-
-
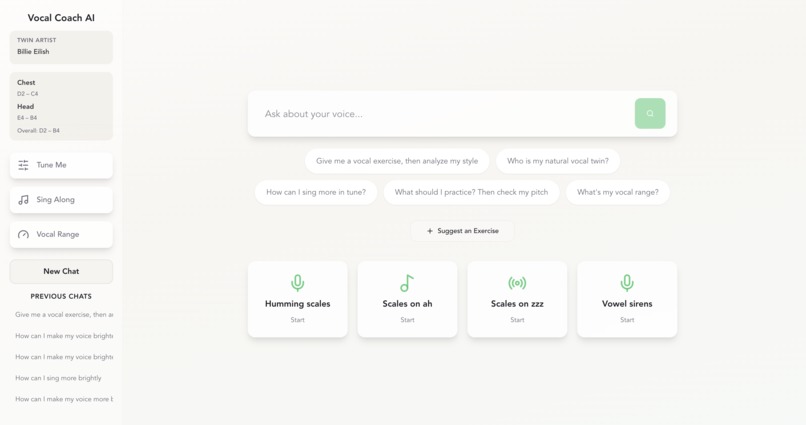
Main Page
-
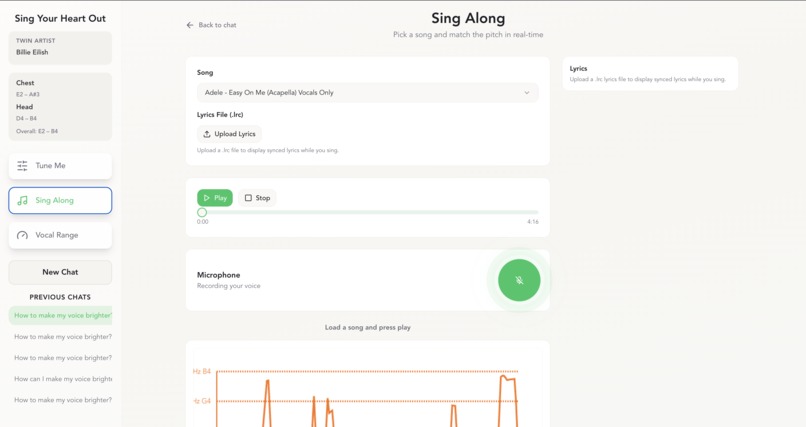
Karaoke!


Inspiration
We were inspired to build SingYourHeartOut because we all share a love for singing, and we want to get better. However, singing requires real-time, personalized feedback, but vocal coaches cost $50 or more an hour. We wanted to create a platform that would allow people to guide their own learning, get expert advice, and get nearly instant feedback whenever you practice. We were also inspired to take on this project because of the interesting technical requirements working with the sound domain, which underscored our potential to learn from this hackathon!
What it does
SingYourHeartOut puts a personalized vocal coach at your fingertips. Users sing any clip of a song and receive instant, AI-powered feedback on breath control, pitch accuracy, and head vs. chest voice usage. The coach analyzes vocal timbre to describe each singer’s unique style and compares it to well-known pop artists. It then generates targeted vocal exercises with guided instruction to help users improve in real time.
How we built it
The chatbot functionality was done using Kimi K2 Reasoning. This helped us chain together the different tools we have and create dynamic exercises for the user. For the frontend, we used react and lovable to get an idea of the theme, and then we brainstormed product and UI/UX ideas to bring the frontend together. The backend uses fastAPI and handles the bulk of the audio processing. In order to figure out what artist you sound like or qualitative descriptions of vocal tone, we trained a variational auto-encoder that embeds 6 second sound bites. The features are the mel-spectrogram, which describe the strength of different sound frequencies over time. This is important since the ratios of these frequencies determine timbre. This allows us to compare the average embedding between the user and various artists, all who have different general qualities of tone as in dark vs bright, chest vs head dominant mix, etc. We also fine-tuned a support vector machine (following this methodology https://arxiv.org/html/2505.11378v1) to distinguish between head and chest voice using a public dataset, which allows the vocal coach to have more fine-grained features, and enables us to measure vocal range across both modalities. We also developed other useful tools and features such as a breathiness metric, a tuner, and a karaoke scorer that describes how on-pitch you were during the entire song.
