-
-

Sign Sync Logo
-
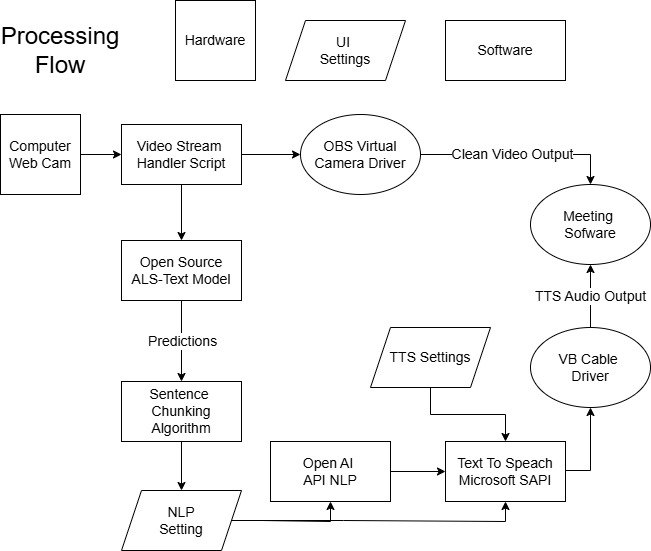
Process Flow
-
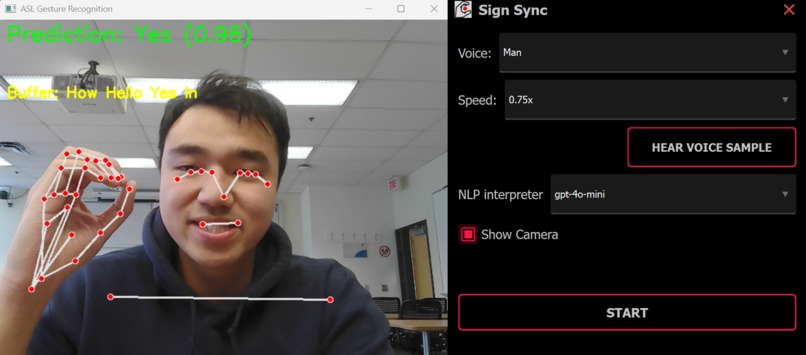
Ui and reference camera
-
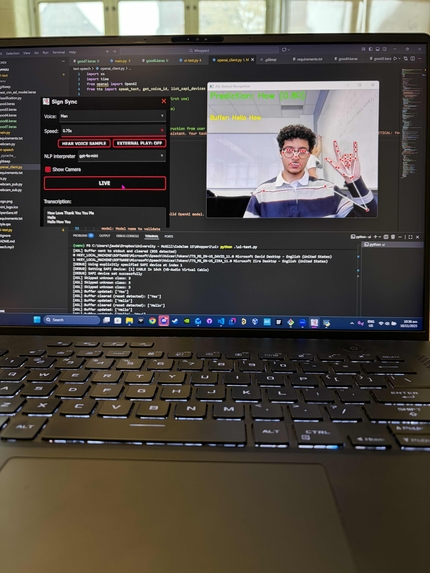
-
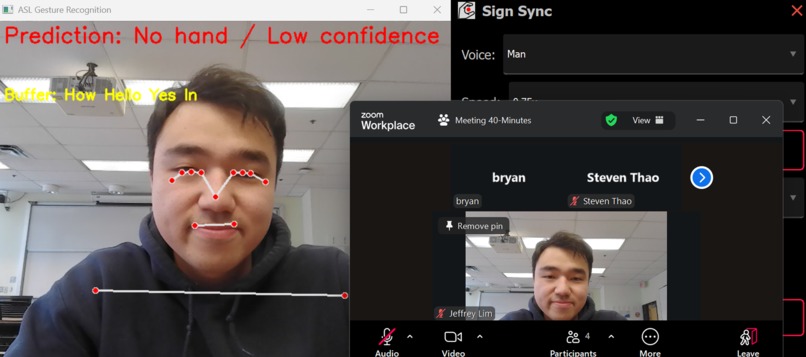
UI, reference camera, and zoom video output





