-
-
Home
-
Overview
-
All Cases
-
Review Issues
-
Quick Review
-
Swipe Fraud
-
Swipe Legitimate
-
Swipe Dismiss
-
Swipe AI
-
AI Summary
-
Case Details
-
Audit Logs












Inspiration
Traditional fraud monitoring is where efficiency goes to die. Risk analysts are routinely drowned in high-density, multi-column spreadsheets, forced to evaluate complex data structures under extreme time constraints. This fatigue leads to critical oversights: missing a malicious actor costs thousands in chargeback fees, while over-correcting blocks legitimate buyers and ruins customer trust.
We asked: what if triage felt less like a spreadsheet and more like Tinder? The same swipe mechanic that makes split-second decisions effortless in consumer apps turns out to be a perfect fit for fraud ops — right to approve, left to escalate, up for AI triage. Simple gestures, zero cognitive overhead.
What it does
FraudFrog re-engineers trust and safety workflows by replacing dense database grids with an ultra-fast, interactive Tinder-style triage queue.
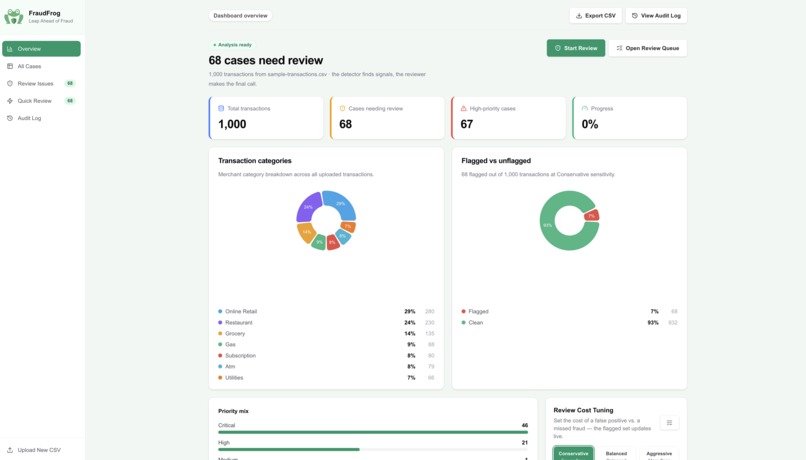
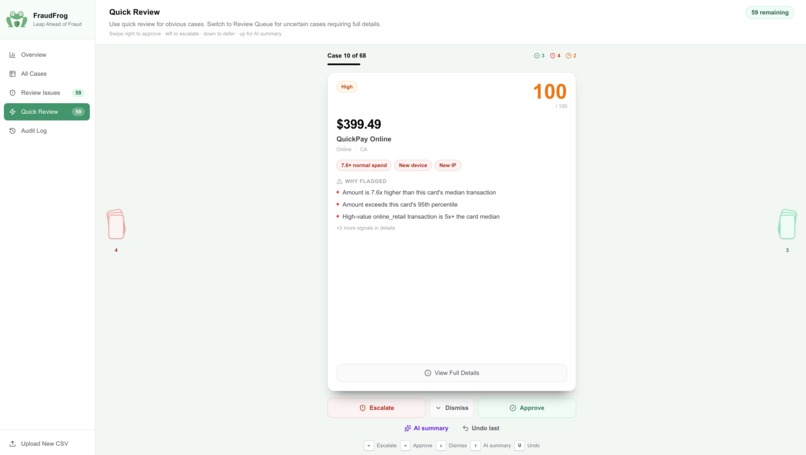
After ingesting an enterprise transaction CSV, our multi-layered Python engine processes the full ledger and outputs a deterministic threat score for every transaction. Reviewers work through flagged cases in two modes:
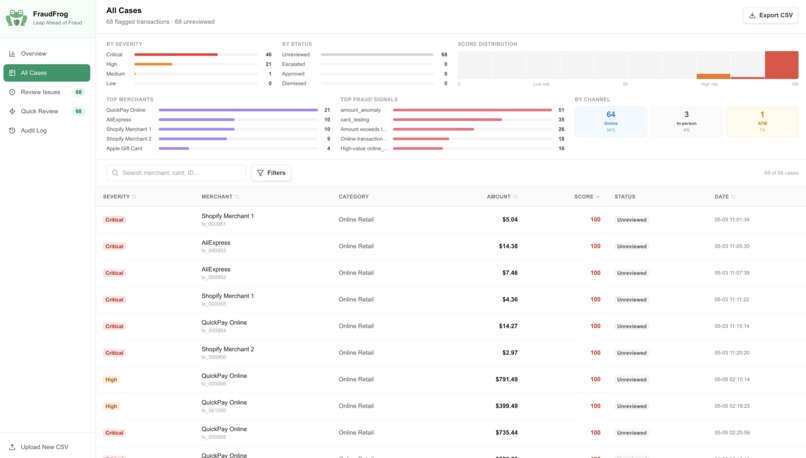
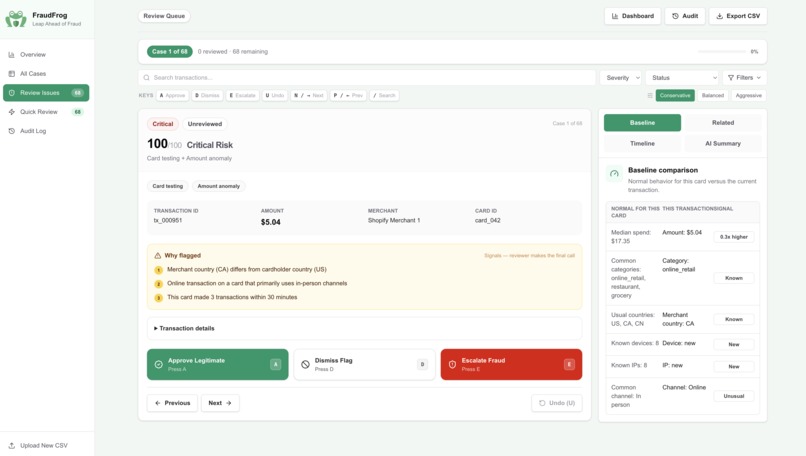
