-
-
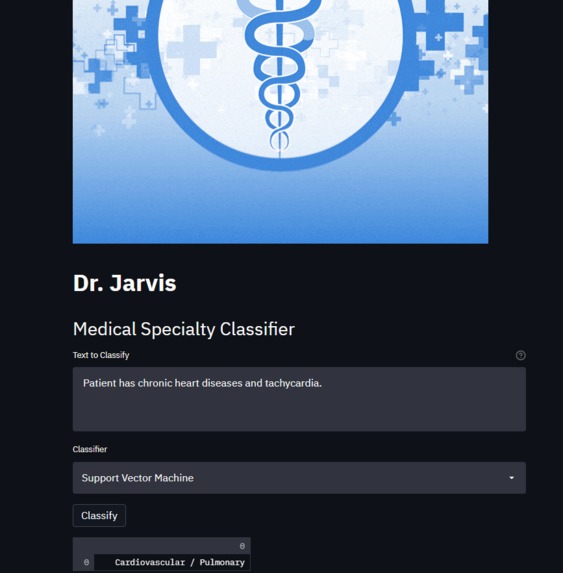
Main page
-

Word cloud generated by user input
-
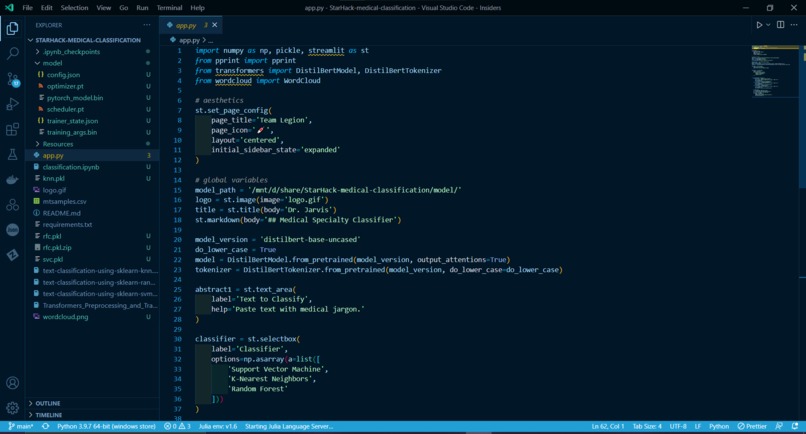
Code behind the website



Inspiration 🥼
The project was inspired by the everyday difficulties when we try to diagnose ourselves or buy the right medicine, especially when we have minor symptoms. We were also inspired by how limited health literacy leads to communication barriers in healthcare settings. According to the 2003 National Assessment of Adult Literacy, nearly half of the US population has inadequate literacy, which a serious problem as it can lead to a host of downstream effects such as inappropriate health decisions and more serious health outcomes. What's more, according to the statistics, low health literacy costs the US healthcare system up to $73 billion annually.
Our project aims to use machine learning models to classify medical specialties to help patients understand health information and services needed to make appropriate health decisions. We think this project can also benefit communities that have difficulties getting medical services casually and allow them to be more approachable to everyone.
What it does
Based on the medical symptom description submitted by our user, Dr.Jarvis helps the user identify their disease by classifying it into one of the 40 categories of medical specialty classification. A visualization using word cloud is provided with the result to help users grasp the overall picture of possible diagnosis. A user can also choose which algorithm they want to use for their diagnosis, among SVM, KNN, and Random Forest algorithms, for more accurate classification.
How we built it
We first split the medical transcriptions dataset from Kaggle, into a train and test set using Sklearn. Then we preprocessed the pure text data with tokenization, stemming, and vectorization and trained it using the SVM, KNN, and Random Forest models in Scikit-learn. The web application was developed using Streamlit framework.
Challenges we ran into
Deploying our model in IBM Z was the biggest challenge since it was the first time using it for all of our team members. The first version of our model was developed with Hugging Face and Pytorch but we had to change our base algorithm to scikit-learn as IBM Z does not support Pytorch yet. However, it was an abundance of learnings and very cool experience to get to explore a new tool and try different things.
Accomplishments that we're proud of
We are proud of how the overall web app has turned out in just one day and how the output is visualized by word cloud nicely for a better user experience. We are also proud of the text preprocessing pipeline we used to retrieve useful information from the raw text data.
What we learned
We learned about the IBM Z platform and experience how different capabilities we can use to leverage our Machine Learning pipelines. We also learned about dealing with text data and different preprocessing stages such as tokenization, stemming, and vectorization. After trying IBM Z, we are very much looking forward to learning more about it and use it with more functionalities in near future.
What's next for Medical Transcript Classification
For future improvement, we are thinking of adding more medical classifications/use different models for higher accuracy and add detailed instructions or suggestions for each category to help users to utilize our app more in their daily life and for a better user experience.




Log in or sign up for Devpost to join the conversation.