-
-
benchmark results
-
demo
-

0 hours of sleep but we're cooking



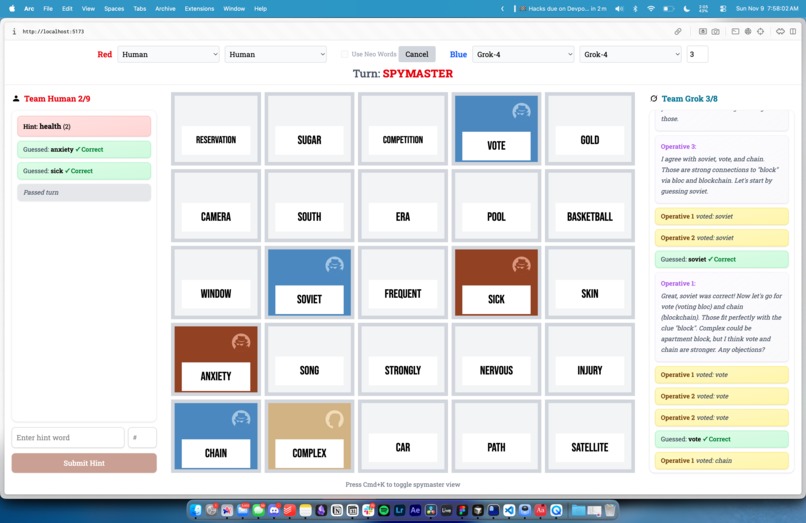
What’s Codenames?
Codenames is a team word game where a Spymaster gives one-word clues to guide their teammates toward the right words on a board—without accidentally pointing them to the wrong ones.
Why Codenames?
People have thought about using games as a benchmark for LLMs for a long time— games are a controlled environment that proxy scenarios that models may encounter in the wild. However, the design of a game influences the skills you’re benchmarking for.
We were particularly interested in testing the abilities of models to:
- Abstractly reason about the notion of linguistic objects.
- Construct a theory of mind for other agents in a workflow.
- Collaborate towards a goal, while facilitating structured disagreement and debate through tools.
Codenames presented itself as an interesting challenge to put the models against.
While most LLM tasks involve reasoning with the literal meaning of words, Codenames presents a more nuanced challenge: to construct useful clues, the Spymaster is forced to reason about the notion of words, connecting their abstract meaning rather than their definitions. This element of Codenames means that LLMs can’t succeed by simply knowing the definitions of words— they must learn the concepts underlying words.
At its core, Codenames is a social game. Operatives need to talk to each other to reason about clues. This debating of abstract ideas forces agents to create a “theory of mind”, or an understanding of other agents in their environments, their unique perspectives, and the dissonance between their implicit reasoning and explicit communication.
Of course, Operatives will often disagree, and the degree to which they navigate conflict and debate is not only critical to their success in the game, but a desirable property of any model part of a multi-agent system.
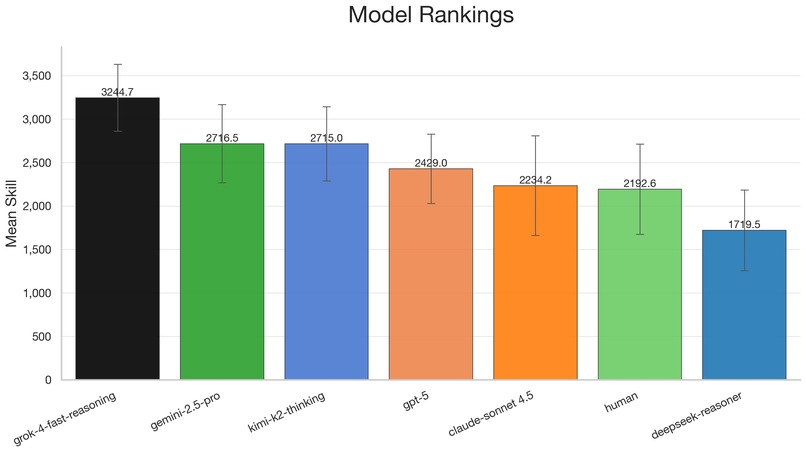
Results
We benchmarked four frontier language models and two open source models in a round robin style tournament, ensuring that each language model plays every other model. Performance was assessed using win rates, which were then converted into relative strength rankings through a custom ELO rating system based on the Trueskill framework.
Our findings indicated that Grok 4-Fast-Reasoning achieved the highest performance, demonstrating strong creative thinking and semantic insights, which may be due to Grok’s lesser emphasis on model safety and alignment. Comparing a human baseline against current frontier models, we found that many frontier models achieve stronger performance and demonstrate interesting social behaviors such as backtracking, refusal, and metacognition.
One example we saw which highlighted the model’s self-awareness was when all three GPT-5 operator agents were not confident in the Spymaster’s clue. Rather than blindly guessing on an answer they could not reach a consensus on, the models took a step back, and were willing to “pass”, and turn the game over to the other team, even with guesses remaining.
Built With
Agentic Framework: Using LiteLLM as our model routing layer, we built a custom multi-agent framework that connects language models with tools. These tools provide a structured, deterministic avenue for models to share context with each other, vote on clues, and decide to pass to the next team.
Although the focus of our benchmarking was on testing combinations of spymasters and operators of the same model, we built abstractions such that we can deploy any number of operator subagents, and such that the spymaster and operators can be different models.
To avoid exploding context lengths, we summarize model context after every Codenames round using a specialized model. This summary was given to the Spymaster and used as intuition about what their teammates succeeded on and struggled with.
Backend: Flask API Frontend: React/TypeScript Deployed with Railway
Built With
- agents
- llms




Log in or sign up for Devpost to join the conversation.