-
Graph
-
Eye-tracking Setup
-
Lesson View
-
Authentication
-
Onboarding





Inspiration
Throughout the United States and internationally, there is a huge disparity in the educational opportunities afforded to underrepresented and underfunded communities, leading to significant gaps in academic achievement and access to higher education. These disparities are often compounded by factors such as socioeconomic status, race, and geographic location, which can limit the resources available to students, including access to quality teachers, extracurricular programs, and advanced coursework.
On the other side of this problem, both primary/secondary schools and higher learning institutions alike are in desperate need of qualified educators and tutors to teach the next generation, but there is a shortage of teachers available, worsening the aforementioned problem as well as hurting students. When class sizes increase, the level of individual help and resources available to students diminish, leading students across the globe behind. I think we can all agree, at least Owen and I can, that it's easy to feel defeated in classes with hundreds of your closest peers, with little to no support available from teachers just because they are spread to thin. Our goal with GuideStone is to both empower students to truly understand the material they seek to learn, as well as provide a solution for educational systems who want to provide one-on-one teaching/tutoring to their students to see them succeed but don't have the resources or employees to do so.
What it does
GuideStone is an AI education platform that seeks to reinvent tutoring for students just like us. With Rocky as your tutor (the GuideStone mascot) you don't deal with the problems you often experience with services like Khan Academy or platforms like it. (OpenStax, IXL, etc.) These platforms are great, and we have used them countless times, but they are definitely a one-size-fits-all solution, when we all know that each and every one of us has our own learning preferences and we don't have to settle in the world of AI!
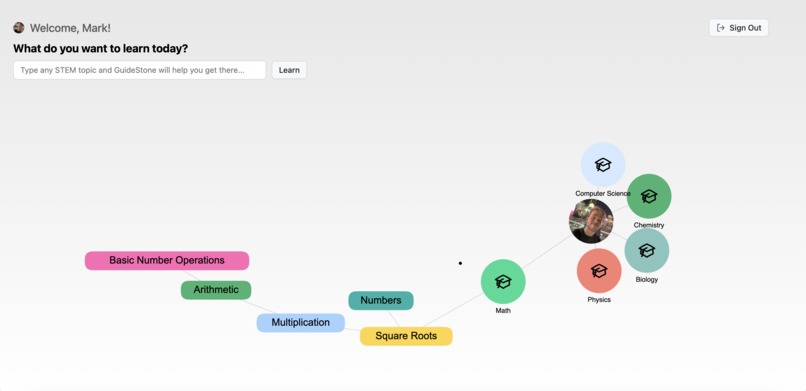
Introducing GuideStone! We each have our own educational path, and GuideStone understands that. We build out a graph for each and every user that expands as you learn automatically. For example, if you want to learn integrals - but haven't yet learned derivatives, our platform will first generate a lesson on deviates to make sure you have a full grasp on the topic.
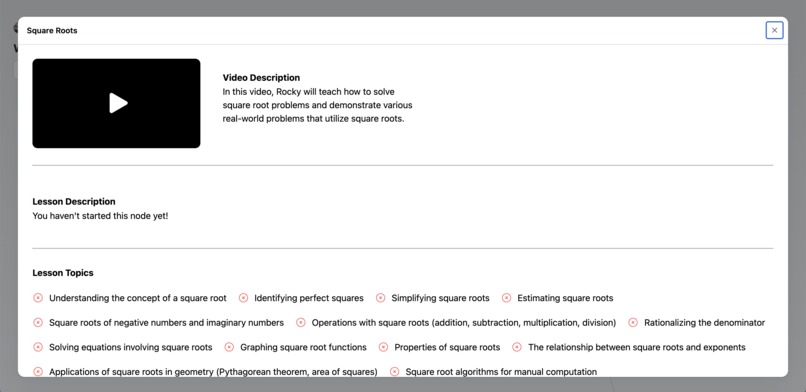
I mentioned lessons, but you might be wondering.. what does a lesson look like on GuideStone? Well, every lesson comes complete with a video & quiz to test your understanding. How is that better than the earlier mentioned education platforms? Well... Generative AI of course!! Every video on our platform is generated from scratch by GPT-4. We'll dive into how a bit later, but the ability to create videos on topics for a specific user allows us to do some really special things like modifying example animations to be about things you care about and resonate with like hobbies/interests/passions.
