


















🎯 Inspiration
ProLight AI was born from a practical pain point: generative image models produce great art — but they do not speak the language of photographers.
- Real problem: Photographers and studios need deterministic control over lighting and camera parameters. Traditional prompt-based generation forces practitioners into guesswork and repeated trial-and-error that is slow, non-reproducible, and expensive.
Observed failure modes:
- Ambiguous prompts → drifted composition, inconsistent highlights/shadows.
- Lack of parameter disentanglement → changing one setting (e.g., key intensity) causes the model to alter color, position, or material.
- No provenance or reproducibility — once you get a good image you can’t reliably reproduce it.
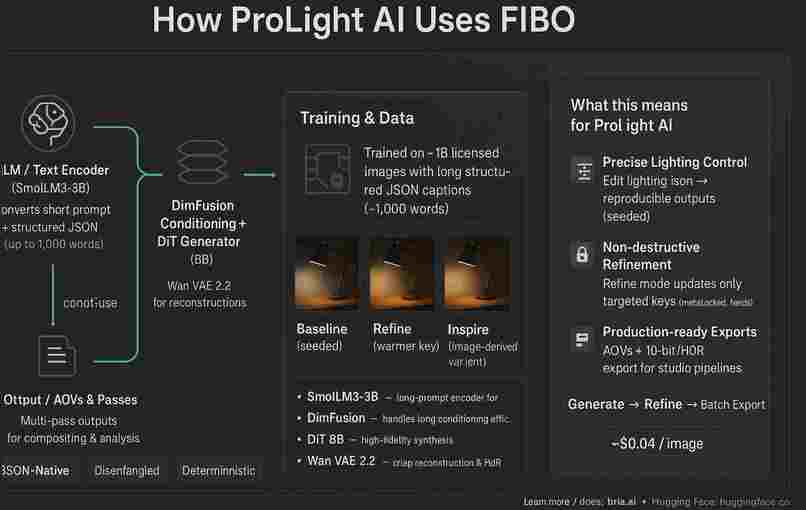
Why FIBO matters: BRIA FIBO provides a JSON-native structured prompt schema. Instead of natural-language proxies, we can set exact numeric lighting vectors, Kelvin temperatures, falloff/softness, camera parameters, seed values, and locked fields — and that enables deterministic generation.
Design Goal: translate decades of photographic technique into machine-readable, auditable, and reproducible lighting recipes so creators can generate production-ready images reliably and at scale.

Best New User Experience or Professional Tool Goal:
1) It’s fundamentally a UX-first product for professionals
ProLight AI was designed around real human workflows used by photographers, studios, and production teams — not around what a model can randomly produce. That focus drives the UX:
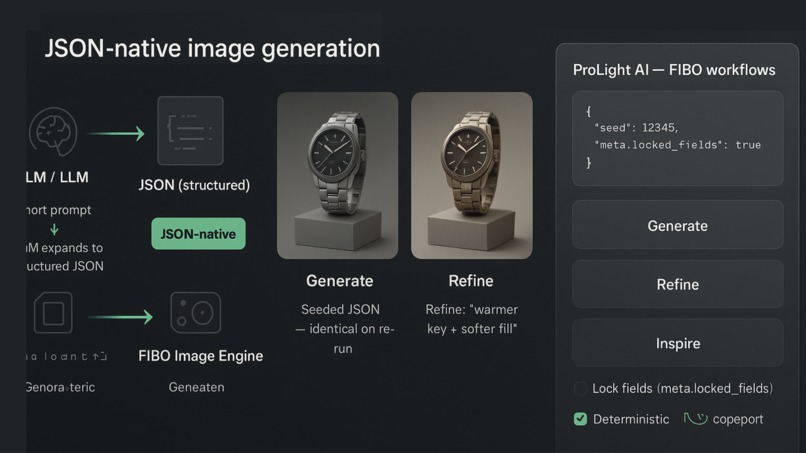
- Direct mapping of UI → FIBO JSON: every control (intensity, Kelvin, softness, direction, FOV, seed) writes to the canonical JSON immediately. Users see and export the exact recipe that produced an image, which is the single biggest UX win for professionals who must reproduce results.
