-
-
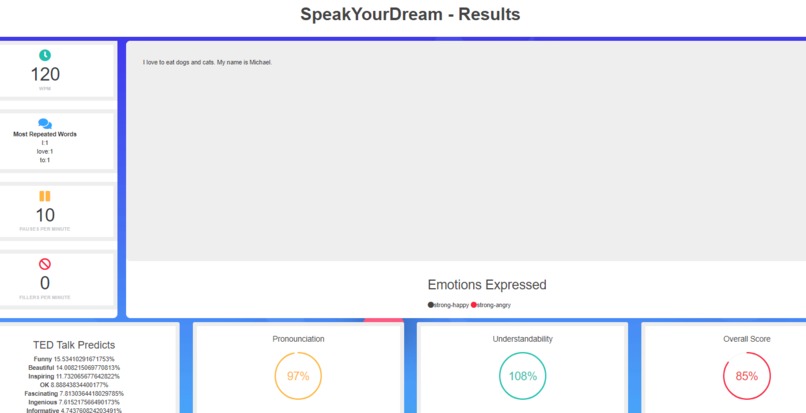
Speech Analysis Score Report after you submit your transcript and record your speech.
-
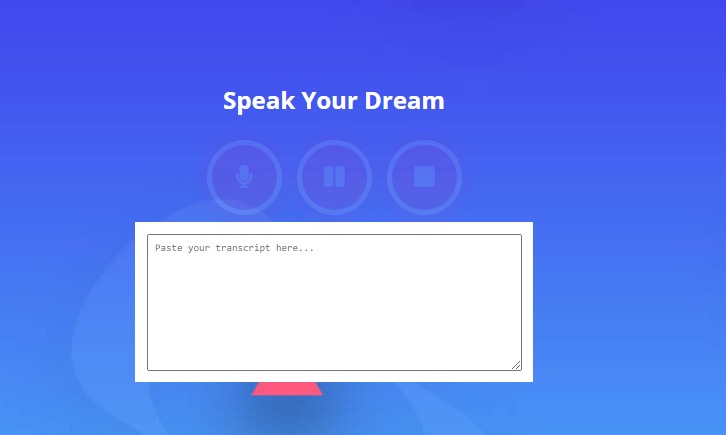
Enter your speech transcript.
-
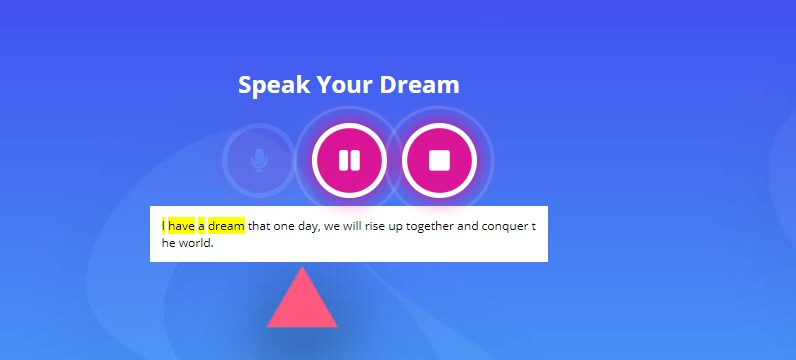
Highlights text as you go to tell you where you're at. Pause and resume audio.
-
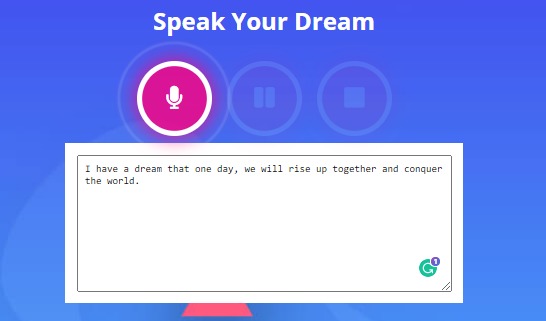
Start recording after you've submitted your transcript.
-
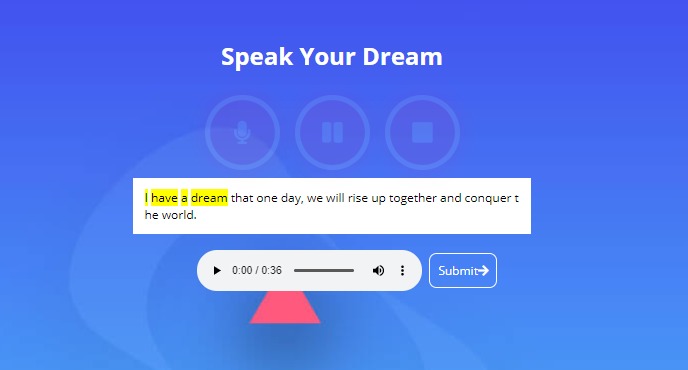
Upload your speech to be analyzed.