Challenges we ran into
For many of us, it was our first time working with sound data, so it was difficult to get the initial implementations of breath and head/chest voice detection.
In terms of training the vocal style model, it was difficult to generate salient features for the identification of different vocal styles. At first, we tried a supervised approach and tried making separate pipelines/models for each kind of style: like breathiness, belting, bright, dark, forward, etc. We realized that we needed a unified model because of a lack of data and time to train multiple models. This led us to using the unsupervised sound-bite embedding model.
Accomplishments that we're proud of
We’re especially proud that we were able to build an end-to-end working prototype in such a short time. We successfully integrated real-time audio recording, analysis, and feedback into a cohesive user experience rather than just isolated demos. Training and deploying our variational auto-encoder for vocal timbre embedding was a big milestone, since it allowed us to move beyond simple pitch detection into higher-level qualitative feedback like tonal similarity and stylistic descriptors. We’re also proud of the head vs. chest voice classifier, which gave the coaching system more nuanced diagnostic ability. Another accomplishment we’re proud of was deeply integrating Kimi K2 Reasoning into the product experience. Rather than using a chatbot only for surface-level Q&A, we used Kimi K2 to orchestrate tool-calling across our audio analysis pipeline — generating dynamic exercises, interpreting model outputs, and turning raw vocal metrics into personalized coaching advice. This made the system feel far more like an intelligent vocal coach rather than a collection of disconnected features. On the product side, we think we did a great job translating complex audio ML outputs into actionable exercises and daily practice recommendations that users can actually follow.
What we learned
We learned a lot about working with audio data, especially how noisy and variable vocal recordings can be across microphones, rooms, and singers. Feature engineering for voice is far more subjective than we initially expected, and mapping signal features to human-interpretable coaching advice required both technical and musical thinking. We also gained experience balancing supervised vs. unsupervised learning approaches under data constraints. We also learned how powerful reasoning models like Kimi K2 can be when they’re tightly integrated with domain-specific tools. Designing tool chains that let Kimi interpret vocal metrics, decide which exercises to recommend, and respond conversationally required careful prompt engineering and system design. This taught us how LLM reasoning layers can sit on top of traditional ML/audio pipelines to create a much more adaptive and personalized user experience. From an engineering standpoint, we learned how to design low-latency pipelines for audio processing, structure FastAPI backends for ML inference, and coordinate tool-calling workflows through an LLM reasoning layer. Finally, we learned the importance of UI/UX in making AI feedback feel encouraging and usable rather than overly technical or critical.
What's next for SingYourHeartOut
For future improvements, we want to improve the accuracy and breadth of our coaching feedback by expanding our datasets and training more specialized models for techniques like vibrato control, strain detection, and airflow consistency. We’re also interested in adding multimodal feedback using camera input to analyze posture, jaw tension, and breathing mechanics. We also want to push our integration with Kimi K2 further — enabling more advanced reasoning over long-term user progress, adaptive curriculum planning, and real-time conversational coaching during practice sessions. This could allow SingYourHeartOut to function less like a static analyzer and more like a continuously learning vocal mentor that evolves with the singer. On the product side, we want to introduce personalized long-term progress tracking, goal setting, and adaptive training plans. Social features — like sharing covers, getting peer feedback, or collaborating on duets — are also on our roadmap. Ultimately, we see SingYourHeartOut evolving from a practice tool into a comprehensive AI vocal training platform that’s accessible to singers at any level.

Log in or sign up for Devpost to join the conversation.