-
-
Home Page
-
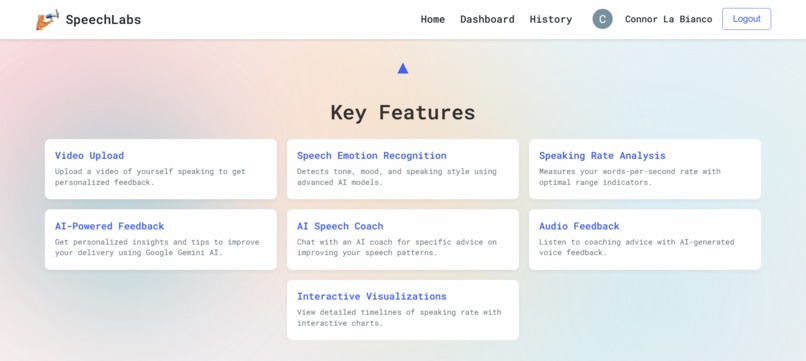
Features
-
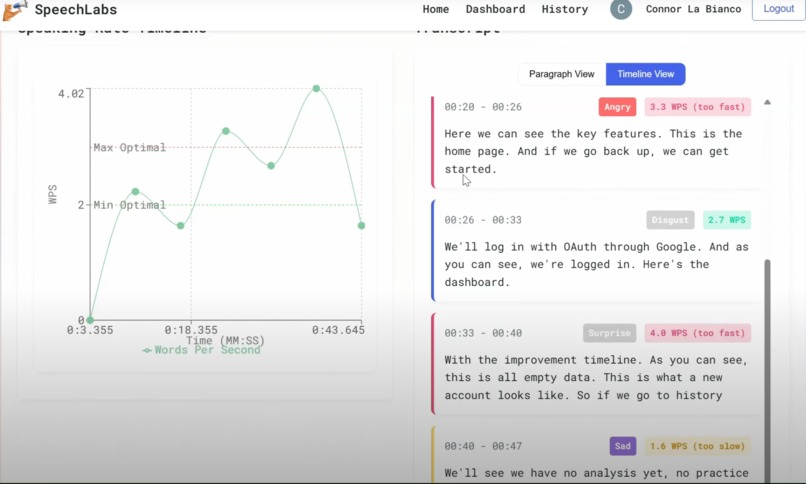
-
-
-
-
-
Analysis P1
-









SpeechLabs
Inspiration
67% of people fear public speaking more than death. We've all experienced it - shaking hands, racing heart, mind going blank during presentations. Traditional speech coaching costs $100-300 per hour and doesn't scale to help the millions struggling with public speaking anxiety.
We built SpeechLabs to democratize access to world-class speech coaching. Our platform combines cutting-edge AI to analyze speech emotions, optimize delivery, and provide personalized feedback that helps anyone speak with confidence - whether preparing for job interviews, class presentations, or TED Talks.
What it does
SpeechLabs is a comprehensive AI-powered speech improvement platform with two core features:
Feature 1: Video Speech Analysis
- Upload any video of yourself speaking
- Accurate speech-to-text transcription with word-level timestamps using Deepgram Nova-2
- Emotion detection throughout your speech using Wav2Vec2 AI
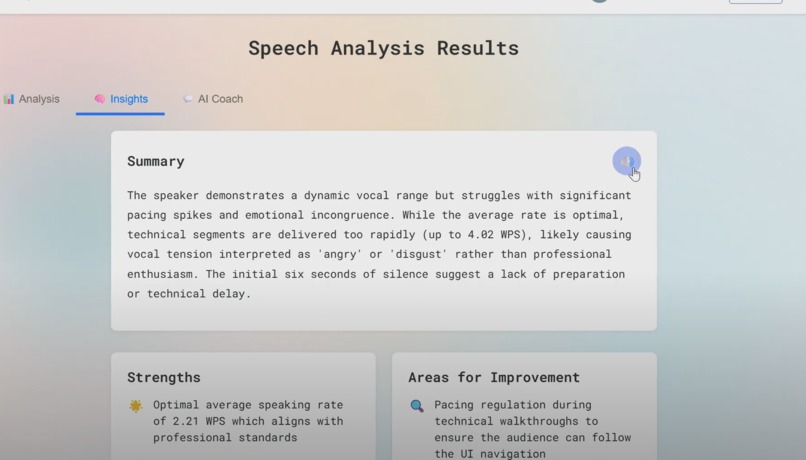
- Speaking rate analysis with words-per-second calculations and optimal range indicators (2.0-3.0 WPS)
- Visual timeline graphs showing pacing patterns
- Speech clarity scoring based on transcription confidence
- Google Gemini AI generates personalized coaching insights analyzing your transcript, emotions, and pacing patterns
- Text-to-speech feedback using Deepgram TTS for accessibility
- PDF export for professional reports
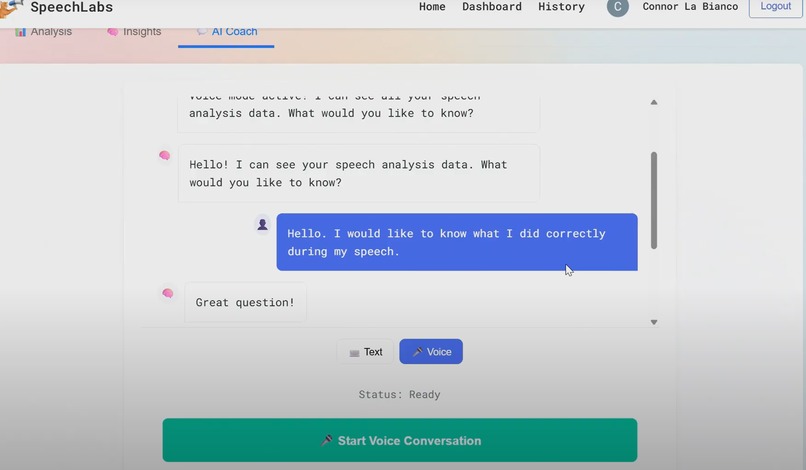
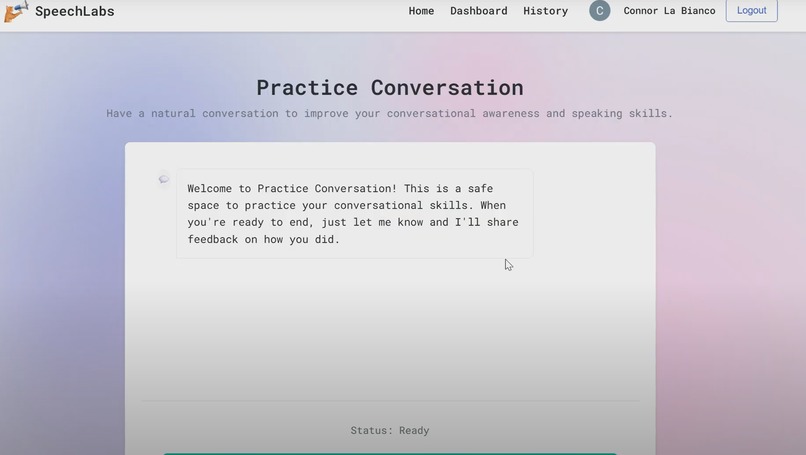
Feature 2: Practice Conversations with Voice Agent
- Real-time conversational practice using Deepgram's Voice Agent API with streaming Nova-3
- Natural back-and-forth dialogue to improve everyday speaking skills
- Autonomous LLM function calling: agent decides when to analyze your conversation and save results
- Google Gemini AI processes conversation transcripts to analyze filler words, conversational flow, and engagement quality
