-
-

the loading screen
-
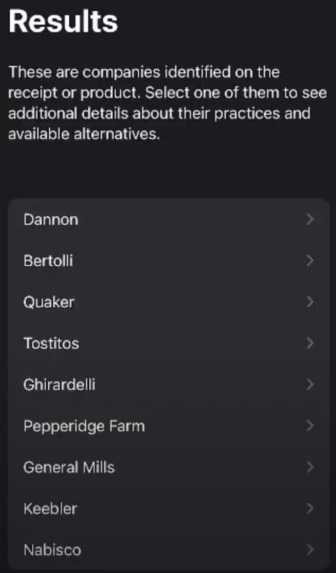
List of brands found on the receipt
-
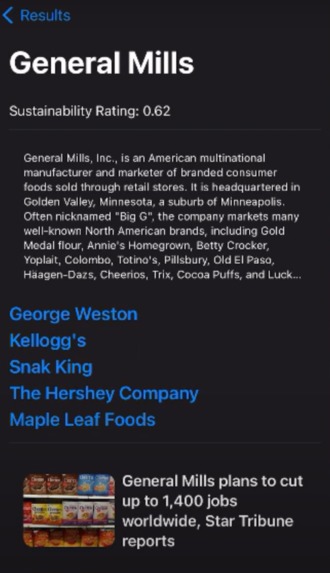
Information we have of a specific brand



Inspiration
In recent years, many businesses have come under fire for the atrocious business practices that they implement in order to produce their goods. Most prominently, Nestle, a major company responsible for dozens of brands has been exposed for stealing drinking water from poor international communities, and using child labor. They have largely escaped without punishment due to their large size. It can be hard to avoid buying from Nestle in particular simply due to the number of brands they control, making it hard for people to boycott Nestle and take a stand. We decided to create a project that would streamline this process for people, making it easy for them to only buy from brands that they know are sustainable and ethical.
What it does
In order to make a statement on this issue, we created Sustainabrand, an app that can scan your receipts to tell you if you've been buying from the right companies and, if not, suggest alternative brands that produce similar goods in a more sustainable way. This way, we give power to the consumer to put pressure on large businesses.
How we built it
In order to suggest alternatives, we decided to create brand embeddings, which is a form of unsupervised machine learning to determine what brands are similar to each other. We used the MediaWiki API to create a dataset using a Wikipedia page full of Wikipedia URLs of food companies all over the world. We collected the page ids and their titles from those URLs. After cleaning the dataset, we had a list of over 1000 brands. Next, we needed to create the embedding space themselves. We downloaded Stanford's GLoVE model, which is a word embedding model with around 200 dimensions. We again used the MediaWiki API to go through our list of brands and gather the contents of their respective wiki pages. We used the NLP Toolkit Python package to create the embedding. We performed this process for all 1 thousand brands. Finally, the embeddings were exported to a JSON file.
The second challenge was to figure out which companies were good and bad. We used a web scraper to scrape through google searches of certain brands to collect news articles. We then used HuggingFace, a Natural Language Processing library, to perform sentiment analysis to determine if those articles were overall positive or negative. We use those scores to calculate a final score for each brand so that the user can determine if they are buying the right products or not.
The third challenge was scanning and recognizing brands from a receipt. We used OpenCV2 to process the receipt image and Optical Character Recognition (OCR) to recognize the words from the image. The word embeddings file was imported into a MongoDB database to be accessed at any time by the FastAPI server. The front end makes a request to the server to get the necessary data to display to the user.
All of this backend code powers a front-end UI created using Swift.
Challenges we ran into
It was really difficult finding a suitable dataset of food brands. We experimented with an open-source dataset of 3k brands, but it was far too big to completely go through and it included many non-food brands. We initially tried using the Pythonic wrapper for the Wikipedia API but realized that it was severely outdated and ended up having to figure out how to use the MediaWiki API itself. Moreover, since we decided to create an IOS native app, we had to learn how to write a proper backend that could communicate with the front end. Most of our team also had no access to IOS devices and so we had to test our backend code using curl requests.
Accomplishments that we're proud of
We're proud of learning how to implement our data science skills for a full-stack app. Most of us never had experience dealing with data this large and trying to set up a database to host it. We are also proud of overcoming our previously stated challenges in the data science aspects of this project, all within 36 hours.
What we learned
We learned how large machine learning models can be hosted locally to be implemented into a full-stack app. This includes learning how to import large datasets into MongoDB and using FastAPI to set up an API request server so that the frontend can communicate with the backend. We also learned more about native app development.
What's next for Sustainabrand
In the future, we plan to build out various features even more. In the app, we plan to let users separate brands and items by type of food/drink, and even branch out into many other types of products. Currently, our app is based around the food industry, but we will change this in the future, to all types of products. We hope to provide information on local product availability, pricing, and other information to streamline the user's experience in buying from new brands. Finally, we will also include functionality to create a shopping list inside the app itself, making the app double as both something one can use to buy from more sustainable brands and a regular shopping list.

Log in or sign up for Devpost to join the conversation.