-
-
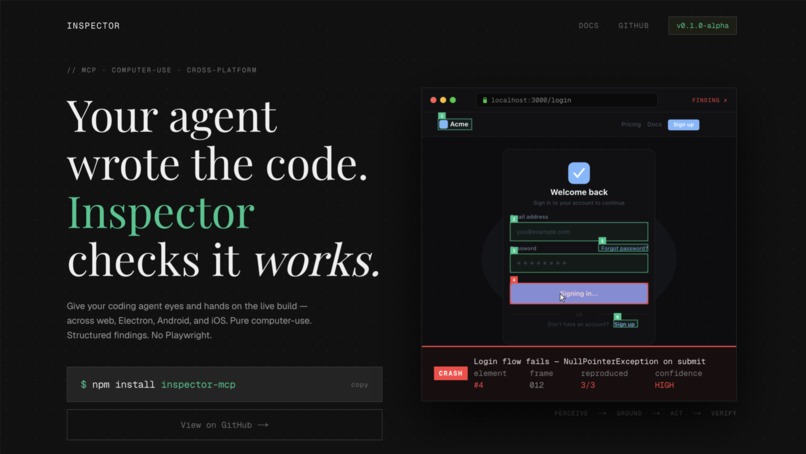
Landing page
-

-

-
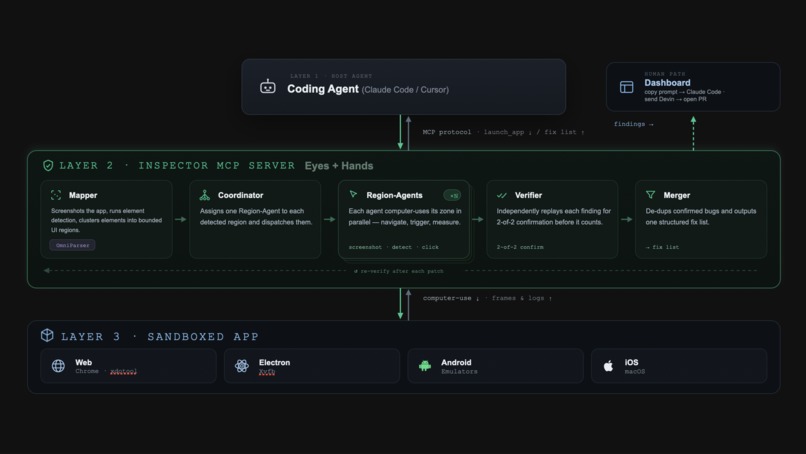
High level architecture
-
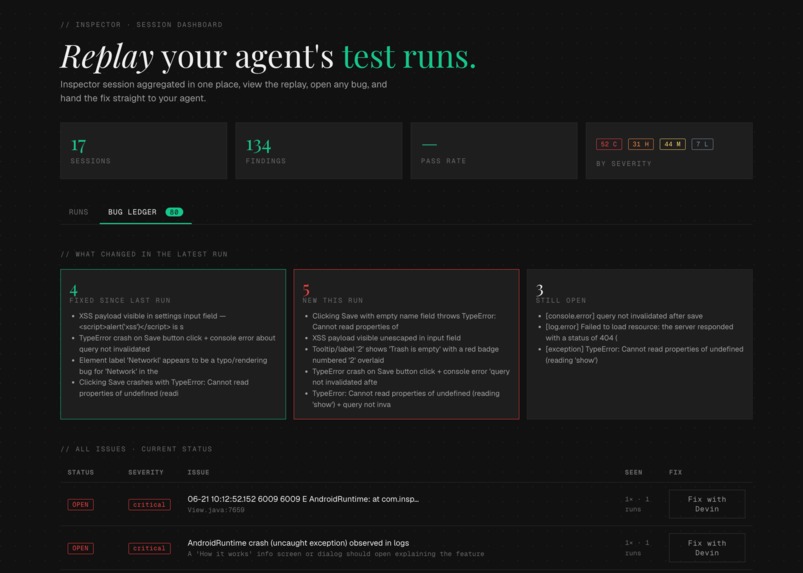
View bugs and errors on the bug ledger on dashboard
-
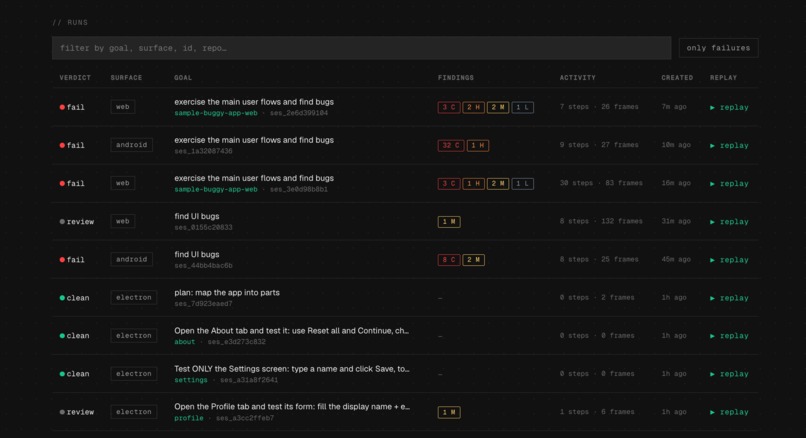
View past agent runs on dashboard
-
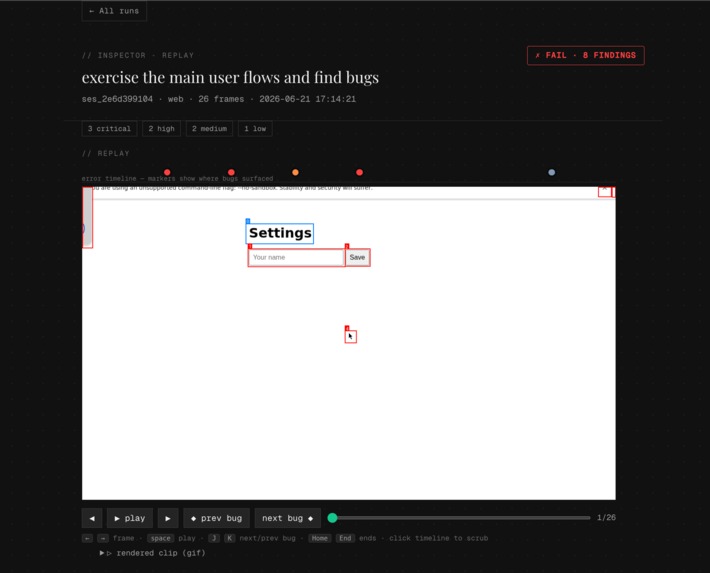
View computer-use replays on dashboard
-
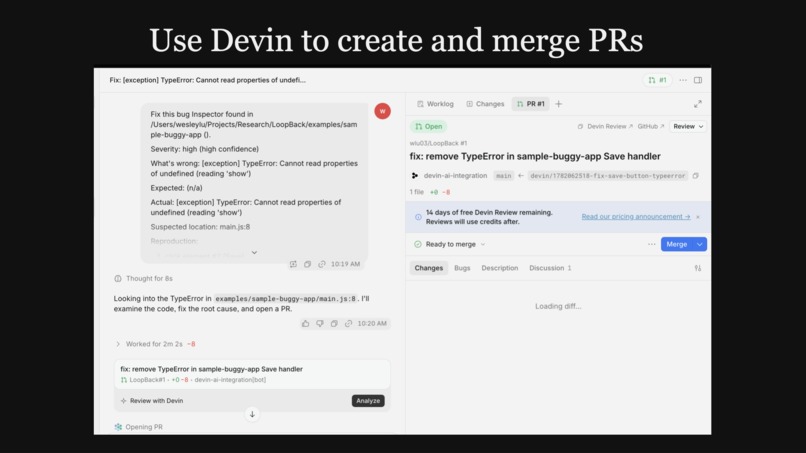
Compatible with Devin!








Inspiration
AI coding agents made developers 100x faster, but bug rates are up 41%. The problem is simple: your agent writes the code, then hands it back to you. You launch the app, click around, find what's broken, describe the bug, and wait for a fix. You are the QA engineer. We wanted to close that loop. Let the agent see its own work, find the bugs, and fix them without a human in the middle.
