-
-

Quakey Arm Control
-
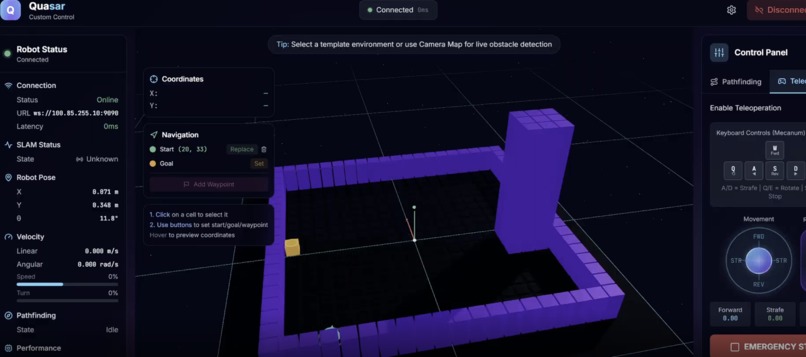
Quakey Odometry
-
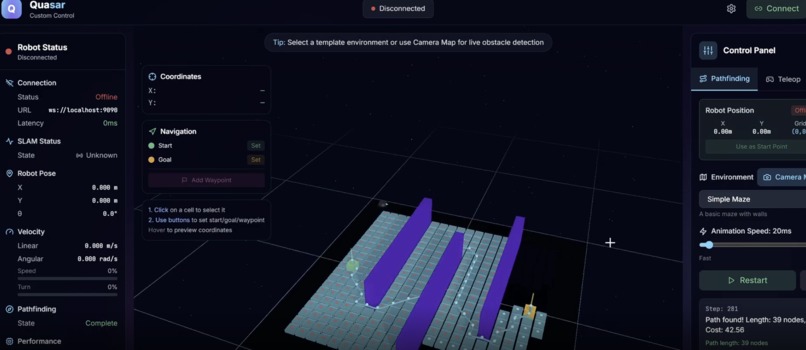
3D A* Autonomous Search
-

Quakey In motion
-
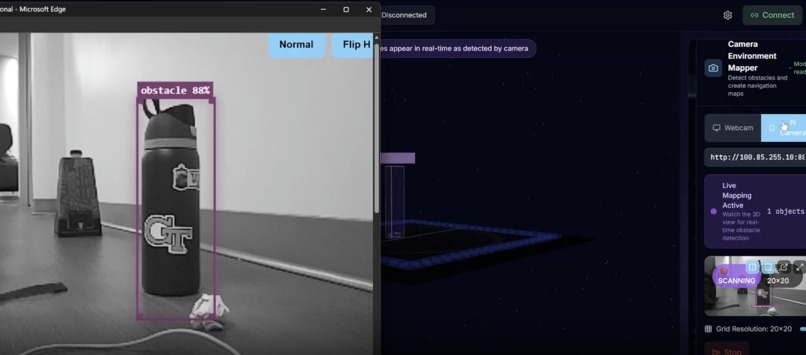
Object Detection Panel V2
-
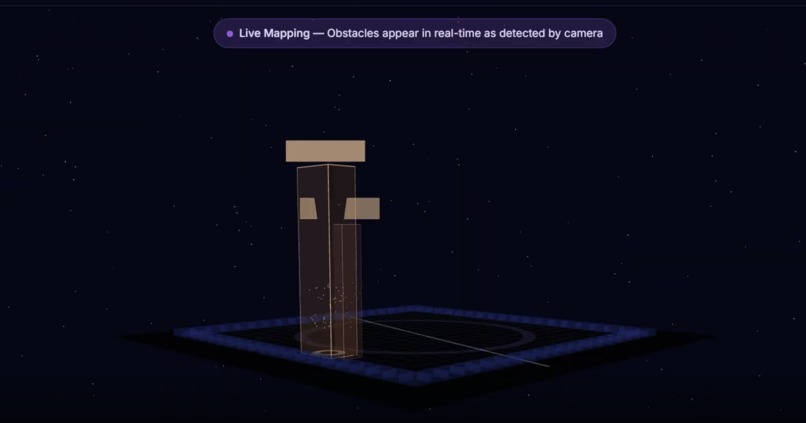
Object Detection Panel
-