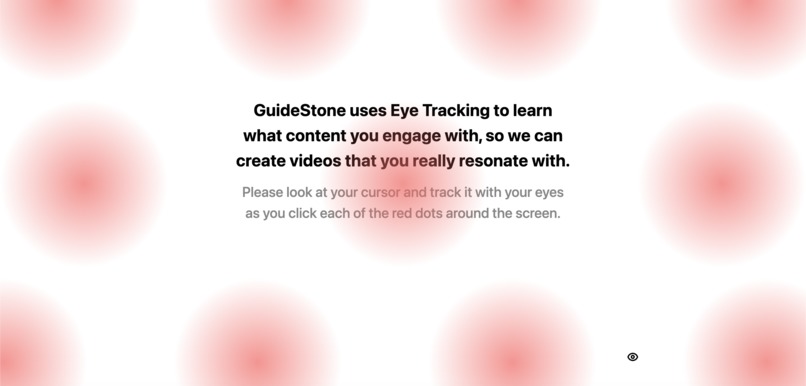
I also mentioned that GuideStone was self-improving. How does that work? Well, we incorporated a combination of eye-tracking & quizzes to modify your generated videos based on what kind of videos work to better your understanding. While you watch the video, GuideStone is gathering data on what parts of the video you are paying the most attention to without any required input from you. Then, when you finish the video, we use this eye-tracking data to both surface general lesson content, but also specific content we think you might have missed during the video. This creates a really special experience and helps to bring education directly to you like if you had a one-on-one tutor.
We use an agentic arcitecture to then analyze this data, and plan a form of action on how to create better videos (one's which perform better on attention & quiz score) for you in the future. This is something that no other education software on the market can offer, and it allows for a much more fulfilling experience.
However, that is not the only way that GuideStone is self-improving, we also designed and implemented our own memory architecture so that we are able to remember and track reasons why results were sub-par or even executions failed in the past, and improve upon this in the future. Way more information about this memory architecture is available in 'Things we are Proud of'.
How we built it
We built GuideStone using a combination of cutting-edge software both on the frontend and backend, all of which is hosted on a combination of Azure to ensure quick production of . Let's dive into how both work:
Backend:
- Azure Function App Services to handle all of our cloud infrastructure, including: planning & generating videos, exposing endpoints to the frontend to access Graph & Postgres Databases
- Azure Apache Gremlin Cosmos DB Graph to manage user's lessons, these graphs are recursively added to by custom-written GPT-4 output parser to manage new nodes and edges between the nodes.
- PostgreSQL DB to manage user information, lesson information, recommendations for future video improvements, and more
- GPT-4 for many different reasons, including: scene planning, code generation, graph generation, graph traversal, and more.
- Langchain was at the center of a lot of our LLM usage, providing us an easy layer with which we could add output parsing, agentic bhavior, and more. We also <3 LangSmith, it made debugging LLMs a lot easier.
- ElevenLabs for Text-to-Speech
Now let's dive in a bit more detail into how video generation & personalization works:
- We have a listener that is in charge of looking for new/modified nodes, and is responsible for putting these nodes in queue to generate lessons & videos for.
- Video generation start's with an agent that is tasked with planning out a video, a "director" of sorts, who splits the lessons into scenes, going into detail about what should be displayed on the screen. This agent is also in charge of developing a script which is going to be read aloud by ElevenLabs TTS later in the process.
- In parallel, these scenes are passed to another agent whose job it is to turn these scene descriptions into Manim (an animation library) code. We noticed in our testing that this agent would make mistakes causing the animation to fail, so we put it in a situation where the agent had a critique that responds to it's work and points out errors, causing the initial agent to rethink it's original code.
- At the same time as the Manim code generation, we pass the script to ElevenLabs to turn this text into speech.
- Once we have, both the Manim code and speech generations, we run code first to render the code into animations and then using FFMPEG, we put them together formulating the complete video, which is then put into an Azure storage bucket.
- Once a user finishes a lesson video & quiz, their results (both eye-tracking & quiz) are sent to the backend for processing. If a user get's a question wrong, a new lesson is generated focusing on this topic and any topics it was detected they might have missed.