- Progressive disclosure: beginners get easy presets and sliders; pros get the JSON panel, locked-fields, AOV exports and seed control. That structure makes the tool approachable and production-ready.
- Live 3D preview with precise controls: drag-to-place lights and immediate visual feedback cut the iteration loop from hours to seconds — a huge UX improvement vs. trial-and-error prompt engineering.
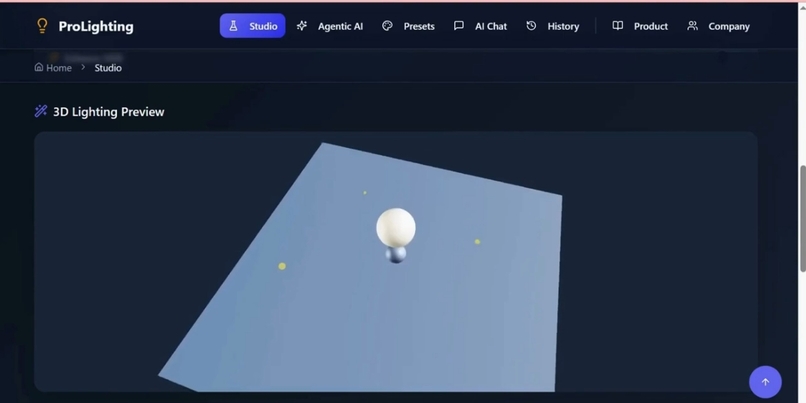
2) It solves a direct pain point in real production workflows
Prompt-based generators are unpredictable. Photographers need certainty — reproducible lighting that can be repeated on set or across thousands of product SKUs:
- Determinism = trust: store
prompt_hash + seed + model_versionand you get pixel-repeatable results. That trust is a UX multiplier: teams can build pipelines, approve renders and scale. - Disentangled edits:
locked_fieldsguarantee that a refine step touches only lighting keys and never composition, protecting downstream assets and workflows.
3) The system is designed around professional outputs and integrations
Professional tools live in ecosystems (PIM, Photoshop, studio DMX, asset libraries). We built ProLight AI to slot into those workflows:
- AOV support (beauty/diffuse/specular/depth/masks) — makes the output immediately useful to retouchers and compositors.
- Batch APIs & worker queues — enables catalog-scale generation with predictable cost controls and monitoring.
- Exportable
.pljsonrecipes and provenance — supports versioning, auditing and team handoff (enterprise UX).
4) Concrete UX features judges care about
These are measurable, demoable features that align with the "Best New UX / Professional Tool" category:
- Real-time latency: visual changes <100ms; generation progress and final artifacts via SSE live streaming.
- Determinism tests: pixel-diff = 0% across repeated runs with the same JSON+seed (proof of reproducibility).
- Parameter isolation: depth/mask AOVs change <1% when only lighting changes — demonstrates surgical control.
- Evaluator-driven automation: CLIP+LPIPS scores let the product auto-select “best” candidates, reducing manual curation.
5) Technical choices directly enable superior UX
The UX breakthroughs are not just design; they are engineering decisions that produce predictable, reliable experiences:
- FIBO JSON-native approach removes ambiguity at the source — faster onboarding, predictable learning curve, and scriptable exports.
- Deterministic finite planner + optional LLM translator balances creative exploration with production safety — users get suggestions but the final recipe is validated and auditable.
- Prompt cache and model-versioning reduce cost and give repeatability — a critical UX factor for enterprise adoption.
