-
-

Thumbnail
-
UI/UX
-
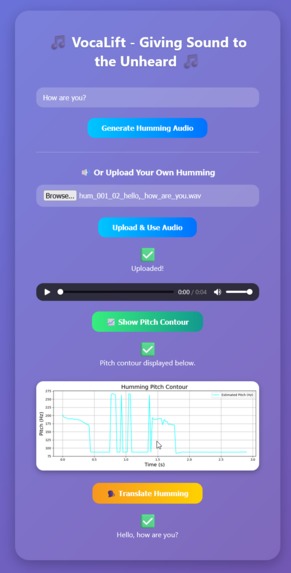
Huming to Text



Inspiration
VocaLift was born out of the idea of giving voice to those who cannot speak — whether due to physical, neurological, or situational limitations. The question inspired us: "Can nonverbal sounds like humming express meaningful communication?" With recent advances in generative AI and speech modeling, we saw an opportunity to bridge the gap between nonverbal vocalizations and understandable language using expressive audio synthesis and intelligent translation.
What it does
VocaLift enables users to:
- Convert written sentences into expressive humming using generative audio models.
- Upload their own humming audio and analyze its pitch contour
- Translate humming sounds back into human-readable sentences using a trained model.
- Visualize the pitch dynamics of the generated or uploaded audio, helping understand the prosody and tone of the vocalization.
How we built it
- Frontend: Built using vanilla HTML/CSS/JavaScript, with a clean UI and smooth interactions.
- Backend: Python + Flask server to handle generation, uploads, and audio processing.
- Audio Generation: We used Meta's facebook/audiogen-medium model via audiocraft to synthesize humming-like audio from natural language prompts.
- Translation: A custom LSTM-based PyTorch model that learns to map humming audio features (e.g., Mel-spectrogram) back to text.
- Pitch Analysis: Leveraged librosa and matplotlib to estimate and visualize pitch contours from the generated or uploaded audio.
- In-memory audio handling for efficient streaming and reuse across multiple operations.
Challenges we ran into
- Generating speech-like humming was tricky — prompting a generative audio model to create nonverbal vocalizations required prompt engineering and a lot of experimentation.
- Data limitations for training the translator model — there's no off-the-shelf dataset that maps humming to text, so we had to create synthetic data for prototyping.
- Timing and synchronization — making sure pitch analysis and playback stayed smooth on the web frontend.
- Audio format compatibility when accepting uploaded files (MP3/WAV) and ensuring librosa could read them correctly.
- Deployment and model size — the models used are fairly heavy and required careful resource management
Accomplishments that we're proud of
- Successfully created a bidirectional pipeline — from text to humming and back to text.
- Designed a visually clean and intuitive interface that’s friendly even for non-technical users.
- Engineered a way to generate meaningful nonverbal audio expressions using text prompts.
- Built in pitch contour analysis, which adds a unique layer of introspection and debugging for speech-like signals.
What we learned
- Prompt engineering plays a huge role in guiding audio generation models.
- Pitch contours carry significant emotional and semantic cues, even in the absence of words.
- Synthesizing and decoding nonverbal vocalizations is a promising, underexplored area with real potential in accessibility and affective computing.
- Importance of combining ML + UX + Accessibility in a seamless way.
What's next for VocaLift
- Real-time humming-to-text translation via microphone input
- Training a larger model using human-annotated humming datasets
- Deploying as a public web app using Streamlit, Gradio, or Flask + frontend hosting
- Collaborating with speech therapists or accessibility researchers to test in real-world settings
- Adding waveform visualizations and voice style customization
- Mobile support to allow anyone to speak with a hum


Log in or sign up for Devpost to join the conversation.