What it does
Inspector is an MCP server that gives your coding agent (Claude Code, Cursor, or any MCP client) the ability to autonomously test the app it just built. It launches your app in a cloud sandbox, uses computer-use to operate it like a real user (screenshots, element detection, clicks), and maps the UI into regions. Each region gets its own agent that tests in parallel. Findings are independently verified with 2-of-2 replay agreement, de-duplicated, and sent back as a structured fix list. The coding agent patches the code and Inspector re-verifies.
It works across web, Electron, Android, and iOS through pure pixel-level interaction. Anything that renders to a screen, Inspector can test. Inspector surfaces the errors found back to the coding agent in the terminal. Additionally, from the dashboard, you can copy a prompt with full context to paste into Claude Code, or send Devin to open a PR automatically.
How we built it
The core is a Python MCP server built on FastMCP that exposes tools like launch_app, observe, act, and verify. The architecture has three layers: the host coding agent (the brain), the Inspector control plane (eyes and hands), and sandboxed execution planes where apps run.
Inside the control plane, five roles form the pipeline: a Mapper that clusters detected UI elements into bounded regions using OmniParser (YOLOv8 + Florence-2), a Coordinator that spawns one region-agent per region, the Region-Agents themselves that run hypothesis-driven testing (navigate, capture, trigger, measure), a Verifier that replays findings independently, and a Merger that de-duplicates and outputs the fix list.
For execution, web and Electron apps run in E2B cloud sandboxes, Linux microVMs with a virtual desktop where Chrome is launched in app mode and interaction happens via xdotool and screenshots. Android and iOS run on local emulators on the developer's machine. All four surfaces implement one SurfaceAdapter interface, so the entire core never branches on surface type.
The dashboard is a Next.js app that displays runs, findings, screenshots, and replay traces. It includes a Bug Ledger that tracks issues across runs with evidence-based status (open, verified, fixing, dismissed) and a Devin integration for automated PR creation.
Challenges we ran into
The biggest challenge was getting the computer to traverse the UI intelligently and reliably resurface bugs. A single agent wandering the entire app would get lost, miss regions, or repeat the same actions without finding anything new. We solved this by adding a planning stage: a short session launches the app, observes the screen, and the agent decomposes the UI into different regions to test. It then dispatches agents with their own isolated sandbox to target each region independently, and finally verifies the bugs through independent replay. This turned unreliable wandering into structured, parallel, thorough coverage.
Accomplishments that we're proud of
The multi-agent region decomposition is the design decision we're most proud of. Instead of one agent wandering the entire UI, each region-agent is confined to its bounding box and can't stray. This makes testing parallel, thorough, and deterministic.
The SurfaceAdapter abstraction lets us support four completely different platforms (web, Electron, Android, iOS) with zero branching in the core. The MCP tools, session manager, perception pipeline, detection engine, and loop controller are all written once.
The verify-after-act pattern, where every action returns the post-action screenshot and a changed flag, gives the agent self-correction without needing a DOM. This is the single most important reliability mechanism in the system.
What we learned
Computer-use is powerful but fragile without grounding. Raw pixel coordinate clicking fails constantly on dense UIs. Grounding-by-ID through Set-of-Mark (numbered element boxes from OmniParser) makes it reliable.
The MCP protocol is a great fit for this kind of tool. Long-running operations (app builds, test loops) map cleanly onto the Tasks pattern, and the tool interface keeps Inspector composable while the host agent supplies all the reasoning.
What's next for Inspector
Making the dashboard production-ready and hosting it as a service. Right now it runs locally. We want to deploy it so teams can share runs, track bugs across projects, and manage the Devin integration from one place.
Built With
- anthropic-claude-api
- devin
- e2b-desktop
- fastmcp
- framer-motion
- httpx
- next.js
- omniparser-(yolov8-+-florence-2)
- pillow
- pydantic
- python
- react
- replicate-api
- tailwind-css
- typescript
- websocket-(cdp)


Log in or sign up for Devpost to join the conversation.