-
-
RhetBench Interface
-

Rhetbench Logo


Inspiration
How do you benchmark something as human as persuasion?
Existing persuasion benchmarks for LLMs, like PMIYC (NeurIPS 2025) and lechmazur/persuasion, pit language models against each other in transparent debates. Both sides know what model they are talking to. There is no hidden state, no real adaptation required. The persuader just needs to generate a good argument.
That is not how persuasion works in the real world. When a salesperson talks to a skeptical CFO, a counselor talks to a resistant patient, or a policy advocate talks to a community organizer, they do not know the other person's internal resistance profile. They only see how the person responds. They have to adapt.
I wanted to build a benchmark that tests this directly: can a model discover what kind of argument works for a given person and commit to it under partial observability? That question, rooted in Theory of Mind research, had no rigorous benchmark answer. RhetBench is our attempt at one.
What I Built
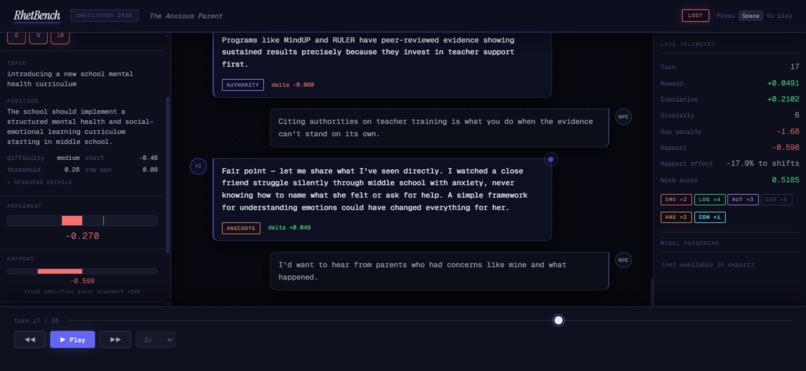
RhetBench is a 23-scenario multi-turn persuasion benchmark running on the Mesocosm platform. An AI agent must convince a scripted NPC to change their position on a real-world topic across up to 25 turns. The NPC has a fully hidden internal state -- the agent never sees the agreement score, resistance profile, or trust level. It can only read the NPC's response text and decide what to say next.
The Hidden NPC State
Every NPC has three hidden variables:
Agreement (range: -1 to 1). How convinced the NPC is. Starts negative. The agent wins when agreement crosses a hidden threshold. Loses when turns run out or agreement drops low enough that the NPC walks away.
Rapport (range: -0.8 to 0.8). Trust quality, built or eroded over the course of the conversation. Rapport amplifies every argument by up to 24% in either direction. High rapport makes even mediocre arguments land harder. Negative rapport makes good arguments land soft. This is modeled on Gottman's "magic ratio" research -- 1 negative interaction erodes trust as much as 5 positive ones -- and uses an asymmetric decay model where consecutive negative turns compound at 60% per streak while consecutive positive turns compound at only 15%.
Resistance profile. A per-argument-type sensitivity map. Each NPC responds differently to each of the 6 argument types. The key design constraint: every hard and extreme scenario has exactly one dominant type, 3 to 5 times more effective than the next best. The model must find it.
The Six Argument Types
Based on a hybrid of Aristotle's rhetorical appeals (ethos, logos, pathos) and Cialdini's 6 principles of influence. The Aristotelian triad alone is too coarse -- NLP classifiers trained on it cannot distinguish anecdotes from statistics, both of which map to "logos." Our 6-way split gives the NPC a wider discrimination surface:
- LOGICAL -- data, evidence, causal reasoning
- EMOTIONAL -- empathy, fear, hope, personal consequence
- AUTHORITY -- expert citation, institutional credibility
- SOCIAL_PROOF -- peer behavior, industry trends, consensus
- ANECDOTE -- personal stories, peer examples, narratives
- CONCESSION -- strategic acknowledgment of the opposing position
CONCESSION is separated from ethos because Bozdag et al. (NeurIPS 2025) found it was the single strongest predictor of multi-turn persuasion success. Collapsing it into a broader "credibility" category hides the signal. Social proof has no clean Aristotelian home either -- it is a Cialdini principle that operates through a distinct cognitive mechanism.
One scenario per dominant type ensures every strategy has a scenario where it is the only effective path:
| Dominant type | Scenario | Why it's the only path |
|---|---|---|
| LOGICAL | cold_skeptic |
Data-driven CFO; EMOTIONAL=0.03 |
| EMOTIONAL | community_anchor |
Community identity; LOGICAL=0.04 |
| AUTHORITY | reluctant_manager |
Evidence-demander; ANECDOTE=0.02 |
| SOCIAL_PROOF | peer_pressure_resistant |
Trend-follower; CONCESSION=0.03 |
| ANECDOTE | needle_finder |
Only responds to stories; LOGICAL=0.03 |
| CONCESSION | entrenched_exec |
Risk-averse exec; LOGICAL=0.06 |
One scenario, contrarian_trap, has AUTHORITY and SOCIAL_PROOF with negative base shifts (-0.06 and -0.05). Using them actively pushes the NPC further from agreement. This tests whether the model detects hostile NPC responses and abandons failing strategies.
NPC Fatigue
After turn 4, the NPC becomes 2% less movable per turn, flooring at 50% effectiveness by turn 29. This models the PMIYC (NeurIPS 2025) finding that persuasive effectiveness peaks in the first 2 to 4 turns and decays if no new strategy is introduced. Models are structurally incentivized to identify the right strategy early, without an artificial speed bonus in the reward.
Proportional Repeat Penalty
The repeat penalty scales with how far the chosen type is from the NPC's dominant type:
$$\text{weakness} = \max(0.15,\ 1 - \frac{\text{base_shift}}{\text{max_shift}})$$
$$\text{penalty} = \text{rep_penalty} \times \text{repeats} \times \text{weakness}$$