Inspiration
Our team wanted to create a tool that makes online communication more accessible for ASL users. We noticed that most meeting platforms ( Zoom, Google Meet, Discord, and others ) don’t offer any built-in way for people who sign to seamlessly speak in meetings. Existing ASL-to-speech tools are limited, hard to integrate, or don’t work live.
So we set out to build SignSync: a real-time ASL → text → speech system that plugs directly into meeting apps using a virtual camera and virtual audio pipeline.
If everyone else can unmute and speak, ASL users should be able to as well.
What it does
SignSync converts ASL gestures into spoken audio in real time and injects it directly into any meeting platform.
Here’s how the pipeline works end-to-end:
- Camera Input – The user signs in front of their webcam.
- Virtual Camera Layer – We pass the video stream into a virtual camera so Zoom/Meet/Discord see it as a normal webcam input.
- ASL Recognition Model – In parallel, the raw frames are processed by our Python ASL model (TensorFlow + MediaPipe) to extract landmarks and classify signs.
- NLP Cleanup – The recognized words are sent to an LLM to repair grammar and turn fragments into clean, natural sentences.
- Text-to-Speech – The corrected sentence is synthesized using pyttsx3.
- Virtual Audio Output – The synthesized voice is piped into a virtual microphone so meeting software receives it as if the user were speaking.
The result: Users can sign naturally, and SignSync speaks for them directly inside any video meeting.
How we built it
We built SignSync using a combination of real-time computer vision, UI design, and system-level routing:
- Python + PyQt6 for the desktop application and control UI
- OpenCV for raw video capture and frame processing
- MediaPipe Holistic for hand and pose landmark extraction
- TensorFlow for our gesture classification model
- Custom Model → Pretrained Swap: we first trained our own dynamic ASL model, but due to low accuracy and overfitting we switched to a static pretrained ASL model for reliability
- ZMQ for internal messaging between processes
- PyVirtualCam for virtual webcam output
- pyttsx3 for offline text-to-speech
- Virtual Audio Cable for routing synthesized speech into meeting apps
We designed and tested the entire end-to-end infrastructure so the experience works live with minimal latency.
Challenges we ran into
- Our custom ASL model didn’t perform well—dynamic gestures were inconsistent and low-accuracy, so we had to pivot to a static model mid-hackathon.
- Real-time processing latency became a major challenge, especially when routing video to multiple consumers (virtual cam + recognition pipeline).
- Audio routing on Windows is notoriously tricky; getting TTS output into virtual audio while avoiding echo loops took time.
- Integrating computer vision + NLP + TTS in one stable pipeline caused several threading issues.
- PyVirtualCam + OpenCV slowed down when multiple subscribers were receiving frames.
Accomplishments that we're proud of
- We built a fully functional end-to-end ASL → voice system.
- Our UI is smooth, responsive, and easy to use.
- Virtual camera and virtual audio integration work reliably across Zoom, Meet, and Discord.
- Achieved real-time gesture recognition using MediaPipe and TensorFlow.
- Designed a clean pipeline diagram and architecture that makes the system understandable and scalable.
What we learned
- How to combine computer vision, NLP, and speech synthesis into a real-time stack.
- How virtual camera and virtual audio drivers work behind the scenes in video conferencing apps.
- The limitations of training ASL models quickly, especially with small datasets.
- UI/UX considerations for accessibility tools.
- Better pipeline optimization techniques for OpenCV and MediaPipe.
What's next for SignSync
We want to push SignSync closer to a fully fluent ASL communication tool:
- Add more signs and expand to dynamic gestures.
- Improve ASL grammar translation instead of relying on NLP sentence cleanup.
- Train a custom lightweight model optimized for real-time use.
- Add customizable TTS voices and languages.
- Build a cross-platform version (Windows/macOS/Linux).
- Eventually create a mobile app or web-based version.
SignSync is just the beginning—we hope it can help make online communication more inclusive for Deaf and Hard-of-Hearing communities.
Built With
- python
- tensorflow





Log in or sign up for Devpost to join the conversation.