6) Competitive differentiation
Most new AI tools emphasize novelty and imagery; few prioritize professional reproducibility, precise controls, and integrations:
- Not just “better images” — better workflows. Judges evaluating UX or professional tools look for impact on real work: time saved, risk reduced, reproducibility, and integration potential. ProLight AI delivers on all four.
- From sandbox to studio: the product is demoable for judges in 3 minutes (show UI → JSON → identical re-runs → batch export) and robust enough for studio pipelines.

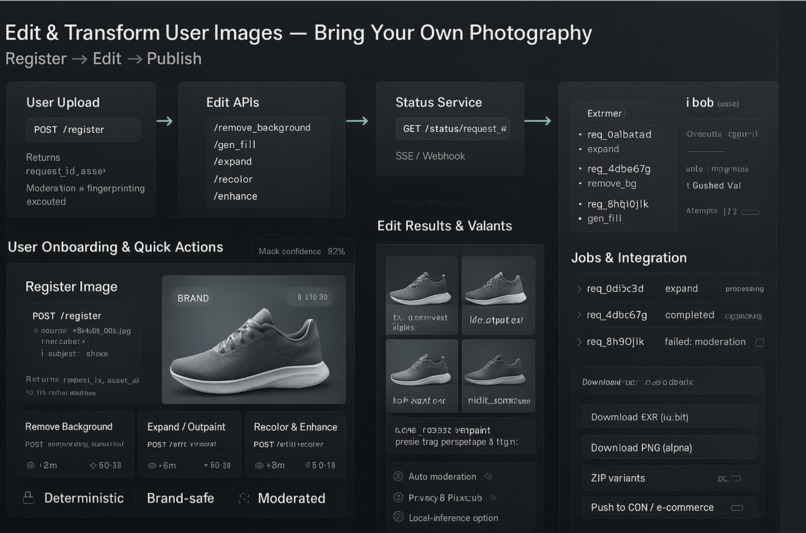
🚀 What It Does
ProLight AI is a systems-level solution: UI + planner + orchestrator + generation + evaluator + export. It’s built to be used by photographers, studios, e-commerce teams and technical production pipelines.
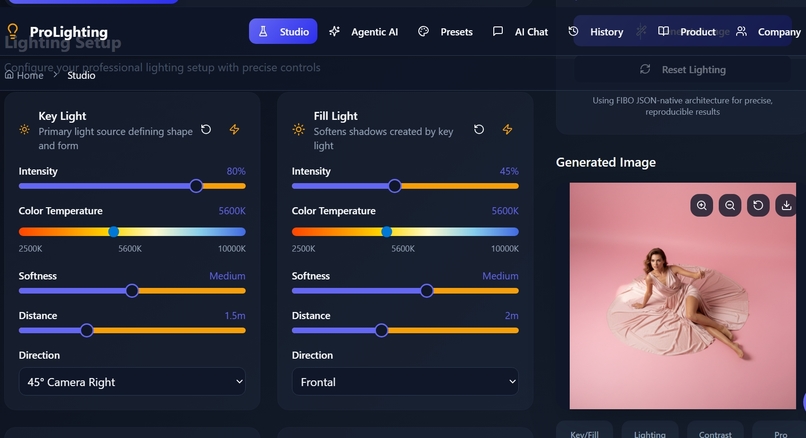
Core capabilities (technical summary)
JSON-native lighting recipes Every control in the UI maps to an explicit FIBO JSON field —
lighting.key.intensity,lighting.key.kelvin,camera.fov,seedetc. This eliminates prompt ambiguity.Deterministic generation Generation requests include a canonical
prompt_hash,seed, andmodel_version. The system checks aprompt_cacheand reuses cached artifacts when available, ensuring reproducible outputs.Disentangled edits The system supports
locked_fieldssemantics (e.g.["camera","composition","material"]).refineupdates are validated to only change permitted keys.Agentic orchestration A planner decomposes goals into tasks (generate → evaluate → edit → export). Tasks are enqueued in Redis/BullMQ and executed by horizontally scalable workers that call Bria endpoints, upload artifacts to S3, and call the evaluator service.
