-
-

Home Page to view memories
-
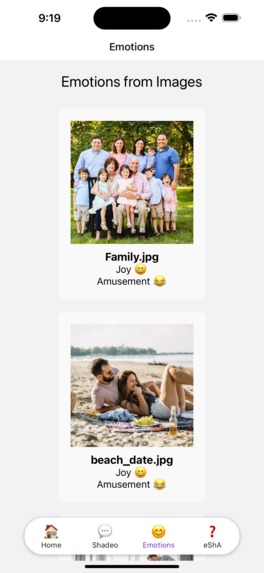
View emotions associated with each memory to look at memories you find fit for the moment
-
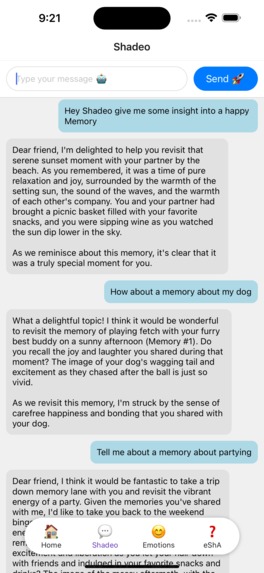
Talk to Shadeo, our AI powered Groq Chatbot, to get insights into your picture-based memories. Images brought to life!
-
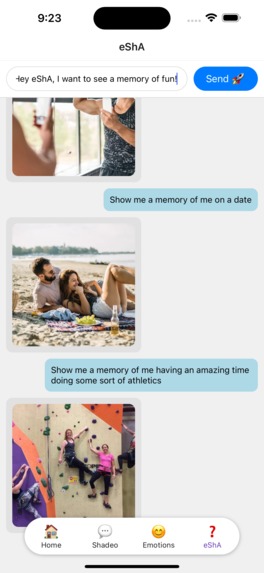
Query images based on your choice. Bring any memory in front of your eyes, in seconds.
-

User meeting with his dog in the virtual-verse.
-

Relive the past in 3D, bringing you back to the moment virtually.
-

Stable Diffusion Model trained via Intel AI to age individuals
-
 GIF
GIF
Live animation of 3D Reconstruction
-
Choose to upload more memories