Inspiration
As high school students, we tend to give a lot of presentations and speeches, especially during our Language classes and sometimes even our science classes. However, during the age of Covid-19, it is really hard to find a peer to sit down with that can listen to your speech as you are probably miles away from each other. Your parents are busy working and you have no one to help you. So what if there is an application that can listen to your speech and give you authentic feedback helping you improve your speech? Considering that 73% of people have a fear of public speaking, this application could bring more and more people to have the nerves to stand up, sharing their ideas. Furthermore, since MLK day is slowly approaching, it is only right to do something in honor of him. The famous, artful, speech “I have a dream” will continue to inspire many around the world for racial justice. So we asked ourselves how can a machine tell us how to give great speeches?
What it does
SpeakYourDream takes into account many different criteria and analyzes both the transcript and the way you perform your speech. These criteria are the speaker’s display of emotions through machine learning, pronunciation, pauses, usage of filler words, and how good its content is. It even compares your speech to famous ted talks to try and categorize audience reaction. Each of these criteria will be analyzed and displayed to the user, however, there will also be a total score. To do this, we have to normalize data into numbers from 0 to 1 and then weight them according to how important they are to a speech. To normalize this data, we made up a series of equations using logarithmic, exponential, and linear regression. This way the users will have an in-depth understanding of their strengths and weaknesses as well as an overall insight into how good their speech is.
How we built it
Firstly, as the backend, we chose flask as it was a python backend that could help us run TensorFlow but it also was much easier to get started with compared to Django. The frontend was built to take input in the form of a textarea and record audio, at the same time counting how many fillers and other data would be used to analyze later on in the backend. To record the audio, we used recorder js and as for the live speech to the text we used artyom.js which proved to be very lightweight and highly accurate. Within the backend, the data of the audio file and transcript is then used to get data based on the criteria listed above. Emotions, pronunciation, and the content’s conciseness were based on results we received after sending it to an API. Filler words were counted in the frontend which was sent to the backend stored in a text file for later use. To get the audience’s reaction, we trained a neural network model to take transcripts as input and different tags as output. These tags would range from things like funny, inspiring to long-winded and obnoxious. To train this model we had a dataset that contains 2000 items. The input was the transcript and the target for each of these items were the tags which the users had chosen for the specific ted talk video. We trained this model for 200 epochs giving pretty impressive results. We also split the audio by silences and detected emotion in each of these files with another neural network trained using RAVDESS. Finally, to calculate the overall score of the speech, we went through a process that normalized data. To do this we had to try to fit these values into values between 0 to 1. A common method that was used was an exponential regression, however, linear regression was also really helpful. Finally, we attached a weight to each of these categories giving much more importance to the content compared to things like how many pauses were taken during the speech. All this data would then be sent to the frontend again with the id in the address telling the backend what to send to the frontend giving the user the result of his speech right after his speech showing him how he did in all of these criteria, as well as providing the final score which sums up his performance giving him a bigger overview of where the speaker stands. The pronunciation score and readability scores are determined by the speech SDK and Flesch formula respectively.
Challenges we ran into
We faced many different challenges which we were eventually able to overcome, proving to be a very worthwhile experience. Firstly, we couldn’t find a data source that we could use for machine learning algorithms. Of course, a dataset too small is basically setting ourselves for failure but eventually, we were able to find something with the perfect magnitude for our project. Secondly, we had some trouble sending our audio file data back to the backend. The big problem was that the data blob for the audio file wasn’t compatible for wav files which were later fixed by changing the recording function to something compatible. Next, we weren’t able to use the speech to text API which we integrated due to problems regarding audio file channels. We used different APIs where some required 1, whereas others require 2, and the speech to text API required 1. This really held us back but we eventually figured out how to tinker with these files allowing us to fully use our APIs. For our machine learning algorithm which determines how the audience will react towards the speech, our first few tries of training our model weren’t very successful as our model seems to be not learning at all. By playing with it a bit, the accuracy started to increase but at a point, it seemed stuck at around 50%. Eventually, however, we got it to increase by tinkering with the nodes and epochs a little bit. The final problem was to have each data value normalized into a series of values from 0 to 1. It was especially challenging when the values we received were an array of words!
Accomplishments that we're proud of
We are proud of being able to use many different APIs such as pronunciation and a content’s conciseness together. The machine-learning algorithm was also a huge bump for us but being able to make it work was something we are truly proud to present. The model was put through many trials of training while experimenting with many different values for layers, nodes, batch size, and epochs to give the highest accuracy score with the minimal loss value. Finally, the data manipulation which was used to get an overall score was challenging as turning things such as 3 pauses or angry into a numerical value was challenging, but through a series of trials with a logarithmic and exponential function, it was accomplished.
What we learned
Through working on this project, a majority of us got our first experience with flask. Despite that, it is probably one of the easier backends out there as it didn’t take as much setup as spring boot, Django, or even expressjs. Not only that, it was also able to render HTML files which made things a lot easier for us. Through this, our understanding of audio files and their data is a little better, which will be useful for us in the future. Most of all, we pushed our understanding of machine learning, helping us understand individual parts of the neural network better and how it affects the prediction stage after the model has been trained.
What's next for SpeakYourDream
We want to further push the accuracy of our application, especially the parts that use AI.
Built With
- artyom
- azure
- flask
- javascript
- pydub
- python
- scikit-learn
- tensorflow



Log in or sign up for Devpost to join the conversation.