-
-

Landing Page
-
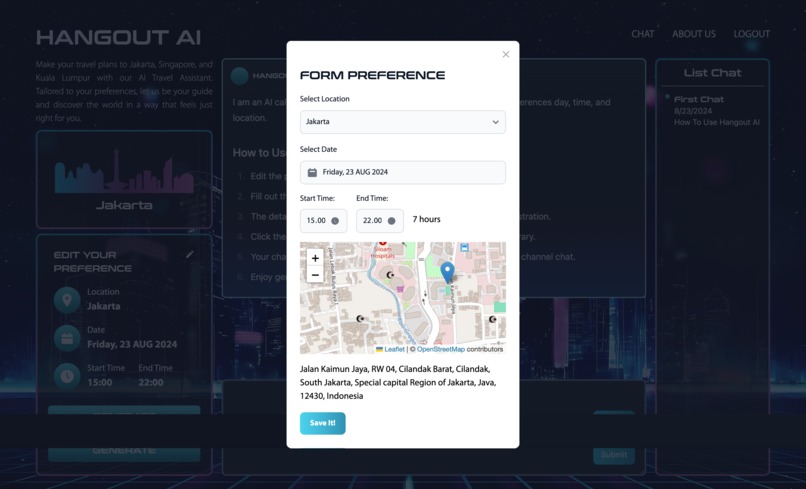
Preferences Form
-
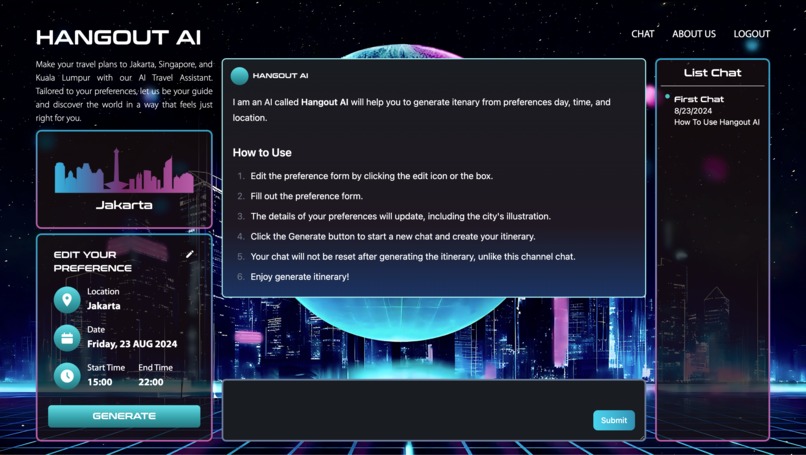
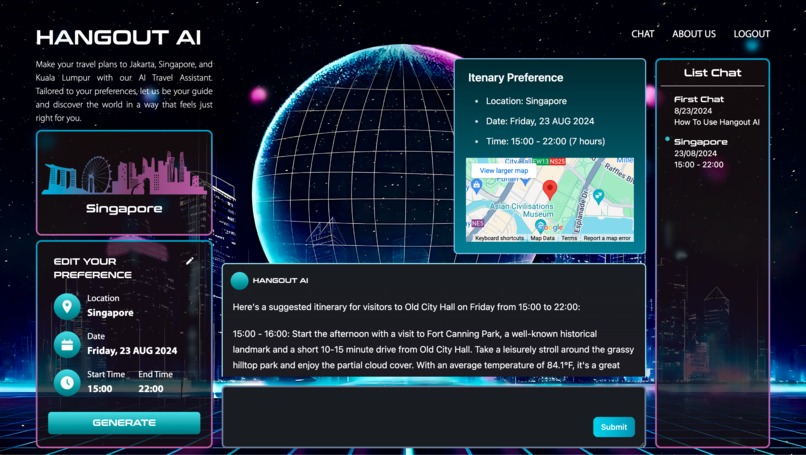
Chat Page
-
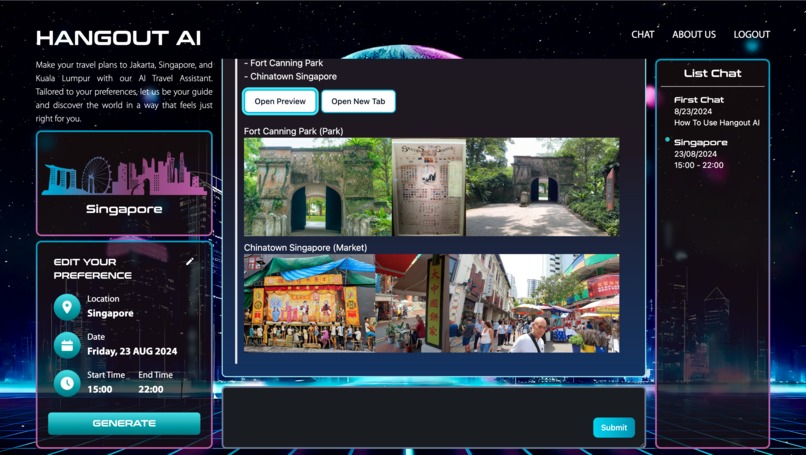
Chat Page with Preview Location (TiDB Serverless Implementation Endpoint)
-
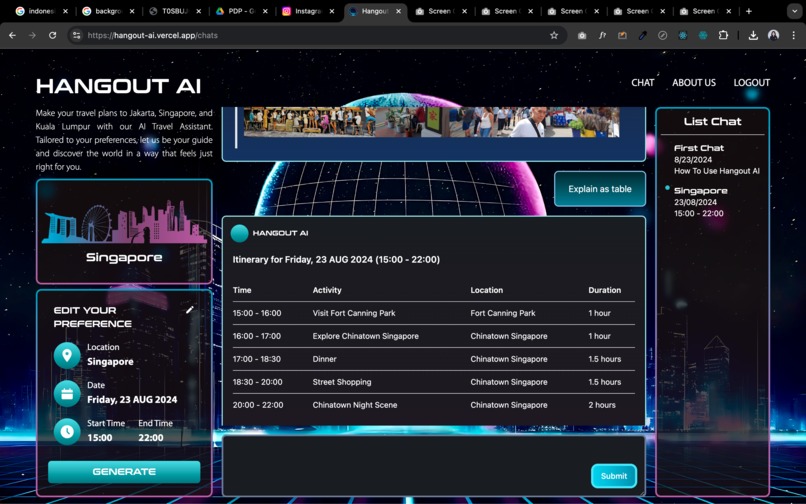
Chat Page (Ask AI to Explain with Table)
-

Landing Page Mobile
-
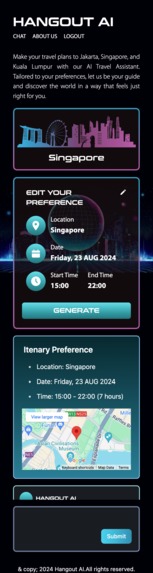
Chat Page (Result) Mobile
-

Chat Page (Loading) Mobile
-
-
System Flow Hangout AI
-
RAG System Tech Stack & Flow
-
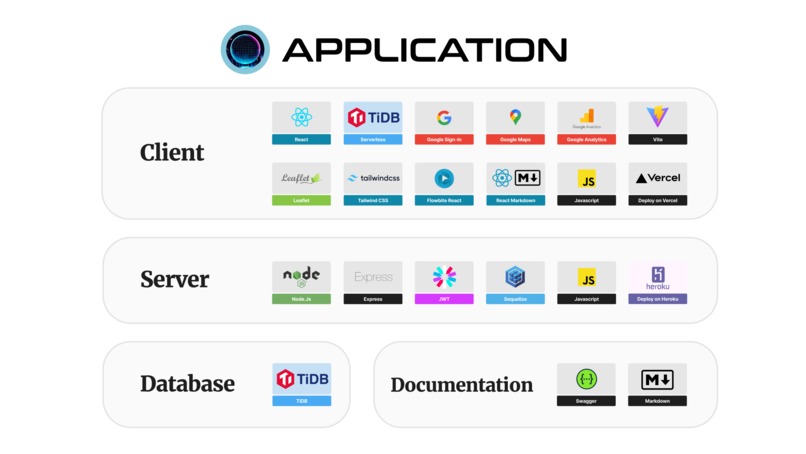
Application Tech Stack & Flow
-
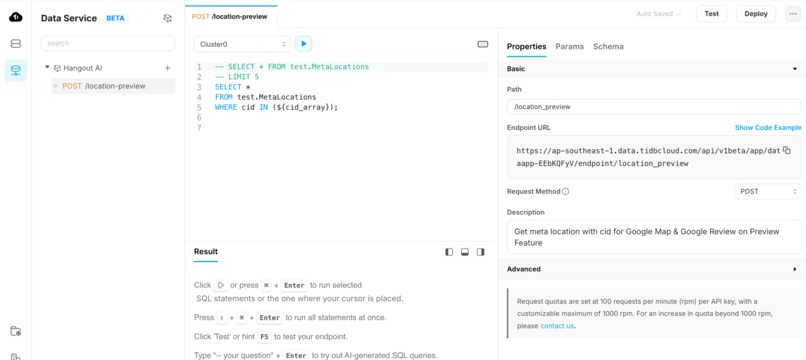
Location Preview Endpoint (TiDB Serverless Implementation)













Table of Contents
- Table of Contents
- Inspiration
- What it does
- How we built it
- TiDB Utilization Overview
- Challenges we ran into
- Accomplishments that we're proud of
- What we learned
- What's next for Hangout AI
- Hangout AI Developers
Inspiration
The inspiration of Hangout AI came from our habit of exploring cafe in Jakarta Timur (Indonesia) as WFC person (Work From Cafe) who keep cafe hooping we do had discourse that is well planned but not implemented in reality, but we manage to try competition together with our WFC friends. But so on we had the same interest on plan to hangout in new place with interactive activity in Jakarta, Singapore, and Kuala Lumpur. The idea of using AI to curate personalized itineraries felt like the perfect way to bring this vision to life.