Inspiration
The inspiration behind this project comes from seeing how devastating Alzheimer's disease can be. For years, Alzheimer's has been a huge problem, taking away the memories that make us who we are. It doesn’t just affect the person diagnosed but also their families, friends, and caregivers. Imagine watching a loved one slowly forget the moments you've shared, the stories you've told, and even your face. It's heartbreaking.
Alzheimer's strips away a person's independence and dignity. They start to lose track of time, forget where they are, and sometimes even who they are. Simple tasks become challenging, and daily routines get confusing. This leads to a lot of frustration and anxiety for the patients. It’s tough for their families too, as they struggle to provide care and deal with the emotional toll of seeing someone they love fade away. Social interactions become harder because patients often can't remember recent conversations or recognize familiar people. This can lead to isolation and depression. Not to mention, the healthcare costs are enormous, and finding effective care is a constant challenge.
Our project aims to address these issues in a meaningful way, giving patients a chance to reconnect with their memories and maintain a sense of identity. By tackling these challenges head-on, we hope to bring some relief and comfort to those battling Alzheimer's and their loved ones.
What it does
Our app, MemZ.ai, is all about bringing memories to life in ways that have never been done before. Here’s how it works:
On the first page, you can scroll through memories you’ve uploaded from your camera roll. But it’s not just about viewing photos—our team uses NeRF models to create 3D reconstructions of these images. This makes the memories feel real and immersive, almost like you’re stepping back into that moment. The next page lets you make phone calls with an automated AI agent. You can ask about specific memories and have conversations to learn more about your past. It’s like having a personal memory assistant just a call away, making it easier to remember and understand your experiences.
You will also meet eShA (emotional smart human ai), one of our intelligent chatbots. eShA helps you find specific memories based on what you want to see. If you’re in the mood for a happy memory or a specific event, just ask eShA, and it will filter and show those to you, making your experience super personalized. You will also get to meet Shadeo, our other chatbot. Shadeo is perfect for having detailed conversations about your memories. You can ask Shadeo about a specific memory (even if it’s just an image), and it will give you a detailed view of that moment and your role in it. It helps you get a deeper understanding of your past.
By combining these features, MemZ.ai offers a complete solution for memory care. Our app uses immersive 3D tech, AI-driven conversations, and personalized memory access to create a supportive and enriching experience for Alzheimer’s patients. This helps with memory recall and enhances the overall quality of life for users and their families, making it easier to connect with the past in meaningful ways.
How we built it
MemZ.ai is a react-native based application powered using multiple state-of-the-art technologies. We built the UI/UX first in Figma and then built the user interface using react-native.
For back-end technologies, we made use of Amazon S3 for file storage and retrieval, Amazon Dynamo-DB to store information about users and queries, Amazon EC2 to deploy the NeRF model we trained and to run inference (trained NeRF model using CUDA), Hume API to retrieve emotional information and context about your memories, Twillio and Hume to create a calling interface so users can speak to a MemZ.ai virtual memory assistant equipped with tools of conversing with you like a therapist, Groq for Large Language Model inference (using both Llama and Gemini for chatbot interfaces), and Intel AI to train a stable diffusion model that could age individuals to help show an insight into their past and future.
For more information on our Neural Radiance Fields (NeRFs) algorithm, please see Appendix A.
Challenges we ran into
We faced significant difficulties in writing a configuration file that integrates the Hume API with Twilio to provide context during phone calls. Furthermore, we could not send in any context to Hume when integrated with Twilio.
We encountered substantial GPU-related problems while training Neural Radiance Fields (NeRF) models. Allocating high-performance GPUs, managing their memory efficiently to prevent crashes, and scaling the training process across multiple GPUs to handle larger datasets and reduce training time were major hurdles. Running machine learning models on hardware without proper GPU support presented another set of challenges. The lack of dedicated training compute drivers on Intel hardware significantly hampered performance of the Stable Diffusion model. We were not able to fine-tune our model, but rather had to consistently inference the Stable Diffusion mode. Exploring alternatives like GPU emulation or compatible frameworks was necessary but difficult
Ensuring smooth deployment with Hume, required handling cross-platform compatibility and managing a lot of dependencies. Additionally, ensuring the deployed servers could scale appropriately and handle varying loads without performance bottlenecks was a complex task.
We also encountered issues in converting image file types from JPEG to JPG. Handling different image file types in code required careful consideration of file formats, extensions, and ensuring no data loss during conversion. Efficiently processing large batches of images while maintaining quality and compatibility with various applications and services that have specific requirements for image formats posed a significant challenge.
Overall, these challenges reflect the complexity and multifaceted nature of integrating advanced APIs, managing computational resources, ensuring compatibility across different hardware platforms, and handling data processing tasks. Our collective efforts in overcoming these obstacles contribute to the overall robustness and functionality of the project.
Accomplishments that we're proud of
Despite all the challenges we faced, we take immense pride in the ideation, development, and production of MemZ.ai. Our goal as creators is to impact the world in a positive light, using technology to find solutions for the world's problems. We know that MemZ.ai will help many individuals who suffer for neuro-degenerative diseases, regain their sense of self, and bring back parts of a loved one for the family members and caretakers.
We would like to highlight two key technological innovations: the creation emotionally-intelligent-agents, and the use of NeRF models for 3D-reconstructions. These innovations allow users to step back into their cherished moments and relive them in an immersive manner is incredibly rewarding. We are proud to offer an experience that makes memories feel real and tangible, enhancing emotional connections with the past.