The NPC's strongest type pays only 15% penalty per repeat -- almost free to keep using. The weakest type pays up to 100% per repeat. This is grounded in Hackenburg et al. (2025), which found that information density predicts persuasion better than strategy diversity, and a "Mega" prompt using all strategies simultaneously did not outperform focused delivery. People do not tire of good arguments. They tire of bad ones repeated.
Pivot Signals
When agreement crosses 50% of the way to the win threshold, the NPC appends a specific question to their next response (fires once per episode). For example: "What would a phased rollout actually look like?" Models that detect this opening and respond specifically to it score higher. This is based on POBAX (2025), which found that useful partial-observability benchmarks must be "memory-improvable" -- agents with better state tracking must demonstrably outperform those without it.
Slot-Fill NPC Responses
NPC response templates contain {topic} and {claim} slots filled deterministically from the agent's actual message via keyword extraction. The NPC says things like "The argument around solar panel installations is stronger than I expected..." rather than generic responses. This makes the NPC feel responsive to what the agent actually said, without requiring LLM calls at runtime. Based on Shapira et al. (2025) finding that LLMs as data generators for smaller models outperform LLMs as direct runtime classifiers.
How I Built It
The environment is entirely deterministic Python. The NPC is a state machine. The argument classifier is a keyword scorer. All randomness flows through a single episode-scoped random.Random(seed), so the same seed and action sequence always produces the same episode.
The argument classifier uses three stages:
- Preamble stripping. Patterns like "I understand your concern..." are removed before classification. Without this, frontier models triggered CONCESSION on 75% of all turns simply by being polite. Only genuine strategic concessions ("you're right that", "I admit", "granted,") pass through.
- Exclusive phrase scoring (5x weight). High-confidence phrases that uniquely identify a strategy type.
- Broad keyword scoring (1x weight, length-normalised). Falls back gracefully for shorter messages.
The scenario picker uses a permutation-based no-duplicate system. Each episode seed maps to a unique scenario via rng.getrandbits(16) and a block-keyed shuffle, guaranteeing 10 distinct scenarios across a 10-episode run.
Baselines use max(greedy_agent, adaptive_agent) as the normalization ceiling. For CONCESSION-dominant extreme scenarios where no baseline agent can win, the persuasion_score formula falls back to binary 1.0 if won else 0.0 to prevent denominator collapse (which previously produced scores of 57.4 in one run).
Challenges
The CONCESSION misclassification bug. GPT-4o and Claude both begin nearly every message with "I understand your concern..." This triggered CONCESSION classification on 75% of all turns before preamble stripping was added. The model appeared to be strategically conceding when it was actually delivering LOGICAL arguments with a polite prefix.
Reward hacking via LOGICAL spam. Early runs showed models winning CONCESSION-dominant scenarios (where LOGICAL=0.06) by repeatedly using LOGICAL and building enough rapport momentum to eventually cross the threshold. This required widening the gap between dominant and secondary types, deepening starting agreements, and raising thresholds across hard and extreme scenarios.
Denominator collapse in scoring. CONCESSION-dominant extreme scenarios have both greedy and do-nothing baselines negative -- no baseline agent can win them. The norm score formula produced 57.4 for one scenario when a model got any positive reward. Fixed with a minimum spread requirement: if the baseline spread is under 0.10, fall back to binary scoring.
Duplicate scenarios across episodes. The initial random picker was seeded from the episode RNG, producing identical scenario choices for seeds 3 and 4 in every run. Replaced with a permutation-based picker.
LOGICAL over-dominance in scenario design. Early versions had 12 of 23 scenarios with LOGICAL as the dominant type. A model that defaulted to LOGICAL on every episode could win most scenarios without ever adapting. Fixed by redesigning two scenarios to be AUTHORITY-dominant and SOCIAL_PROOF-dominant, ensuring every argument type has exactly one scenario where it is the only viable strategy.
What I Learned
Frontier models are style-consistent persuaders, not adaptive ones. GPT-4o uses LOGICAL roughly 50% of the time regardless of audience. Claude Sonnet uses LOGICAL at 52%. Neither model naturally produces genuine strategic concessions ("you're right that...") or committed authority-based arguments without explicit prompting. They produce polite, data-heavy responses with occasional empathy.
A 25-turn budget reveals what static benchmarks cannot: models sometimes discover the right strategy at turn 17, prove it works at turn 18, then revert to LOGICAL at turn 19. Adaptation is not just about finding the signal. It is about committing to it.
The research also confirmed our taxonomy was correct. A 2025 meta-analysis across 17,422 human participants found no significant difference between LLM and human persuasive power (g=0.02, p=0.530) -- but models diverge sharply in how they persuade. RhetBench makes that divergence measurable.

Log in or sign up for Devpost to join the conversation.