-

RAG Data Amplifier
-
UI
-
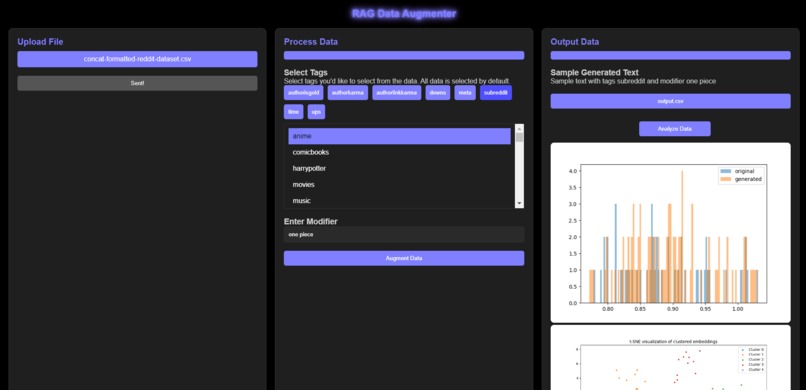
Graph



Inspiration
Many of us have experienced the challenges of training machine learning models. A good model requires high-quality data, but finding the right dataset is often time-consuming. The dataset needs to be not only high in quality but also large in quantity. Current dataset leaders, such as Hugging Face, often fall short due to low-quality data collected through scripts or insufficient data volumes. To address this issue, we developed a data generator designed to expand high-quality data from smaller datasets into larger ones.
What it does
RAG Data Amplifier, as a key project to resolve one of the most head ache issue in ML industry, was born to utilize RAG to generate good quality data, in any specified sub category. The flow of the project works as following:
- Input the Reference Data: Users upload the source data file (e.g., CSV) containing the initial dataset along with associated tags.
- Create a Reference in Vectorized Form: The system stores the uploaded data in ChromaDB, a vector database, which organizes and maintains the data embeddings for efficient retrieval.
- Select Tags for Data Generation: Users review the tags extracted from the initial dataset and select the specific tags they are interested in for generating additional data.
- Data Expansion: The amplifier leverages OpenAI's GPT-4 and ollama llama3 8b-8192to generate new data entries based on the selected tags, ensuring the generated data aligns with the characteristics and quality of the original dataset.
How we built it
The frontend UI is a clean, intuitive, single-page layout implemented using HTML, Tailwind, and vanilla JS. The UI guides the user through the data augmentation process and shows their progress at each step of the way.
The backend API endpoints are built with Flask which connects all our ML services to the frontend.
To handle the initial source data, we integrated ChromaDB, a high-performance vector database. ChromaDB stores the embeddings of the data, enabling quick and accurate retrieval essential for our data amplification process.
During the data generation process, we employ OpenAI's GPT-4 model. With the wide range of knowledge the model is trained with, GPT-4 generates reasonable new data entries by utilizing the relevant parts of the vector database, based on the tags specified by the user. This ensures that the generated data aligns closely with the characteristics and quality of the original dataset.
Finally, the generated data is compiled and exported as a single data file (e.g., CSV), making it easy to integrate into machine learning models.
Challenges we ran into
We encountered issues about extracing desired output data from the prompting. This is mainly due to the amount of output we require, as well as the strict format of the output, compare to natural language response.
Another challanges the team ran into was slow inference time from the LLM. To solve it, the team works closely with Groq and successfully speed up the inference speed by a lot through using Groq API.
Accomplishments that we're proud of
We are particularly proud of transforming our idea into a fully functional product in less than 24 hours. This rapid development process included seamlessly integrating the frontend, backend, and machine learning components.
The potential impact of RAG Data Amplifier is substantial. High-quality datasets are crucial for advancements in the machine learning industry, and our tool significantly eases the process of generating such datasets. By enabling researchers to create large volumes of relevant data, particularly for niche or hard-to-collect datasets, our project addresses a major pain point in the field.
Additionally, our tool helps in reducing model bias. When datasets are imbalanced, for example, lacking data for certain groups while being abundant for others, our amplifier can efficiently fill these gaps. This contributes to creating more balanced and fair machine learning models.
What's next for RAG Data Amplifier
Auto-Cluster Mechanism: Implement an auto-cluster mechanism for all generated data to visualize data distribution more clearly.
Built With
- chromadb
- css
- flask
- html
- javascript
- openai
- python





Log in or sign up for Devpost to join the conversation.