What it does
Hangout AI generates personalized travel itineraries based on user input, location, date, and weather conditions. The service leverages a Large Language Model (LLM) integrated with Retrieval-Augmented Generation (RAG) to enhance the accuracy and relevance of recommendations. By retrieving and utilizing relevant data from a vector database, Hangout AI provides tailored travel suggestions and visual previews of locations, ensuring users receive highly customized and insightful travel plans.
Our target audience is the general public, including travelers, tourists, and adventure seekers who want a personalized and seamless travel planning experience.
App Category for TiDB Future App Hackathon 2024 :
- Recommendation System
- Retrieval-Augmented Generation (RAG)
How we built it
- LLM Service: Integrated the Groqcloud Llama3-70B-8192 model for generating travel itineraries.
- API Server: Developed using FastAPI and Node.js for handling user requests and interactions with the LLM.
- Client Application: Built with React, Vite, and Tailwind CSS to create an interactive and responsive user interface.
- Database: Utilized TiDB and PingCAP Vector MySQL for efficient data management and retrieval.
- Data Integration: Employed Golang and Google Maps scraper for data collection and Python with Pandas for data cleaning.
- Deployment: Used Vercel, Heroku, and Personal VPS for hosting and deployment.
Data & LLM Service
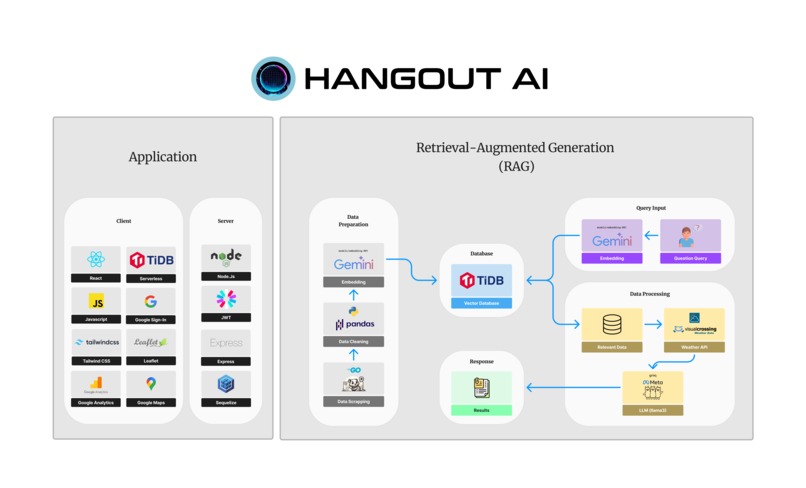
The system architecture is composed of several key components:
- FastAPI: A Python-based web framework used to build the API endpoints and serve the itinerary generation service.
- LLM (Groq Llama3-70B-8192): A large language model used to generate the itinerary based on the input prompt and embedded data.
- Embedding Model (Gemini embedding-001): Used for embedding location and weather data into a format that can be effectively processed by the LLM.
- TiDB (Vector DB): A distributed, MySQL-compatible database that stores vectorized data for quick retrieval and similarity search.
- Google Maps Scraper: Scrapes location data from Google Maps for use in the itinerary.