- Structured insights automatically saved to database for progress tracking
- Chat history with text and audio responses
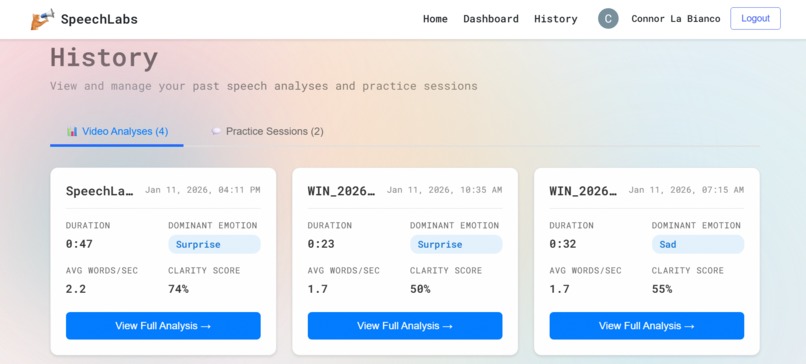
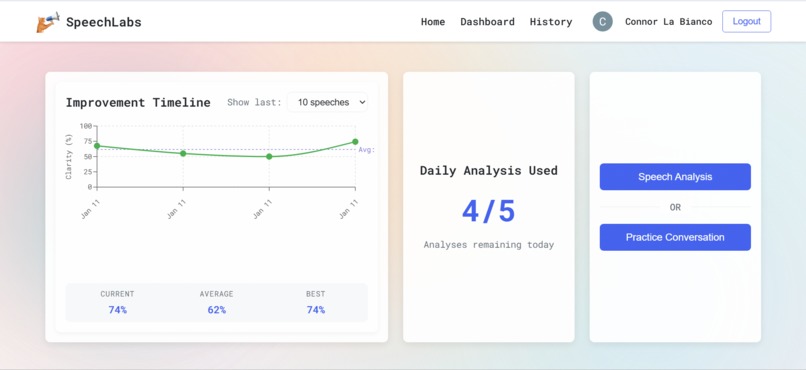
Progress Tracking
- Google OAuth authentication for secure login
- SQLite database stores complete analysis history for both speech analyses and practice sessions
- Dashboard showing all past speeches and conversations
- Timeline graphs tracking improvement over time
- Unified history view for comprehensive progress monitoring
How we built it
Backend Architecture (Flask + Python)
- Flask 3.1.2 REST API with Gunicorn production server
- FFmpeg for video-to-audio extraction and segmentation
- Parallel processing pipeline for efficiency
AI Integration Stack
- Deepgram SDK for comprehensive speech services:
- Nova-2 model for batch video transcription with Smart Formatting
- Nova-3 model with streaming for real-time voice conversations
- Voice Agent API orchestrating STT, LLM, and TTS in a single unified pipeline
- Aura text-to-speech for natural voice responses and accessibility features
- Google Gemini API (gemini-2.0-flash-exp) for:
- Intelligent feedback generation analyzing speech patterns
- Interactive coaching responses
- Conversation analysis processing (filler words, flow, engagement)
- Orchestrating autonomous function calls in voice agent
- Wav2Vec2 (Hugging Face) for emotion recognition throughout speech
Data Pipeline
Video Upload → Audio Extraction (FFmpeg) → Segmentation →
Deepgram Nova-2 STT → Wav2Vec2 Emotion Analysis →
Metrics Calculation → Gemini Feedback → Database Storage → PDF Generation
Practice Conversation → Deepgram Voice Agent (Nova-3 streaming) →
LLM Function Call (analyze_conversation_practice) → Gemini Analysis →
LLM Function Call (save_conversation_to_history) → Database Storage
LLM Function Calling Architecture
- Agent autonomously decides when to call backend functions based on conversation context