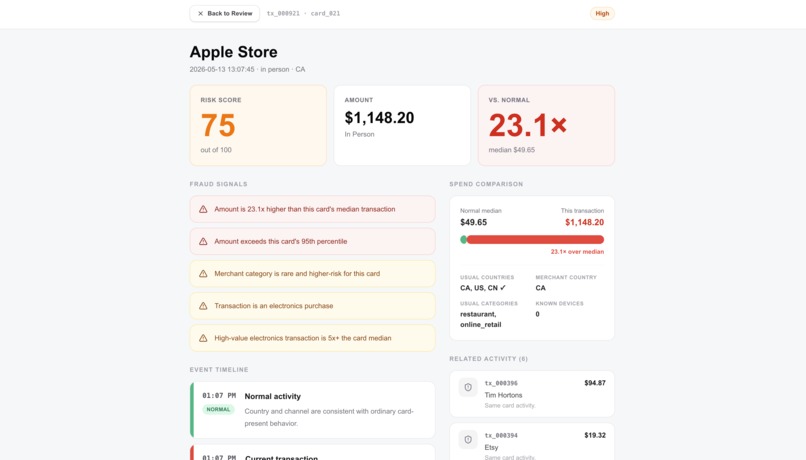
- Review Queue — full evidence view: score, severity, baseline comparison, related activity, timeline, and AI summary with a three-action verdict bar (Approve / Dismiss / Escalate)
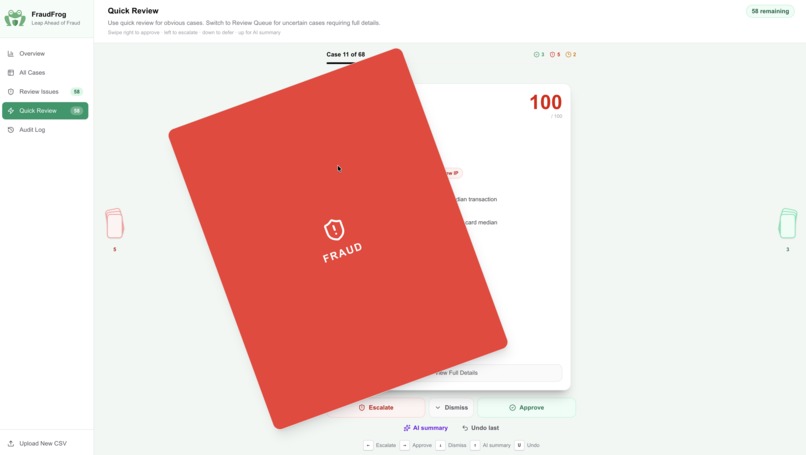
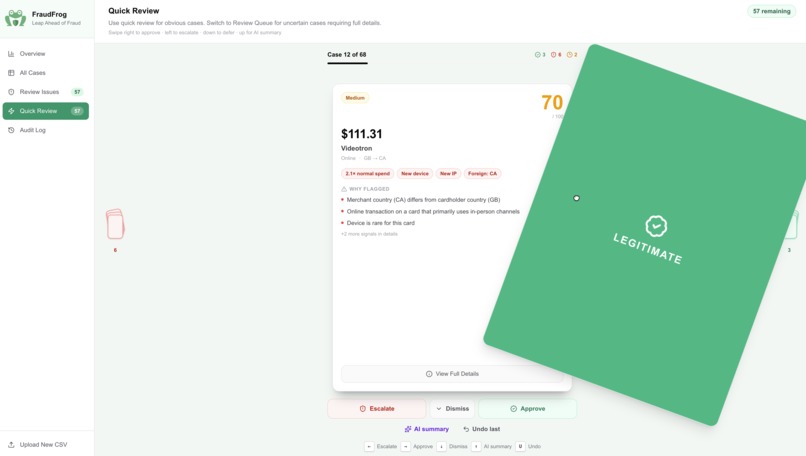
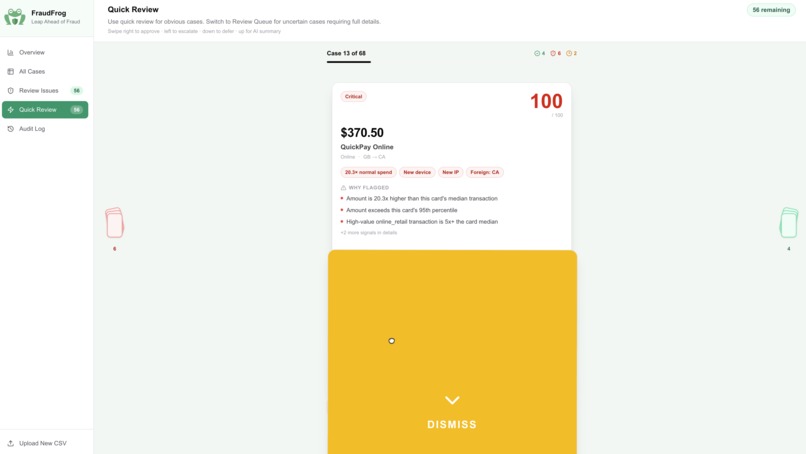
- Quick Review — swipe-card interface for obvious cases: swipe right to approve, left to escalate fraud, down to dismiss, up for AI triage
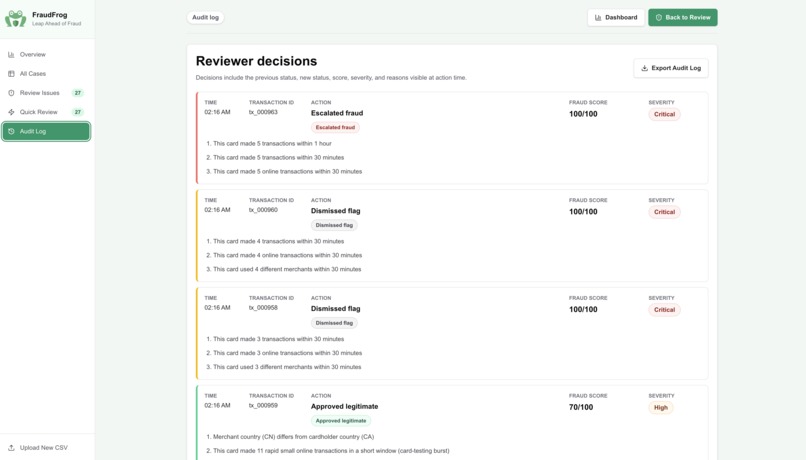
Keyboard hotkeys (A / D / E) mirror every swipe for maximum throughput. Every decision is logged with its score, severity, and the exact signals that triggered the flag.