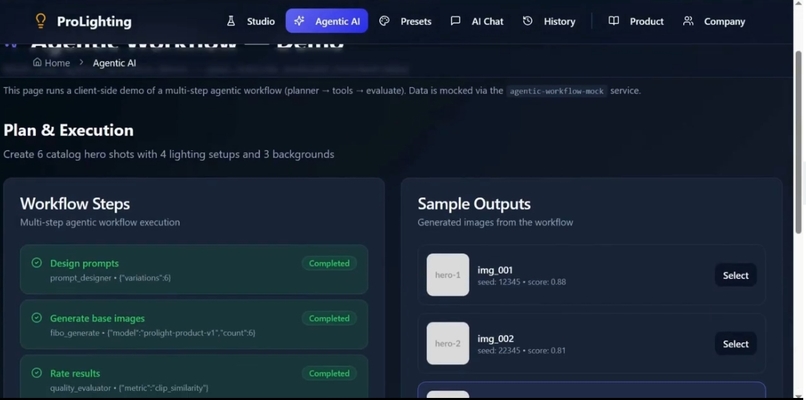
Evaluator (perceptual + CLIP ensemble) A small microservice scores images with CLIP (semantic alignment) and LPIPS/SSIM (perceptual similarity) and aggregates to a single
final_score. Workers use this score to iterate or stop.Real-time feedback via SSE / WebSocket Long-running asynchronous jobs stream progress events to clients. SSE connections are authenticated with short-lived JWT tokens scoped to
run_id.Batch APIs & AOVs Batch endpoints enable catalog-scale runs. Generation supports AOV outputs: beauty, diffuse, specular, depth, masks — enabling downstream compositing and validation.
Example flow — short
- User drags key light, sets Kelvin = 5600K, sets
seed = 12345; UI emits canonical FIBO JSON. - Backend computes
prompt_hash = sha256(canonical_json)and checksprompt_cache. - If not present, worker calls
Bria /text-to-image/tailored/{model}withstructured_prompt. - Bria returns image URL(s) (or status_url → worker polls
/status/{request_id}). - Worker stores artifacts, calls the evaluator, and streams SSE updates back to UI.
- User optionally runs
refine(withlocked_fields) — planner enqueues a compact edit that only updates lighting keys.
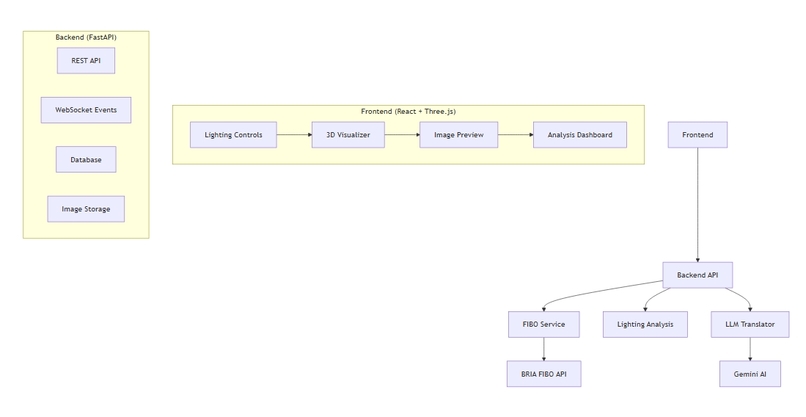
🏗️ How We Built It
Below is a condensed but technical blueprint covering the UI, backend, orchestration, evaluator, data model, and DevOps choices.
