-
-

VocalCue Logo
-

-

-

-

-






Inspiration
The "Turing City" concept envisions a future where urban environments are not just smart, but sentient. They are capable of understanding and responding to their inhabitants in real-time.
We believe the next leap in city-scale intelligence isn't about adding more sensors, but about unlocking a new sense entirely: visual understanding in high-noise environments. Today's "smart city" interfaces are blind to the context of human conversation in loud, bustling public spaces like malls or transit hubs. They broadcast generic content because they cannot "hear" the crowd.
VocalCue was born from this challenge. We wanted to give the Turing City a way to "read the room" without needing audio. We set out to build a privacy-first nervous system that translates silent visual cues into actionable intelligence, making public spaces more responsive to the people within them.
What it does
VocalCue is the visual intent engine for the Turing City. It is a privacy-first Visual Speech Recognition (VSR) platform designed for high-noise B2B environments.
It acts as a sophisticated command centre that brings urban spaces to life. The system ingests live video feeds from simulated city cameras, identifies conversational groups, and uses computer vision to "read lips" in real-time. It transcribes frames of mouth movements into text, analyzes the conversation to detect general topics of interest (e.g., "coffee," "fashion," "transit"). These topics are then used to immediately trigger highly relevant advertisements on nearby digital screens. This product can also be use cases such as sentiment analysis of food at restaurants or weddings and for security within prisons.
Crucially, VocalCue works with a "Privacy-by-Design" architecture fit for a future metropolis. The system instantly anonymizes video frames. It greyscales and crops frames down to just the mouth area. This ensures that full facial data is never stored or processed by out AI model.
How we built it
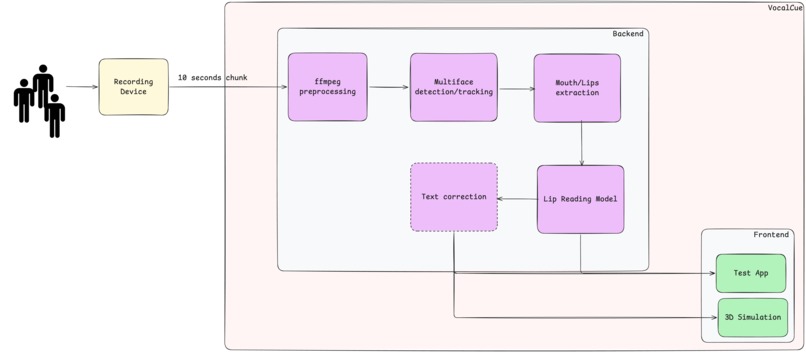
To build a responsive nervous system for the Turing City, we engineered a sophisticated AI pipeline:
- Urban Ingestion & Privacy Layer: We process live video streams to simulate city cameras. Before any AI processing, we use MediaPipe to detect facial landmarks, instantly cropping and greyscaling the frames to create a privacy shield, ensuring only mouth data enters our pipeline.
- The City's "Visual Ear" (VSR): These anonymized video snippets are passed to a local instance of the Chaplin model (trained on the LRS3 dataset), which acts as the city's visual ear, converting silent movements into raw text transcripts.
- Intelligent Action Core: The text transcripts are analyzed to detect topics, which are then used to promote real time actions (Ad recommendation, sentiment analysis, security, and more)
- Turing Command Centre: The entire operation is visualized on a futuristic, high-performance dashboard built with React and Three.js, capable of rendering complex spatial data at 60FPS for city operators.
Challenges we ran into
- Real-Time Urban Responsiveness: Running computationally heavy VSR models at the speed of a city was a major hurdle. Balancing transcription accuracy with the sub-second latency required for real-time responsiveness required significant optimization of our local model deployment.
- Orchestrating a Multi-Agent City Brain: Coordinating the hand-offs between the different AI agents without creating "jank" or data bottlenecks required designing a robust, asynchronous architecture.
- Balancing Privacy and Utility in Public Spaces: Fine-tuning the cropping mechanism to ensure it was aggressive enough to protect citizen identity (removing eyes/nose) but retaining enough data for accurate lip reading was a difficult calibration process.
Accomplishments that we're proud of
- Building a Privacy-First Nervous System: We didn't just talk about privacy; we engineered it into the city's ingestion layer. We are proud of the visual proof in our dashboard that shows only anonymized mouth data is being processed.
- The "Turing City" Aesthetic: We created a beautiful, professional command centre that translates complex AI data into an intuitive, futuristic spatial visualization.
- Successful VSR Integration: We managed to get a state-of-the-art Visual Speech Recognition model running locally and feeding real-time data into our application.
What we learned
- Visual Speech Recognition is the next urban frontier: Unlike audio, VSR is highly sensitive to lighting and angles. We learned a vast amount about the practical constraints of deploying these models in "wild" city environments.
- Privacy is a design constraint, not an afterthought: Building trust in a "sentient city" requires privacy to be baked into the core architecture from day one.
What's next for Vocal Cue
Our prototype proves the concept, but to scale VocalCue into a true city-wide nervous system, we have a clear roadmap for integrating advanced sponsor technologies:
- Production-Grade Observability with Arize Phoenix: As we deploy this system into the real world, understanding its performance is critical. We will integrate Arize Phoenix to trace the entire "Mouth -> Intent -> Action" pipeline. This will allow us to monitor model drift, debug latency bottlenecks, and ensure the city's AI is making fair and accurate decisions in real-time.
- Scalable Video Ingestion with Overshoot: Currently, we handle video streams locally. To scale to hundreds of city cameras, we will integrate the Overshoot API. This will allow us to manage diverse video sources with a single line of code, handling the complexity of stream orchestration in the cloud so we can focus on analysis.
- Hyper-Efficient Processing with The Token Company: As the number of conversations grows, LLM costs and latency will become a bottleneck. We plan to integrate The Token Company's bear-1 model to compress transcripts by up to 60% before analysis. This will drastically reduce costs and improve real-time responsiveness across the city.
- Dynamic, Scalable Ad Logic with LeanMCP: Our current ad-matching is static. To create a truly dynamic city, we will migrate our logic to a LeanMCP server. This will allow us to deploy sophisticated, scalable ad-bidding agents that can handle real-time demand and complex rules without managing infrastructure, making the system more robust and profitable for city operators.
Credits
Lip Reading Model Chaplin: https://github.com/amanvirparhar/chaplin Creator: Aman Virparhar









Log in or sign up for Devpost to join the conversation.