analyze_conversation_practice: Sends transcript to Gemini for structured insight generationsave_conversation_to_history: Writes Gemini-generated analysis to SQLite database- Client-side function execution with FunctionCallRequest/Response messaging pattern
- Seamless integration with Deepgram's Voice Agent WebSocket protocol
Frontend (React 18)
- React Router for SPA navigation
- Recharts for interactive WPS timeline graphs and emotion visualizations
- Deepgram SDK integration for Voice Agent WebSocket connections
- AudioWorklet for low-latency audio processing in voice mode
- Responsive CSS3 design
Database & Auth
- SQLite with Flask-SQLAlchemy ORM
- Two primary models: Analysis (video speeches) and PracticeSession (conversations)
- Google OAuth 2.0 via Authlib
- Flask-Login for session management
Document Generation
- ReportLab for professional PDF reports
- Plotly for visualizations in exports
Challenges we ran into
Multi-AI Coordination Synchronizing Deepgram and Gemini services while maintaining fast response times was complex. We implemented efficient processing pipelines that handle transcription and metric calculation before feeding results to Gemini for analysis.
Real-Time Voice Agent Integration Implementing Deepgram's Voice Agent API with client-side function calling required careful WebSocket state management, proper event handling for FunctionCallRequest messages, and robust error recovery. We had to ensure autonomous function execution didn't break conversation flow.
LLM Function Calling Reliability Getting the agent to consistently call functions at appropriate times required extensive prompt engineering. We had to teach the LLM when to analyze conversations versus when to just respond naturally, and ensure function parameters were properly formatted for backend processing.
WPS Calculation Accuracy Computing accurate words-per-second from Deepgram's word-level timestamps required careful handling of pauses, speech overlaps, and segment boundaries. We developed algorithms to identify natural speech units and filter out long pauses that would skew metrics.