How we built it
The Stack: Next.js 15 (App Router), TypeScript, Tailwind CSS v4, and Framer Motion for swipe physics and micro-interactions. The scoring engine is a pure Python pipeline (fraud_detector.py) invoked at analysis time via a Next.js API route — no intermediate files, scored output is piped directly to the frontend.
The Rules Engine
Before reaching the UI, every transaction is scored by an additive, explainable heuristic engine:
R = min( s * sum of all signal weights , 100 )
Each triggered rule contributes an additive penalty — graduated for continuous signals (e.g. amount anomaly scales in steps by ratio to median) and binary for discrete ones. The sensitivity multiplier s lets reviewers tune aggressiveness live:
s = 0.85 → Conservative
s = 1.00 → Balanced (default)
s = 1.15 → Aggressive
Key signal weights (selected):
| Signal | Weight |
|---|---|
| Amount ≥ 10× card median | +30 |
| Amount ≥ 5× card median | +20 |
| Card-testing burst (≥ 6 small online txns in ±1 h) | +60 |
| Card-testing burst (≥ 4 small online txns in ±1 h) | +45 |
| Small probe before large charge (2 h window) | +30 |
| Gift card ≥ $500 from new device/IP | +30 |
| 5+ unique cards at same merchant in 2 h | +30 |
| Device shared across 3+ cards | +25 |
| IP shared across 3+ cards | +25 |
| 5+ card txns in 1 h | +25 |
| 3+ small probes in 1 h | +25 |
Risk is then classified using both the score and a strong signal count S (the number of triggered primary fraud signals):
R ≥ 85 and S ≥ 2 → Critical
R ≥ 70 and S ≥ 1 → High
R ≥ 40 → Medium
R < 40 → Low
The dual condition prevents stacked weak signals from inflating severity — you need both a high score and at least one confirmed primary fraud pattern.
Low-value dampening caps scores for small transactions with no strong signals (amount < $25 → cap 35; amount < $50 → cap 45), preventing normal subscriptions from surfacing as fraud.
Challenges we ran into
State & Animation Synchronization: Building a queue optimised for high-speed swiping caused race conditions early on. Rapid hotkey inputs triggered state updates before Framer Motion could finish executing exit animations, causing cards to clip or get stuck. We implemented synchronous boundary locks within our custom React hooks to isolate array shifts and preserve fluid animations.
Progressive Disclosure on 11 Columns: Fitting an entire 11-column dataset onto a clean card interface was a massive UX challenge. We adopted a rigorous progressive disclosure model: high-signal data points (amount, merchant, severity score) live on the card face; cardholder baselines sit pinned to a contextual sidebar; and deep technical footprints — IP addresses, device IDs, cross-card patterns — stay hidden behind a tabbed evidence panel until the analyst needs them.
Symmetric Burst Window: Traditional backward-only velocity windows miss the first 2–3 probes of a card-testing burst — they score near zero because the trailing window is still empty. We engineered a symmetric ±1 h window (card_small_online_burst_1h) that flags every transaction in the burst, including the first probe, with zero additional false positives.
