters for best performance Evaluating RAG systems with meaningful metrics Balancing between retrieval speed and answer quality Working with advanced LLM APIs (Mistral AI) Creating effective interfaces for AI systems
What's next for EpicRag
Potential next steps could include:
Supporting additional document formats beyond PDFs Implementing more sophisticated image understanding Adding additional modalities (e.g., audio, video) Improving the optimization algorithms for better parameter tuning Creating more specialized versions for specific domains (e.g., financial, healthcare) Adding features for document comparison and summarization across multiple sources Implementing more advanced evaluation metrics for answer quality
Built With
- langchain
- multimodal-rag
- python
- rag
- streamlit




Log in or sign up for Devpost to join the conversation.