- Pandas: A Python library used for cleaning and processing scraped data before embedding.
- Docker: Used for containerization and deployment of the LLM service.
Application
The Hangout AI application is built using a modern tech stack to deliver a seamless user experience:
1. Client Application
- React JS: Frontend framework for building the user interface.
- Vite: Build tool for fast and efficient frontend development.
- Tailwind CSS: Utility-first CSS framework for styling the application.
2. API Server
- Node.js: Backend runtime environment for the API server.
- Express.js: Web application framework for building the API endpoints.
3. Database
- TiDB: Distributed, MySQL-compatible database for storing user profiles, location vectors, and chat records.
TiDB Utilization Overview
- Using RAG with PingCAP Vector MySQL Database
- Using TiDB Serverless for MetaLocations
- Using MySQL Database from TiDB
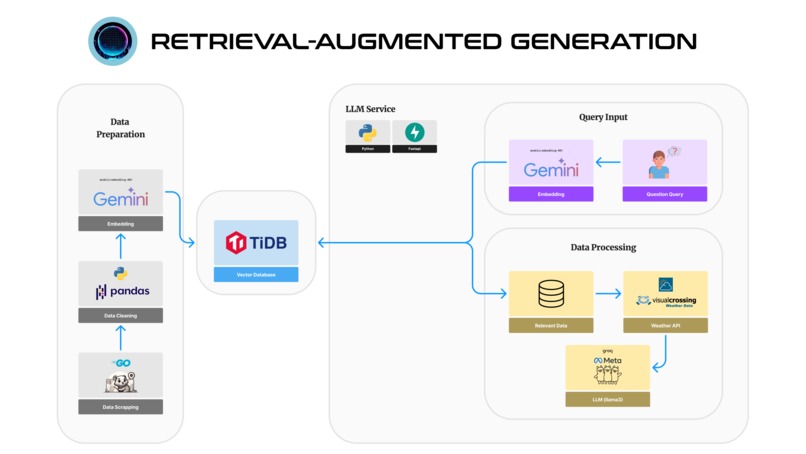
Using RAG with PingCAP Vector MySQL Database
RAG (Retrieval-Augmented Generation) is a technique where a model retrieves relevant data from a database or knowledge base to enhance the quality and relevance of generated outputs. In the context of Hangout AI, we use RAG with the PingCAP Vector MySQL Database to efficiently process and retrieve location-based information that improves the accuracy and personalization of travel itineraries.
Key Steps:
- Data Embedding:
- Location data (e.g., descriptions, reviews, metadata) is embedded into vector representations using models like the Gemini embedding model.
- These vectors are stored in the PingCAP Vector MySQL Database for efficient similarity searches.
- Retrieval Process:
- When a user requests an itinerary, relevant location data is retrieved by performing similarity searches in the vector database.
- This data is then fed into the Large Language Model (LLM), enhancing the contextual understanding and output relevance.
- Itinerary Generation:
- The retrieved data enriches the LLM's prompts, leading to more accurate and tailored itineraries based on user preferences, current weather, and other dynamic factors.
By leveraging RAG with PingCAP Vector MySQL Database, Hangout AI can generate more informed and contextually appropriate itineraries, ensuring that users receive recommendations that are both personalized and relevant.
Using TiDB Serverless for MetaLocations

TiDB Serverless is used in Hangout AI to manage and retrieve MetaLocations data, which is not sensitive and is utilized for visual itinerary previews integrated with Google Maps and Google Reviews.
Key Features:
- Scalable Data Management:
- TiDB Serverless efficiently handles large datasets of MetaLocations, ensuring that the service remains responsive even as the volume of data grows.
- This flexibility allows Hangout AI to scale its location database without worrying about underlying infrastructure.
- Integration with Google Maps and Reviews:
- MetaLocations stored in TiDB Serverless are used to provide visual previews of itinerary locations.
- The integration with Google Maps enables users to view detailed maps, directions, and nearby attractions.
- Google Reviews provide additional insights, helping users make informed decisions about their travel plans.
- Non-Sensitive Data Handling:
- Since MetaLocations data is non-sensitive, it can be freely shared and used for public-facing features without compromising user privacy.
- This makes TiDB Serverless an ideal solution for managing this type of data, balancing performance with security.
By utilizing TiDB Serverless for MetaLocations, Hangout AI ensures that users can preview their itineraries visually and access detailed information about each location, enhancing the overall travel planning experience.