- Regardless of whether they get the answers right or wrong, another agent is dispatched in order to reflect on the quality of the lesson. This agent questions the videos pace, scene types, animation types, etc. all in order to create better, more educational future videos for the user.
Frontend:
- React for Frontend Framework
- WebGazer.js for Eye-tracking
- react-force-graph for Graph Creation
- Github Primer for UI
- Google OAuth for Authentication
- When a user is created, they go through an eye-tracking setup process where they are asked to follow their cursor with their eyes and click gradient circles placed around their screen. This entire process takes about 10-15 seconds, yet in the background is training a regression model on every click and by the end we have enough accuracy for our purpose. This model is then saved in the user's localstorage so users do not have to complete this setup every time.
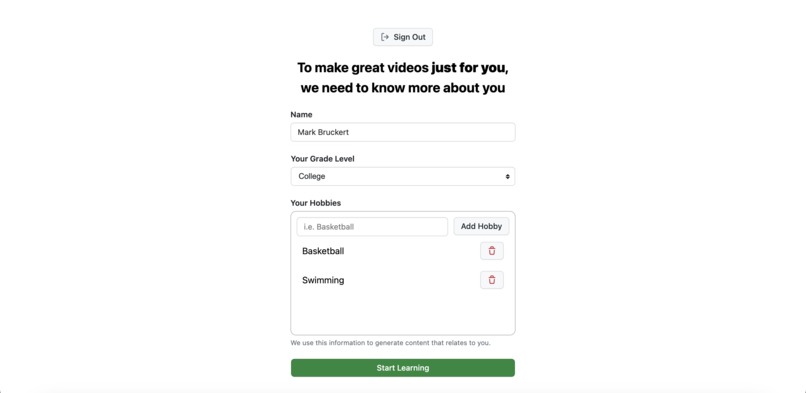
- The user also is asked for their hobbies/interests at the next step of onboarding, which then generates DALL-E assets and places them in the user's videos in order to make the videos more engaging, relatable, and personable.
- When a user watches a video, their eye position is tracked multiple times a second and is paired with the timestamp of the video for processing on the backend. Additionally, the number & timestamps of pauses & rewinds are gathered and sent to the backend for additional data analysis.
Challenges we ran into
We ran into MANY problems - but the following were the biggest time-sinks:
- Recursive Graph Building - Our agent had a lot of problems connecting new nodes and populating parents in a way that connected with existing nodes, and this required A LOT of prompt engineering to improve. This ended up being the major downfall of our product, because while it worked sometimes, it is very inconsistent.
- Graph Rendering - We tried a number of solutions for this before we finally ended up using (discovering) the right solution. At one point, we had even written our own physics engine to simulate the graph in a package made for flowcharts, but found that to be too unsustainable.
Accomplishments that we're proud of
We designed and build out a memory architecture that we are really proud of. We used the critic agent to enrich the logs before they wen't into memory, highlighting errors which could be useful in future runs. We very quickly saw a HUGE improvement in video output quality once we implemented this memory architecture. We knew that fine-tuning the model would require more high-quality data than we had access to or had time to generate/find, so instead we took advantage of the fact that while generating an answer to a question is a high-entropy task, verifying that answer is a much lower-entropy task by adding a critical agent posing as a user to the agent loop. We then summarized the entirety of the execution at the end of each run and saved all of the improvements that the critics feedback were able to cause. Eventually, we were able to disable the critic entirely, massively increasing speed while maintaining the same level of quality, which would not have been possible with GPT-4 without this context.
I think also getting over the challenges listed above we are also really proud of- especially since we only got about 3 hours of sleep over the weekend :)
What we learned
We learned A LOT from Treehacks. One takeaway we both agreed on is how valuable incorporating long-term memory with a critic across runs to an LLM can be to performance. But here are some things we each were super excited to have learned:
Mark:
- Graphs are fun, but making them in the frontend is harder than it looks, especially if you try to do it yourself
- What Owen said
Owen:
- "I learned the reason that most apps only have one database"
What's next for GuideStone
GuideStone was already a continuation of an idea from a previous hackathon (idea transformed into something completely different, no code crossover whatsoever), so we are excited to see where it can go from here!
Built With
- azure
- elevenlabs
- gpt4
- gremlin
- langchain
- manim
- openai
- postgresql
- python
- react
- vercel







Log in or sign up for Devpost to join the conversation.