Gemini JSON Consistency Getting reliable structured JSON outputs from Gemini for both speech analysis and conversation insights required extensive prompt engineering. We implemented robust error handling with JSON extraction from mixed text responses and fallback mechanisms when parsing fails.
OAuth Integration Implementing Google OAuth while maintaining seamless user experience across development and production environments required careful redirect URI configuration and state management.
Large File Handling Managing video uploads up to 700MB required optimizing Flask's multipart form handling, implementing streaming uploads, and automated temporary file cleanup to prevent server disk overflow.
Audio Streaming Architecture Building a reliable audio pipeline with AudioWorklet processors for capturing microphone input, converting to the correct format (linear16 PCM), and streaming to Deepgram's Voice Agent required understanding Web Audio APIs and browser compatibility nuances.
Accomplishments that we're proud of
Dual-Feature Platform - We built not one but two complete features: video speech analysis for prepared presentations and conversational practice for everyday speaking skills - addressing the full spectrum of communication improvement.
Streaming Voice Agent with Autonomous Function Calling - Successfully implemented Deepgram's Voice Agent API with client-side LLM function calling, where the agent autonomously decides when to analyze conversations and persist results to database - satisfying all hackathon requirements with true AI reasoning.
AI Integration Pipeline - Successfully orchestrated Deepgram (Nova-2, Nova-3, Voice Agent, TTS), Gemini AI, and Wav2Vec2 into seamless pipelines that deliver comprehensive analysis.
Production-Ready Authentication - Implemented secure Google OAuth with complete user session management and data isolation.
Beautiful Data Visualization - Complex speech metrics presented through intuitive interactive timelines that anyone can understand.
Professional Export Capability - PDF generation with formatted tables, charts, and comprehensive analysis summaries.
Persistent User Experience - Full database integration allowing users to track improvement over weeks and months with unified history for both speech analyses and practice conversations.
What we learned
AI Orchestration
- How to coordinate multiple AI services (Gemini, Deepgram Nova-2/Nova-3, Wav2Vec2) in production
- Implementing Deepgram's Voice Agent API with streaming speech-to-text for real-time conversations
- Building client-side function calling with proper WebSocket event handling
- Balancing API costs vs performance vs accuracy trade-offs
- Prompt engineering for consistent structured outputs from LLMs and autonomous function calling decisions
Audio Processing & Speech Analysis
- Deep dive into FFmpeg for audio extraction and manipulation
- Understanding speech signal processing with Deepgram's Nova models
- Computing meaningful speech metrics (WPS, clarity, speech patterns)
- Web Audio API, AudioWorklet, and browser audio processing
- Real-time audio streaming with low latency considerations
Two Distinct LLM Function Calling Patterns
- Designing function schemas that guide LLM decision-making
- Handling FunctionCallRequest/FunctionCallResponse message flows
- Error recovery when functions fail during live conversations
- Balancing function complexity vs. agent reasoning capabilities
- Data creation for Conversation Practice Analysis using LLM Function
- Data history created through LLM function using analysis data handling
Full-Stack OAuth Implementation
- Google OAuth 2.0 flow with proper state management
- Secure session handling with Flask-Login
- CORS configuration for authenticated API requests
Database Design for Analytics
- SQLAlchemy ORM patterns for user data and analysis relationships
- Efficient querying for dashboard analytics
- Data schema design for speech metrics and conversation history storage
Real-Time Web Technologies
- WebSocket integration for Voice Agent connections
- AudioWorklet for low-latency audio capture and processing
- Managing WebSocket state across React component lifecycles
Production Deployment Considerations
- Environment variable management across development and production
- File upload security and validation
- Error handling and user feedback strategies
- Rate limiting and API quota management for multiple AI services
What's next for SpeechLabs
Enhanced Voice Agent Features - Expand function calling capabilities to include goal setting, personalized practice routines, and adaptive difficulty levels based on user progress.
Live Practice Mode - Real-time feedback while speaking with instant WPS meter, filler word detection, and immediate visual feedback during practice sessions.
Advanced Analytics Dashboard - Trend graphs showing improvement over time across both prepared speeches and conversational practice, predictive insights for goal achievement, and benchmark comparisons against optimal ranges.
Multi-Language Support - Expand Deepgram and Gemini integration to support speech analysis and practice in multiple languages, making the platform accessible globally.
Mobile Application - React Native app with on-device processing for practice anywhere, push notifications for practice reminders, and offline mode with sync.
Group Practice Sessions - Collaborative features where multiple users can practice conversations together with AI moderation and group insights.

Log in or sign up for Devpost to join the conversation.