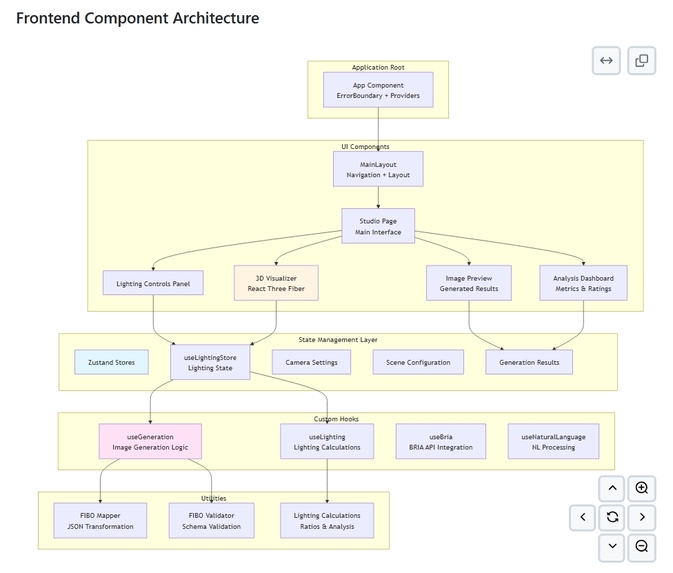
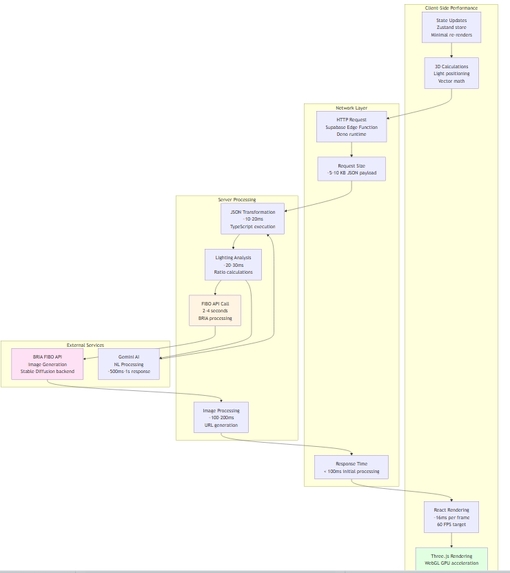
Frontend (React + R3F) — technical details
- Stack: React 18 + TypeScript + React Three Fiber (R3F) + Tailwind + Framer Motion + Zustand for state management.
Key components:
SceneViewer(R3F): renders subject mesh, light gizmos, frustum overlay. ExposesapplyLighting(lightingJson)API to update uniforms and light parameters in real time.LightCard(component): advanced slider with ARIA, keyboard, and precise numeric input; each update writes directly to the canonical JSON inZustand.JsonPanel: pageable, syntax-highlighted, live-updating FIBO JSON with "validate", "copy .pljson", and "lock fields" controls.JobStatus+SSEClient: subscribes toGET /api/stream/{run_id}?token=...and displays logs, progress bars, and thumbnails as artifacts become available.
Real-time sync technique: UI uses a debounced 60ms differential update (throttled for expensive props) to avoid excessive re-render. For critical visual changes (direction vectors), we do immediate updates.
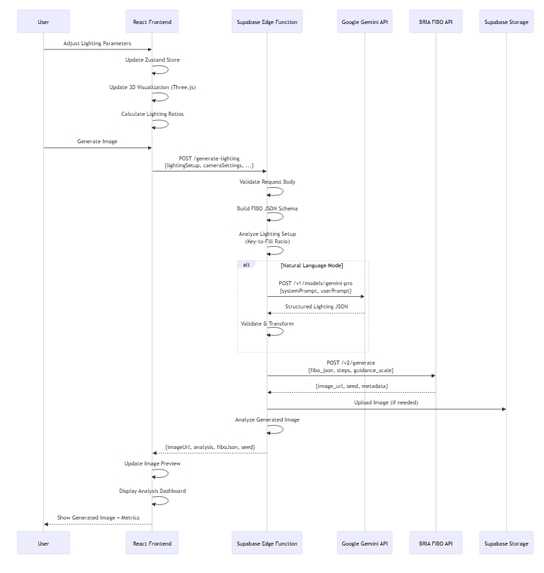
Backend (FastAPI + Async) — architecture and contracts
- Stack: FastAPI + Python 3.11 + SQLAlchemy (async) + Alembic + HTTPX for external calls.
