-
-
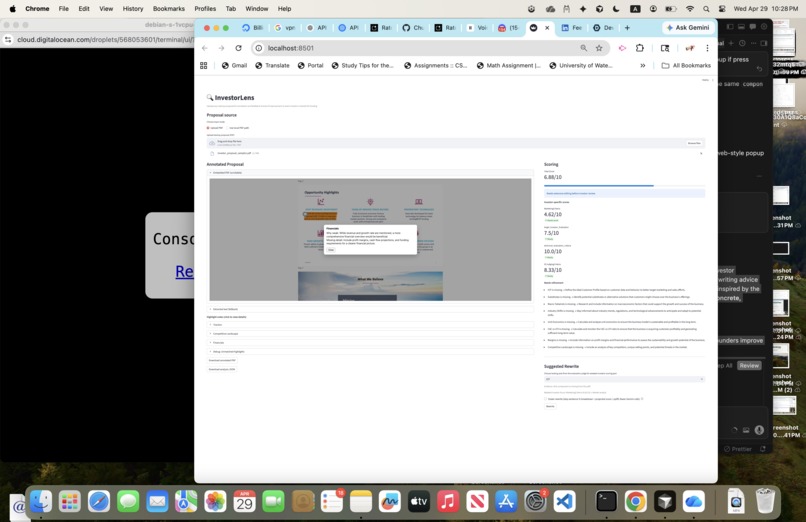
Photo of annotated error flagged

Inspiration Early-stage founders often have strong ideas but weak investor storytelling. We saw a gap: most tools either give generic writing advice or raw scoring with no actionable path. InvestorSave was inspired by the need to give founders investor-grade feedback that is concrete, explainable, and fast.
What it does InvestorSave analyzes startup proposal PDFs and helps founders improve funding readiness by:
scoring key investor dimensions (team, market, traction, defensibility, execution risk) identifying missing/weak criteria and common failure patterns highlighting evidence gaps directly in the proposal generating targeted rewrites to improve weak sections projecting score uplift from suggested changes optionally delivering audio investor-style critique (TTS) for more realistic feedback
How we built it We built InvestorSave as a multi-stage AI workflow in Python with Streamlit. A founder uploads a proposal PDF, we parse and chunk the content, then run retrieval-based evaluation (LangChain + FAISS + OpenAI embeddings) against investor criteria. The system scores proposal quality, identifies weaknesses, generates targeted rewrites, and estimates projected uplift in both total score and weakest-investor score. We also integrated ElevenLabs so feedback can be delivered as audio, not only text.
Snowflake is the data backbone of this architecture. We defined a strict Snowflake-ready schema for each analysis run and validate model output before persistence. Each run can include structured fields like scores, confidence, reason codes, evidence lineage, missing evidence, counterfactuals, and governance flags, enabling reproducible analytics instead of one-off AI responses. In practice, this lets us track startup progress over time, compare model runs, and build dashboards on top of normalized AI outputs.
Operationally, we run the app on DigitalOcean infrastructure and keep cloud runtime concerns separate from application logic in the repository and for deployment.
Challenges we ran into Balancing model quality, latency, and cost across multiple LLM calls Handling noisy/variable PDF structures reliably Avoiding repetitive or generic suggestions in rewrite output Making annotations feel natural in-browser (custom in-app popup behavior) Adapting to third-party API constraints (e.g., TTS model/voice free-tier limits)
Accomplishments that we're proud of Built an end-to-end workflow from upload -> diagnosis -> rewrite -> projected improvement Combined quantitative scoring with qualitative, founder-friendly guidance Added explainability through criteria-level feedback and evidence requirements Shipped a practical UI that non-technical users can run locally Implemented resilience improvements around model fallback and clearer API error handling
What we learned Founders value specific next actions more than abstract scores Explainability is crucial: users trust feedback when they can trace it to evidence Product UX matters as much as model quality in AI tools External API limits can shape architecture decisions more than expected Iterative prompt+evaluation loops are essential for useful, non-generic output
What's next for InvestorSave Team collaboration: shared workspaces, comments, and version history Stronger benchmarking against funding-stage and sector peers Better multimodal extraction (tables/charts/financials from decks) One-click investor packet generation (memo, FAQs, risk register) Expanded voice coaching modes (persona-specific rehearsals, objection drills) Deployment hardening and analytics dashboards for production use
Built With
- digitalocean
- elevenlab
- faiss
- gemini
- openai
- snowflake

Log in or sign up for Devpost to join the conversation.