Using MySQL Database from TiDB
we delve into how TiDB’s MySQL compatibility enhances data management within the Hangout AI project efficiently manage user profiles, location information, and chat records using Sequelize. TiDB's scalable nature ensures that as data volumes grow, the system remains performant and responsive, while the MySQL compatibility allows for seamless integration with existing tools and libraries. This setup provides a powerful and flexible solution for handling diverse data types essential for generating personalized travel itineraries.
Key Features
- User Data Management:
- Purpose: Efficiently handle user profiles, including personal details and authentication.
- Schema: Includes fields such as
id,name,email,image, and timestamps (createdAt,updatedAt).
- Location Data Management:
- Purpose: Manage and store information about various travel locations.
- Schema: Includes fields like
id,title,address,latitude,longitude, and additional metadata.
- Chat Data Management:
- Purpose: Store interactions between users and the AI, including messages and metadata.
- Schema: Includes fields such as
id,name,messages,address,latitude,longitude, and user associations.
- MySQL Compatibility:
- Advantage: Utilize TiDB’s MySQL protocol support to seamlessly integrate with Sequelize for data management.
- Scalability:
- Benefit: TiDB’s distributed nature ensures scalability and efficiency in handling large volumes of data.
Challenges we ran into
- Different programming languages: We have different programming language preferences. Although Ayu understands Python for research, she is not yet proficient in implementing it as a REST API and is more confident with JavaScript. Similarly, Lutfi requires more time to convert all implementations into JavaScript with the stack we use and will continue exploring Python. Therefore, we decided to divide the work according to our responsibilities, resulting in three repositories:
hangout-client,hangout-server(JavaScript), andhangout-llm(Python). These repositories have been merged into a main repository calledhangout-ai. - RAG & Vector Database: Integrating RAG with the vector database required management of data retrieval and embedding processes, and optimizing performance to ensure timely and accurate itinerary generation proved challenging.
- Data Integration: Ensuring seamless integration between various data sources and the LLM.
- Scalability: Managing large datasets and ensuring the system remains responsive under high load.
- Real-Time Processing: Providing timely and relevant itinerary recommendations based on dynamic user inputs.
- User Authentication: Implementing secure and reliable authentication using OAuth and JWT.
Accomplishments that we're proud of
- Personalized Itineraries: Successfully created a system that generates highly personalized travel recommendations.
- Scalability: Implemented a scalable solution using TiDB for handling large volumes of data.
- User Experience: Developed a responsive and user-friendly client application with seamless integration of external APIs.
- Integration: Integrated multiple technologies and APIs to deliver a comprehensive travel planning tool.
- Completing a project from start to finish in 2 weeks: From ideation, design, and exploration to coding and deployment, all within 2 weeks and with only two people. Implementation was supported by various AI tools for design references, text copyright, and more, but the main development was driven by human ideas and decisions (of course).
What we learned
- Integration of RAG with Vector Databases: We learned the intricacies of combining Retrieval-Augmented Generation (RAG) with a vector database to enhance the personalization and accuracy of travel itineraries. This taught us the importance of optimizing data retrieval and embedding processes for real-time applications.
- Data Management and Scalability: We gained valuable experience in managing large datasets effectively, especially in a dynamic environment where scalability and performance are crucial.
- Cross-Platform Collaboration: Building this project involved integrating multiple technologies and frameworks across different platforms. This improved our understanding of cross-platform compatibility and the challenges associated with it.
- User-Centric Design: We learned the importance of designing with the user in mind, particularly in providing a seamless and intuitive user experience that integrates external data sources dynamically.
- Leveraging AI and ML in Practical Applications: We explored practical applications of AI and machine learning, specifically in enhancing user experiences by providing personalized, data-driven recommendations.
What's next for Hangout AI
- Feature Expansion: Adding new features such as additional location data sources, advanced filtering options, and more detailed itinerary customization.
- Performance Optimization: Improving system performance and response times based on user feedback and usage data.
- User Feedback: Incorporating user feedback to refine and enhance the overall user experience.
Hangout AI Developers

Built With
- docker
- express.js
- fastapi
- gemini
- golang
- google-analytics
- google-maps
- heroku
- javascript
- leaflet.js
- llama3
- llamaindex
- llm
- mysql
- node.js
- pandas
- python
- rag
- react
- react-markdown
- responsive
- sequelize
- swagger
- tidb
- tidb-serverless
- tidb-vector-db
- vercel
- vite
- weatherapi











Log in or sign up for Devpost to join the conversation.