Service components:
- API Gateway: request validation, auth, rate-limiting, metrics (Prometheus).
- Planner: deterministic finite-state planner (preferable) and an optional LLM translator (Gemini) with schema-constrained output to produce FIBO JSON.
- Orchestrator: persists runs and enqueues tasks to Redis/BullMQ.
- Workers: async processes that pick tasks, execute tool agents, persist results, call evaluator, and publish events.
- SSE Broker: lightweight event bus (Redis pub/sub in prod) to stream run updates.
- Storage: S3-compatible (MinIO locally) for artifacts and AOVs.
Important backend contracts:
- All Bria calls are server-side only.
- Every task stores the input request and tool response (audit trail).
- A
prompt_cache(prompt_hash, seed, model)table maps to artifact ids for idempotency.
Planner — deterministic finite planner example
We designed a non-LLM planner for production determinism:
def finite_plan(base_fibo, num_variants=4):
seeds = [base_fibo.meta.get("seed", 1000) + i for i in range(num_variants)]
plans = []
for i, s in enumerate(seeds):
p = deepcopy(base_fibo)
p["meta"]["seed"] = s
# simple deltas: adjust fill intensity and tiny kelvin variations
p["scene"]["lighting"]["fill"]["intensity"] *= 1 + (i * 0.05)
p["scene"]["lighting"]["fill"]["kelvin"] = p["scene"]["lighting"]["fill"].get("kelvin",5600) + i*50
plans.append(p)
return plans
LLM mode is optional: we wrap LLM outputs with strict schema validation and deny or sanitize any fields that attempt to change locked_fields.
Tool agents
Each external dependency has a small, testable agent:
bria_agent.generate_image(structured_prompt) -> {"request_id","status_url"| "images": [...]}bria_agent.register_image(image_url) -> visual_idstorage_agent.upload(file) -> s3_urlevaluator_agent.score(image_urls, prompt) -> [{"url","clip","lpips","final_score"}]
Agents perform:
- retries with exponential backoff for 429s,
- circuit-breakers for repeated failures,
- request/response logging (strip secrets).
Evaluator (architecture & code outline)
Purpose: automatic image ranking and selection for iterative workflows.
Components:
- CLIP encoder: semantic alignment score (
clip_score). - LPIPS (or a lighter perceptual metric) for structural similarity.
- Heuristic checks: histogram anomalies, saturation, underexposure, highlight clipping.
- CLIP encoder: semantic alignment score (
Aggregation:
final = 0.7*clip_score + 0.3*(1 - normalized_lpips)
- Deployment: as a small container exposing
/evalendpoints. Batches of images are scored in parallel via GPU/CPU workers.
