-
-
Node.ai

Inspiration
I noticed developers on Reddit sharing tools and receiving detailed technical feedback. These weren't casual comments but comprehensive insights with bug reports, feature requests, and architectural suggestions. The community upvoted valuable feedback, creating a natural signal for what mattered most.
I thought: why not integrate this feedback directly into my development workflow? Instead of manually sifting through Reddit threads, what if my application could automatically monitor Reddit, identify valuable suggestions, generate PRDs from user feedback, create pull requests to address issues, and redeploy after merging changes?
This vision became Node, a SaaS platform that transforms community feedback into code, creating a closed loop between user voices and product improvements.
What it does
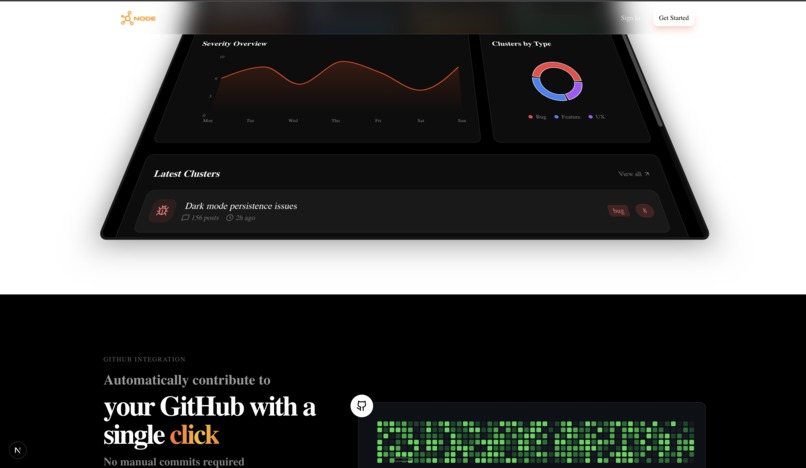
Node monitors Reddit for feedback about your products, clusters similar feedback using AI, assigns severity scores based on engagement, and automatically generates pull requests to address issues. The platform provides a dashboard to view clusters, monitor build jobs, and manage integrations with GitHub repositories. When you approve a cluster, Node creates an isolated sandbox, uses AI to plan and generate code changes, verifies the code with linting and type checking, debugs errors automatically, then opens a pull request on GitHub.
How I built it
Node is a Next.js 15 application with API routes and background jobs. Data lives in Supabase, while integrations connect to Reddit, GitHub, and LLM providers via OpenRouter.
The Reddit ingestion system handles two modes: parsing thread URLs directly or monitoring subreddits via API. It normalizes Reddit data into consistent feedback items, preserving metadata like upvotes and timestamps.
The clustering system groups similar feedback using AI. Each Reddit post becomes its own cluster, with type detection classifying feedback as bug, feature, or UX. Severity calculation uses a weighted formula:
[ S = \min\left(10, \frac{U \times 2 + C + E}{10}\right) ]
Where (S) is severity (0-10), (U) is upvotes, (C) is comments, and (E) is engagement.
The build pipeline orchestrates PR generation: creating an isolated sandbox workspace, cloning the repository, planning implementation with AI, generating complete file contents, verifying with linting and type checking, debugging errors automatically, then pushing changes and creating pull requests.
The dashboard UI built with Framer Motion, Recharts, and Tailwind CSS provides cluster views, build monitoring, and integration management.
Challenges I ran into
Large Codebases: LLM context windows overflowed with large files. I implemented intelligent truncation preserving imports and exports while truncating middle sections, limiting files to 8000 characters in prompts.
Next.js App Router Confusion: LLMs generated Pages Router patterns instead of App Router. I added explicit system prompts distinguishing the two, providing correct examples, and blocking incorrect imports.
Error Diagnosis: Generated code failures produced overwhelming error output. I built an error diagnosis engine categorizing errors, identifying root causes, prioritizing fixes, and using multiple fix strategies.
Rate Limiting and Costs: Reddit API has strict limits and LLM calls are expensive. I implemented thread URL parsing avoiding API calls, used low temperature settings for deterministic outputs, cached repository introspection, and batched processing.
Safety: Automatically modifying codebases is dangerous. I created a multi layered safety system with path blocking, risk flagging, conservative planning, full verification before PRs, and requiring human approval.
Context Management: LLMs need sufficient context but too much causes token overflow. I built an intelligent context engine prioritizing files by relevance, limiting to top 8 files, and caching contents to avoid redundant reads.
Accomplishments that I'm proud of
I built a fully automated pipeline from Reddit feedback to GitHub pull requests. The system successfully parses complex Reddit thread structures, clusters feedback intelligently, and generates production ready code that passes linting and type checking. I created a self correcting debugging agent that can diagnose and fix errors iteratively. The safety system prevents dangerous changes to critical systems like authentication and billing. I achieved intelligent context management that balances code quality with token efficiency.
What I learned
Building Node taught me critical lessons about production AI systems. Parsing Reddit threads required handling nested comment structures, markdown formatting, and context preservation. The clustering algorithm needed semantic similarity understanding, not just keyword matching. Effective AI systems require careful prompt engineering and context management.
Generating production ready code from natural language is deceptively difficult. The system must understand existing architecture, generate code fitting existing patterns, handle edge cases, ensure type safety, and avoid breaking critical systems. I implemented a multi stage pipeline: planning to analyze issues, coding to generate complete files, verification with linting and type checking, and debugging with an AI agent that fixes errors iteratively.
Early versions could modify any part of the codebase, which was dangerous. I implemented strict safety constraints with blocked paths for auth, billing, and secrets, plus a risk flagging system. When generated code fails verification, an intelligent debugging agent diagnoses errors by category, gathers context, plans fixes using multiple strategies, and reflects on failures to improve.
What's next for Node
I plan to implement semantic clustering using embeddings to group truly similar feedback across different posts. I'm exploring a multi LLM strategy trying different models for different tasks like planning versus coding versus debugging. I want to generate incremental updates instead of regenerating entire files, creating focused patches. I'm working on automatic test generation for generated code. Finally, I'm building a feedback loop learning from which PRs get merged versus rejected to improve future generations.
Built With
- autoprefixer
- bun
- class-variance-authority
- clsx
- css-variables
- eslint
- framer-motion
- github-api
- javascript
- lucide-react
- next.js-15
- node.js
- octokit
- openrouter-api
- postcss
- postgresql
- radix-ui
- react-18
- recharts
- shadcn/ui
- supabase
- tailwind-css
- tailwind-merge
- typescript
- vercel


Log in or sign up for Devpost to join the conversation.