Quakey Autonomous Navigation
-

2D A* Autonomous Search








Quasar — Vision-First Autonomous Navigation for Off-World Mining
Inspiration
The new frontier is space. Iron, nickel, cobalt, platinum, gold — scarcity eradicated. Mega satellites discovering habitable planets. Dyson swarms capturing energy at unprecedented scale. But space mining robots face problems no terrestrial robot deals with: dust storms, extreme terrain, communication delays measured in minutes, and power budgets measured in watts.
LiDAR fails here. Research shows adverse weather and particulate scattering introduce noise into point clouds and reduce effective range (Gupta et al. 2025). Under dust or fog, returns collapse near the sensor (Kim et al. 2023). Even when LiDAR works, it only tells you where things are — not what they are.
We built a system that sees, understands, and navigates using nothing but a single RGB camera.
What It Does
Quasar is an autonomous rover that navigates unknown terrain, detects obstacles semantically, estimates depth from monocular vision, builds a persistent 3D world model, plans collision-free paths, and executes missions end-to-end — all without LiDAR, GPS, depth sensors, or human intervention.
The Tasks:
- Navigate to a goal in unknown terrain using only a single RGB camera
- Perform real-time semantic obstacle detection during continuous motion
- Infer depth from monocular vision and maintain a persistent world model
- Generate and continuously update collision-free navigation plans
- Execute complete missions with closed-loop control and resource collection
How We Built It
Hardware (We Built the Robot Too)
- Custom 3D-printed chassis — lightweight, raised center for terrain stability
- Mecanum drive (4 wheels) — omnidirectional movement, independent translation/rotation
- L298N motor drivers — PWM vectoring for precise control
- Raspberry Pi 4 — onboard compute for motor control and streaming
- Pi Camera — the only navigation sensor
- Double-pitch articulated arm — reaches inaccessible resources
- Virtual four-bar gripper — compact, reliable grip
Software Stack
| Layer | Tech |
|---|---|
| Robot Control | Python, pigpio, ROS Bridge (roslibpy) |
| Kinematics | Mecanum drive, dead-reckoning odometry |
| Perception | TensorFlow.js, COCO-SSD, WebGL |
| Depth | Monocular perspective projection, temporal smoothing |
| World Model | 3D occupancy grid with exponential decay |
| Navigation | A* with adaptive heuristics |
| Dashboard | React, TypeScript, Three.js, Zustand, Tailwind |
| Comms | WebSocket, MJPEG streaming |
How It Works
Perception: Sub-100ms detection cycles via TensorFlow.js in the browser. Classifies obstacles semantically — rocks, equipment, humans are different entities.
Depth: d ∝ (f·H) / h_px — larger objects in frame = closer. Stabilized with exponential smoothing: d̂_t = α·d̂_(t-1) + (1-α)·d_t
World Model: Detections projected into 3D occupancy grid. Obstacles persist; noise decays: P(t) = P(t-1)·e^(-λΔt)
Navigation: A* search with costs for distance, diagonals, and proximity to obstacles. Heuristics switch dynamically (Euclidean/Manhattan/Chebyshev) based on terrain. Replans in real-time as perception updates.
Execution: Proportional control with odometry feedback: v = k_p·(x_goal - x_robot). Safety cutoffs enforced.
Challenges
- Hardware assembly — mecanum alignment, wire routing, stable camera mounting
- Motor calibration — each motor different; PWM tuning for straight movement
- Monocular depth — no ground truth, had to rely on object scale and smoothing
- Browser ML — TensorFlow.js optimization to hit real-time on embedded hardware
- Coordinate alignment — pixels → world → grid → odometry required careful math
Why This Matters
| Traditional | Quasar |
|---|---|
| LiDAR + GPS + IMU + depth | 1 RGB camera |
| High power draw | Minimal |
| Fails in dust/reflections | Immune (passive sensing) |
| Point clouds (no semantics) | Classifies what obstacles are |
| Black box decisions | Full visualization |
| $10,000+ sensor suite | <$500 BOM |
Built With
Hardware: 3D-printed chassis, mecanum wheels, L298N drivers, Raspberry Pi 4, Pi Camera, servos, LiPo
Software: Python, ROS Bridge, pigpio, React, TypeScript, Three.js, TensorFlow.js, COCO-SSD, Zustand, Tailwind, Vite
One camera. Semantic understanding. Real-time replanning. This works where LiDAR fails.
Quasar doesn't just avoid obstacles — it understands its environment, reasons about it, and navigates autonomously where traditional sensors fail. This is the foundation for off-world resource extraction and humanity's next leap into space.







Log in or sign up for Devpost to join the conversation.