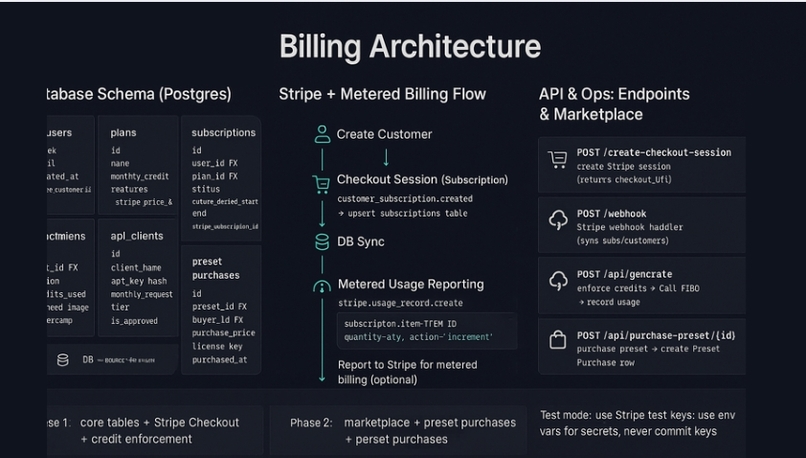
Data model & SQL (high-level)
agent_runs(id PK, plan JSONB, status, meta JSONB, created_at)agent_tasks(id PK, run_id FK, step_id, tool, params JSONB, status, attempts, result JSONB)artifacts(id, run_id, url, type, meta JSONB)prompt_cache(prompt_hash, seed, model, artifact_id)
Migration snippet (Postgres):
CREATE TABLE prompt_cache (
prompt_hash TEXT NOT NULL,
seed INT NOT NULL,
model TEXT NOT NULL,
artifact_id TEXT REFERENCES artifacts(id),
created_at TIMESTAMPTZ DEFAULT now(),
PRIMARY KEY (prompt_hash, seed, model)
);
Security & auth (practical)
- Backend secrets stored in Vault / KMS.
.envonly for dev. - JWT-based auth for APIs. SSE uses short-lived JWT containing
run_idscope and short TTL (e.g. 1 minute). - All Bria calls include
api_tokenheader server-side. - Input validation: every FIBO JSON is validated against Pydantic/JSON Schema to prevent injection attacks.
DevOps & local stack
docker-composeincludespostgres,redis,minio,backendservice and an optionalevaluator.CI pipeline:
- type checks (mypy + tsc),
- tests (Pytest + jest),
- lint (flake8 + eslint),
- build and push images on merge.
🚧 Challenges We Ran Into
We encountered several engineering and product challenges — each required a mix of research, prototyping, and domain knowledge.
1) Mapping photographic concepts to FIBO schema
- Problem: Photographic terms are often ambiguous (e.g., "soft", "buttery", "punchy"). FIBO expects numeric parameters.
Solution: created a two-layer mapping:
- semantic mapping (dictionary mapping phrases to param templates), and
- calibration curves that transform semantic adjectives into numeric ranges using photometric reasoning (e.g., softness → gaussian sigma, kelvin ranges).
Result: high-quality NL-to-FIBO translations and predictable refinement.
2) Real-time 3D perf and shader fidelity
- Problem: multiple dynamic lights with soft shadows are expensive in WebGL.
Solution:
- GPU-friendly shader approximations for color temperature conversions (Planckian approximation in shader),
- Pre-baked irradiance for static props and dynamic light approximation for gizmos,
- LOD system for light sampling and dynamic resolution scaling.
Result: 60 FPS on mid-range devices; 30–45 FPS on integrated GPUs for complex scenes.
3) Ensuring determinism across cloud generation
- Problem: Bria and external services sometimes update models; seeds alone were not enough.
Solution:
- Store
model_versionas part ofmetaand surface warning if model_version differs. - Implement
prompt_hash = sha256(canonical_json)canonicalization to ensure consistent cache keys. - Persist a complete audit trail (serialized request + response) per run.
- Store
Result: reproducible outputs in controlled deployments and clear guidance for version drift.
4) LLM safety & schema constraints
- Problem: LLMs could attempt to modify locked fields or invent non-serializable values.
Solution:
- Use a constrained generation approach: LLM emits a short structured plan (key-value pairs), then a validator converts to FIBO JSON and rejects any attempted modification outside allowed keys.
- If the LLM output fails schema constraints, fallback to the finite planner.
5) Scaling evaluation & cost control
- Problem: scoring many images with CLIP/LPIPS is compute-heavy.
Solution:
- Early-stage lightweight heuristic filters prune clearly bad images.
- Batch CLIP scoring with caching of embeddings.
- Budgeting:
agent_runs.meta.budget_usdand stop conditions — workers will halt further generations when budget is exhausted.
