-
Landing page
-
Sample Questions
-
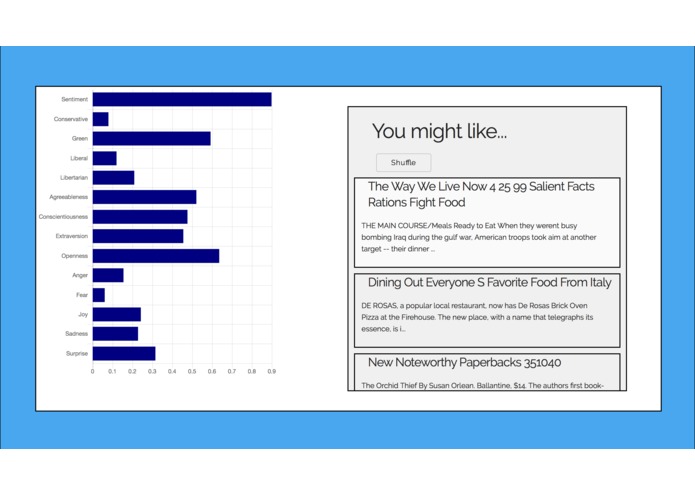
Sample Results



Inspiration
It all starts with our status as self-proclaimed news junkies. The truth about new in America-- you can never find your own. Consumers get mass media, multimedia, but they never end up getting personalized media. Every single piece of news is provided through these large corporations and their products, giving more and more bias. Even worse, there doesn’t exist anything to provide news for edification - news dedicated to gaining knowledge, not just to provide a status update on a obscure concept. That’s why we decided to make Locatr, a solution to locate all types of news - specific to the consumer.
What it does
Locatr is a web app for consumer-based news. It takes New York Times articles, but current and historic, and it aggregates them into one database, with relevant information in fourteen categories: . The user, through interaction with the web page, answers a multiple choice questionnaire and also provides a brief response about their day. Both the New York Times articles and the user responses are analyzed. The user is then provided with the articles that are similar and dissimilar to their tastes and the user is also shown their traits through a visual depiction.
How we built it
We used a python script to use Indico’s Machine Learning APIs to analyze the results we found through the New York Times API.These results were then cleaned up through python and sorted. This individualized analysis for over 5000 articles is pushed to a SQL database that is on a localhost using XAMPP. The user takes a Javascript multiple choice test to create a paragraph, and they are encouraged to add some sentences to the paragraph afterward. This paragraph is analyzed using the same API and then the results are compared using PHP to find the most similar articles given who they are. A custom chart is also displayed for the user to see the results of their test. The UI is created through the use of HTML, CSS, Skeleton, and Javascript, which allows for responsive design and effective front-end to back-end integration.
Challenges we ran into
One of the largest drawbacks of our approach (to take multiple APIs and utilize them) was that the API’s all had their respective limitations that would just compound with the limitations of others. These limitations naturally existed in the systems that we wanted to use. For example, the language analysis API could not take the calls at the rapid pace we wanted, so we had to loop the python script. Even then, we had to toy with it for a considerable amount of time to allow us to take full advantage of the features. The NYT API left us in a similar situation, due to the fact that we wanted to pull older results that quite simply were no longer on the New York Times site, and we had no way of knowing initially.The single most noticeable issue was that we were unable to pull all the results that we wanted to, and instead we had to settle for 5000 when we had hoped to allow more news articles to ensure a better success rate. We take pride in the fact that we were able to use all of these tools, and their respective limitations, in conjunction and have a complete and functional project.
Accomplishments that we're proud of
We are the most proud of the emphasis on detail throughout the assignment, as well as the overall organic qualities we were able to place into the project. It really starts and ends with detail, through the rainbow on the first page ensuring that it doesn’t turn yellow, all the way to the incredibly precise values for the traits. Even the design is detail oriented, with a consistent color scheme and moving points that cannot collide. The organic qualities were also stressed, and this was done through ensuring that each multiple choice answer had two similar sentences as options to place into the master paragraph. This ensures that there is no repetition and sentiment is allowed, and it also reflects the fact that everyone in the world does not approach an issue in the same way. We are also incredibly proud of the final, finish product- from the PHP to the SQL to even the HTML- we proved ourselves very capable of large scale projects through the work that just two of us were able to complete in under 24 hours.
What we learned
We learned to be resilient above all. We had multiple failed attempts, especially in the case of pushing the information to the database. Despite this, we persisted. We had nearly 5000 different items to collect 14 parameters for, and despite the variation that was bound to be present, we were able to make a cogent code that could handle large variations. We also learned to value the.
What's next for Locatr
Further integration and more and more results. With the endless amounts of news that come out on a daily basis, we are firm believers in the fact that we will never have enough results. This is what drives us to continue, to push forward. It is a worthy cause, and Locatr, as created at Hackean, is just the first step. We hope to expand Locatr to allow for more parameters, to allow for more daya, and also to improve the hacker experience. Locatr right now is almost like a foundation, and now we can begin to construct the rest.


Log in or sign up for Devpost to join the conversation.