At MemZ.ai, we take great satisfaction in how we've seamlessly integrated cutting-edge technologies to create a powerful and user-friendly app. React-native ensures a smooth, responsive UI across all devices. The integration of Hume, and groq allows for first of their kind, emotionally-intelligent-agents. By using AWS S3, and DynamoDB, we ensure secure, reliable storage and quick retrieval of memories, ensuring a hassle-free user experience. Lastly using Amazon EC2, and Intel Large-BareMetal compute we ensure a reliable realtime model inference.
What we learned
This experience has taught us a significant amount about frontend, backend, state-of-the-art ML APIs, 3D rendering models, and much more. We used new technologies we had never worked with before and read many different research papers to design the NeRF model for 3D reconstruction. Moreover, we experimented with Hume, Twillio and Groq for the first time and realized the power these tools carry within them.
What's next for MemZ.ai
We have several exciting next steps in mind to further advance MemZ.ai. Firstly, we aim to enhance the algorithms used to visualize users' memories. This could involve developing more sophisticated NeRF models to generate detailed 3D reconstructions of entire environments and key individuals. Another idea is to create a 3D rendering of the entire environment by overfitting a NeRF to a short video, allowing users to virtually navigate through a unique setting. Additionally, incorporating the stable diffusion model on the “Home” page could help users visualize their past selves more vividly.
We also explored generating short GIF-like animations from single images, but were limited by computational resources. Creating such animations could provide another way for users to relive their memories, as photographs are powerful triggers for individuals with dementia.
Research has shown that people with dementia can recall older events more effectively when those events have been recently discussed or remembered. To address this, we plan to integrate a “memory-of-the-day” feature. This feature would allow users to call an AI agent equipped with the user's memory. The AI agent would describe the memory's setting, recount events, and answer questions in an empathetic tone. Although we have already designed this page, we faced challenges in configuring Hume’s speech-to-speech system to dynamically embed the memory of the day. Successfully incorporating this feature would greatly enhance our product's usability, making it easier for users to connect with an empathetic, human-like agent rather than a text-based chatbot.
Appendix: Neural Radiance Fields (NeRFs)
Important Note: We are having some technical difficulty with uploading images of the equations used to Devpost. Please see our team members at our table, or stay posted for the equations. For now, please see the Appendix page of the following document.
Technical Overview of Neural Radiance Fields (NeRFs)
Neural Radiance Fields (NeRFs) represent scenes by mapping 3D spatial locations and 2D viewing directions to color and density values. This methodology reconstructs 3D scenes from 2D images. The following sections provide a detailed explanation into the methodologies used in NeRFs as well as our implementation of them, including scene representation, volume rendering, and optimization techniques.
Scene Representation
We represent a continuous scene as a 5D function:
where (x,y,z) denotes a 3D location, d = (θ, φ) represents the 2D viewing direction converted into a 3D Cartesian unit vector, c = (r,b,g) is the emitted color, and σ is the volume density.
The scene representation is approximated using an MLP (Multi-Layer Perceptron) network. The MLP F_θ processes the input 3D coordinates through 8 fully-connected layers, producing the volume density σ and a vector of features. This feature vector is then concatenated with the viewing direction d and passed through additional layers to predict the view-dependent RGB color.
Volume Rendering
To render the scene, principles from classical volume rendering are used, estimating the integral:
where T(t) is the accumulated transmittance along the ray from t_n to t, indicating the probability of the ray traveling without hitting any particle.
The volume density σ(x) represents the differential probability of a ray terminating at an infinitesimal particle at location x. The accumulated transmittance T(t) is defined as:
NeRF uses stratified sampling to partition the interval (t_n, t_f) into N bins and draw one sample uniformly from each bin. The final integral C(r) is then estimated using these samples:
Optimization
NeRFs also use neural networks as function approximators to learn variations in color and geometry. To enhance performance, we map the inputs to a higher-dimensional space using high-frequency functions:
Here, L is set to 10 for spatial coordinates and 4 for viewing directions.
There are two MLP networks that are optimized—one coarse and one fine. The coarse network provides an initial estimate of the scene, creating the sampling strategy for the fine network. This representation improves rendering by giving more samples to regions with higher certainty in the final image.
The loss function used for optimization combines the errors from both coarse and fine renderings:
where C_c(r) and C_f(r) are the coarse and fine predicted colors, and C(r) is the ground truth.
Coarse and Fine Network Outputs
Sampling Interval
Our NerF Application
In our implementation of Neural Radiance Fields (NeRFs), we have developed a sophisticated architecture involving a multi-view diffusion model G_M and a sparse-view large reconstruction model G_R. These models generate high-quality 3D meshes from 2D images. Here, we will break down the technical aspects of our methodology, including data preparation, model architecture, and training strategies.
Multi-View Diffusion Model G_M and Sparse-View Reconstruction Model G_R
Given an input image I, the multi-view diffusion model G_M generates 3D consistent multi-view images. These images serve as inputs for the reconstruction model G_R. The reconstruction model G_R takes the multi-view images generated by G_M and predicts high-quality 3D meshes.
White-background Fine-tuning
To address the inconsistent background of generated images, we fine-tuned a model to automatically generate white-background images. The fine-tuning process involves the following:
Model Training
Training the reconstruction model G_R is divided into two stages:
Stage 1: Training on NeRF
- Modify the Vision Transformer image encoder to include camera pose so the output contains pose features.
- Use image loss and mask loss for training
Stage 2: Training on Mesh
- Switch to a mesh representation for training with resolution images.
- Integrate Flex Cubes for getting mesh surfaces from the field
Camera Augmentation and Perturbation
To add some robustness, we apply random rotations and scalings to the input camera poses. Also, we add random noise to the camera to account for the noise in the multi-view images
Conclusion
Our approach combines data preparation, fine-tuning, and a two-stage training strategy to generate high-quality 3D meshes from 2D images. By addressing background inconsistencies and leveraging advanced geometric supervision, your work significantly improves the efficiency and quality of 3D reconstructions. The detailed equations and loss functions used in the training stages illustrate the complexity and depth of your methodology, ensuring high-fidelity 3D mesh outputs.




Log in or sign up for Devpost to join the conversation.