Explainability Without Labels: The dataset provides no ground-truth fraud labels, making supervised ML impossible without training on guesses. We engineered fully explainable rule-based scoring — every flag surfaces a concrete, reviewer-facing reason — making the system auditable and credible in a human-review context.
Accomplishments that we're proud of
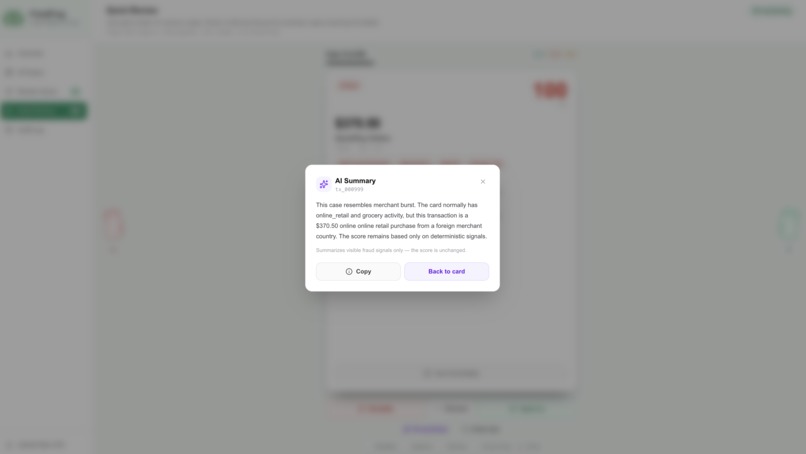
AI Triage for Ambiguous Cases: Instead of forcing reviewers to manually debate mid-risk transactions, we integrated an AI Triage Agent. The agent pulls transaction metadata, evaluates it against the cardholder's full behavioral baseline, and returns a concise plain-English risk summary directly on the card — giving analysts a second opinion without interrupting their flow.
Calibrated Precision/Recall: Against the reconstructed fraud set (~70 of 1,000 rows across four confirmed fraud patterns), Balanced mode achieves F1 = 0.966 (precision 0.93, recall 1.00). The symmetric burst window was the decisive improvement — recall jumped from ~0.79 to 1.00 with no added false positives.
| Mode | λ | Precision | Recall | F1 |
|---|---|---|---|---|
| Conservative | 0.85 | 0.96 | 0.93 | 0.942 |
| Balanced | 1.00 | 0.93 | 1.00 | 0.966 |
| Aggressive | 1.15 | 0.83 | 1.00 | 0.909 |
Network-Wide Session Immunization: We built a live feedback loop. When an analyst repeatedly dismisses the same fraud pattern as a false positive (default: twice), the system learns it is likely noise, de-prioritises remaining flags matching that pattern, and surfaces a banner explaining what it learned — reducing cognitive fatigue as the session progresses.
Full Audit Trail & Export: Every decision is recorded with its timestamp, fraud score, severity, previous status, and the signals visible at decision time. A reviewed CSV (with risk_score, severity, is_fraud, review_status, detected_patterns, and reasons appended) and the full audit log are exportable with one click.
What we learned
Building FraudFrog reinforced the massive power of human-in-the-loop AI systems. In high-stakes fintech environments, AI shouldn't completely replace human intuition — its true purpose is to eliminate noise, manage information architecture, and empower analysts to make accurate, cost-aware decisions at maximum velocity. Explainability is not optional: every flag needs a reason a human can verify, override, or learn from.
What's next for FraudFrog
We plan to scale our cross-card network aggregations into a decentralised ledger, allowing independent merchants using FraudFrog to instantly share blacklisted device and IP fingerprints globally. We also want to integrate real-time API webhooks, transforming our static CSV-triage tool into a fully live, inline payment gateway guard — scoring transactions as they arrive and routing them to the reviewer queue in milliseconds.



Log in or sign up for Devpost to join the conversation.