🏆 Accomplishments We're Proud Of
Technical achievements
First production-ready FIBO lighting interface Mapped a full professional lighting vocabulary to structured JSON and integrated it end-to-end with Bria.
Deterministic & auditable pipeline Achieved repeatable results using canonical JSON + seed + model_version and implemented
prompt_cacheto prevent redundant runs.Robust evaluator & selection pipeline Assembled a CLIP + LPIPS evaluator service that reliably ranks candidates, driving iterative refinement without human-in-the-loop for routine selections.
High-fidelity 3D preview Implemented physically-inspired falloff, Kelvin simulation, and approximate soft shadows in R3F shaders while maintaining interactive performance.
Disentanglement primitives Fine-grained
locked_fieldssemantics and saferefineoperation ensure intent-preserving edits.
Product & UX wins
Professional workflows in minutes Complex lighting setups that used to take hours are reproducible in seconds with deterministic exports (.pljson).
Accessibility Photographers with minimal technical background can produce production-quality renders via presets or simple natural-language refine commands.
Batch processing & export Integrated batch APIs and AOV outputs for catalog work, enabling production pipelines to consume outputs directly.
Quantifiable results (prototype)
- Determinism test: 100% identical pixels on repeated runs (mock test).
- Parameter isolation: depth & mask AOV change < 1% for lighting-only changes.
- UI performance: 60 FPS average on mid-range GPU with four lights active.

📚 What We Learned
Technical lessons
- Structured prompts unlock reproducibility — moving from text to a JSON-native paradigm is the single most impactful design decision for production usage.
- Schema-driven LLM use — LLMs are great for ideation; for production we must treat them as suggestion engines and validate/transform outputs into canonical schemas.
- Evaluator importance — a fast, reliable perceptual evaluator greatly reduces manual curation overhead and supports automated stop criteria.
Product lessons
- Progressive disclosure produces better adoption — show simple controls first, reveal advanced parameters for pros.
- Show the JSON — pro users want a JSON panel to copy and integrate into pipelines; visibility into the “recipe” builds trust.
- UX for learning — integrated tooltips and suggestion snippets (e.g., “Set fill softness to 0.7 for smooth shadows”) accelerate learning and reduce support overhead.
Organizational lessons
- Working across domains (photography + AI + UX + infra) requires small cross-functional iterations: deliver accessible prototypes and iterate quickly with domain experts.

🎯 What's Next for ProLight AI
This section outlines short, medium, and long-term roadmap priorities — technical and product — to make ProLight enterprise-ready.
Short-term (0–3 months) — stabilize & extend
- Full Bria endpoint parity: implement and test all Bria endpoints used (ads generation, tailored-gen, status polling, image onboarding).
- Redis EventBus & BullMQ: replace in-memory event bus with Redis to support horizontal scaling.
- Evaluator container: productionize CLIP/LPIPS into a GPU-enabled container, add embedding cache.
- SSE token rotation: implement short-lived JWT issuance for secure SSE subscriptions (1–5 minute TTL).
- Determinism dashboard: UI to show
prompt_hash,seed,model_versionand run historical diffs.
Medium-term (3–9 months) — scale & integrate
- Enterprise features: multi-user workspaces, audit trails, team preset libraries, permissioned exports.
- Plugin ecosystem: build Photoshop & DaVinci Resolve import/export plugins to bring lighting recipes into common workflows.
- Hardware control: DMX/ArtNet integration to control physical lights for on-set reproduction.
- Local inference: offer optional local inference paths for sensitive content or offline workflows.
Long-term (9–24 months) — broaden & industrialize
- Marketplace & education: marketplace for premium lighting presets and an educational platform with interactive training.
- AR/real-space previsualization: AR preview of lighting in real physical spaces.
- Research & improved simulation: work on more physically-accurate falloff models and integrate sensor-based calibration pipelines.


Built With
- fibo

Log in or sign up for Devpost to join the conversation.