-
-
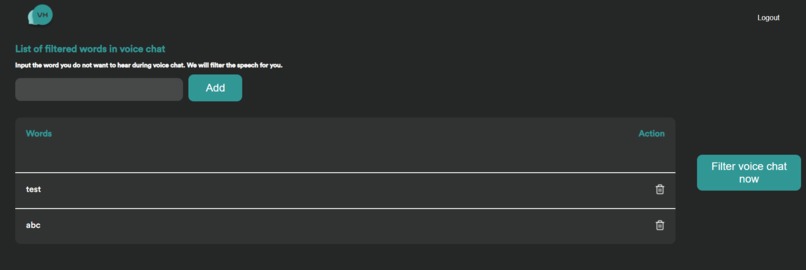
Front End in MVP
-
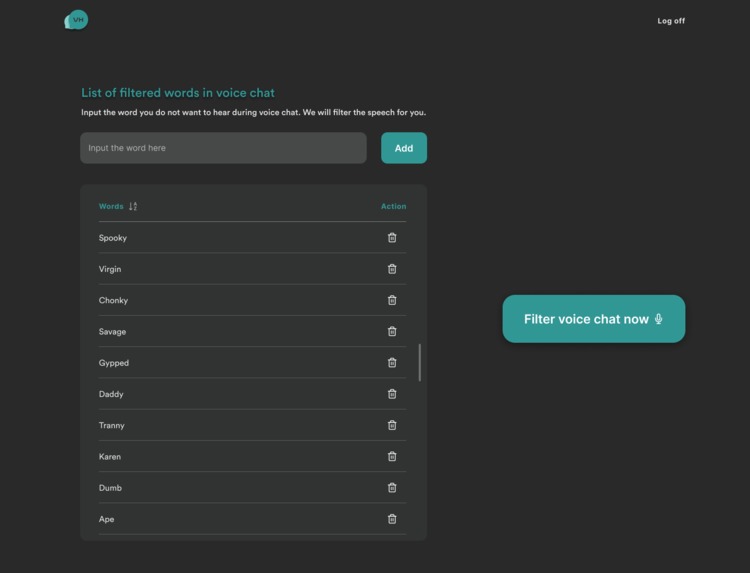
Home page - with list of added words
-
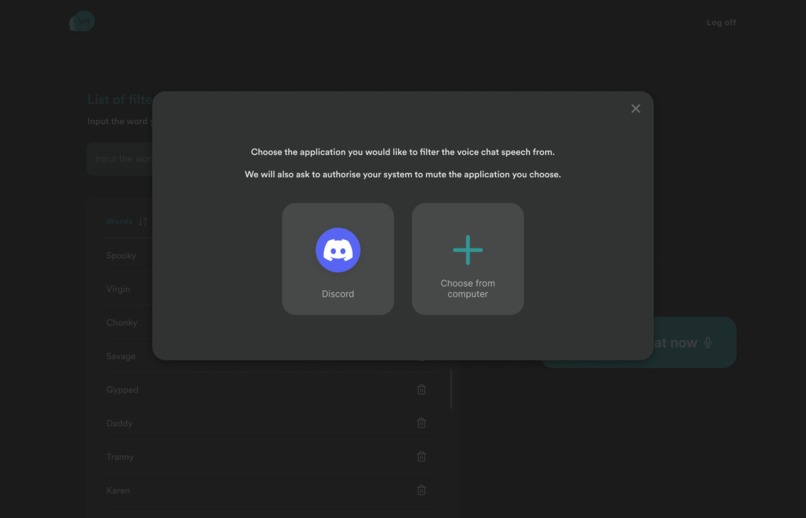
choose voice chat source
-
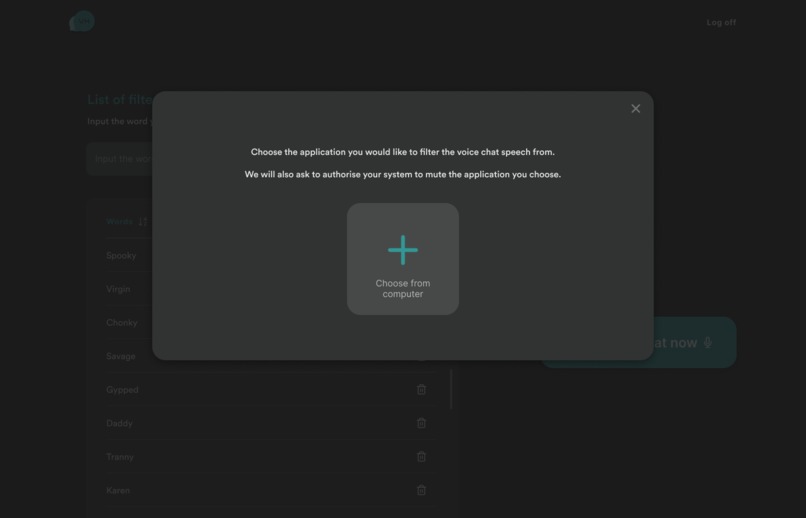
choose voice chat source
-
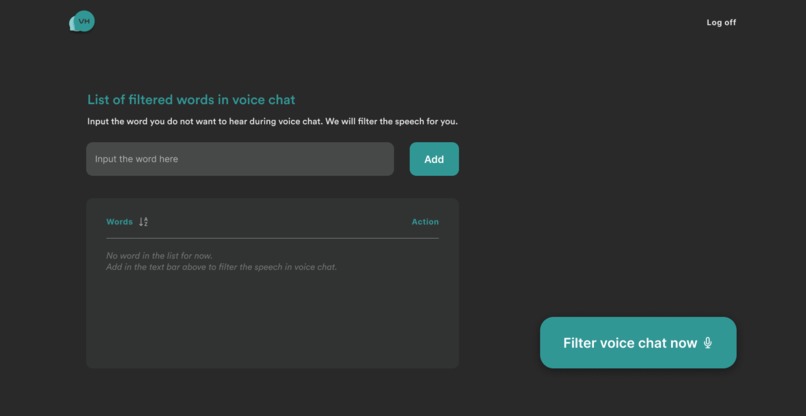
Home page - deleted all words
-
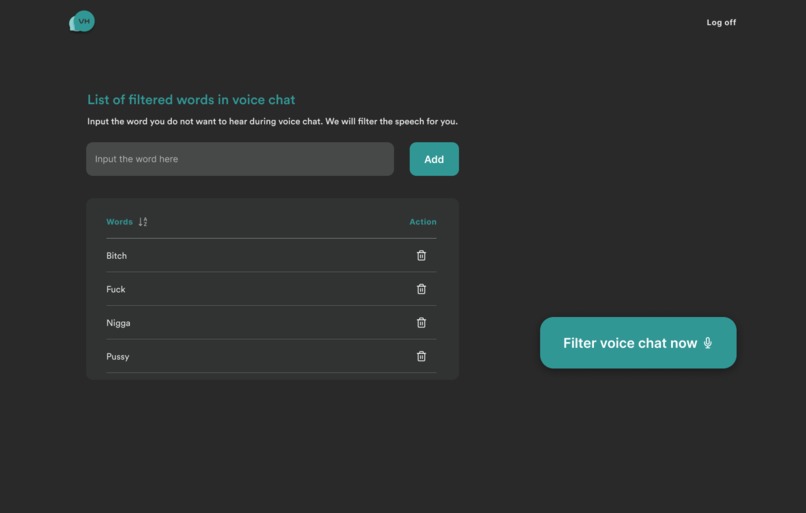
Home page default
-
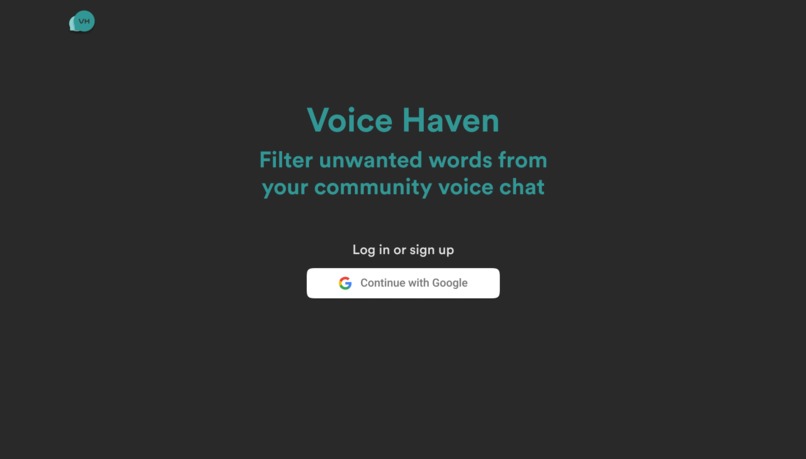
Login
-

Caption and ai voiced filtered speech interface








Inspiration
We have female gamers in our team who feel the toxicity while gaming with a bunch of people out there. That’s why we did our user and desk research on what causes the uncomfortableness.
Marginalized people (especially female, different races, LGBTQ) feel toxic and uncomfortable in voice chat experience during gaming, because some personally unwanted conversation and insulting words are usually unavoidable during voice-chatting in games.
What it does
Our solution - Voice haven captures the speech from other gamers in the voice chat, then filters out the words that you do not want to hear, and out put the filtered captions and speech with minimal delay to accommodate real time fast paced gaming.
The solution helps user to filter out insulting words / topic in the voice chat that is uncomfortable to the user
The user flow is illustrated as below: User opens Voice Haven → Log in to your account to access the list of our personalised unwanted words → add list of unwanted words → click filter voice chat → choose the voice chat source to filter → return with filtered caption and speech
How we built it
The database to contain users and their list of words they do not wish to hear was implemented using MongoDB and node.js which were stored as endpoints to be called from the backend local server. Our translation model is a python model which takes in microphone input from the user’s computer and uses Whisper to convert that into text. The frontend was coded using React and NextJS to implement the UI. Google authentication was used as a login system.
Challenges we ran into
Some challenges we ran into was originally having to retrieve vocal input from the user’s microphone through the our front-end UI through React. We often ran into issues where the resulting wav files would become corrupted. Eventually we settled on microphone input from python and drove it through a voice-to-text ML model which both solved the issue of having to integrate the .wav files with Speech-To-Text API and censor model.
We also had to figure out how to host the frontend in a way that was separate from the backend, and have it so that the frontend would not be blocked from sending and receiving information to the backend, which we solved by using two separate ports and implementing CORS.
Accomplishments that we're proud of
We are particularly proud of the fact that we were able to build a functional voice to speech translation model that was able to successfully integrate with our front-end UI! This was definitely the most challenging aspect of our project and was the central element in terms of its goals.
What we learned
We learned how to build an aesthetic UI in ReactJS, hook up database end points from the front end to the backend, learned how to integrate Google Authentication into our project. We also learned about the Next.js framework and its various functionality.
What's next for Voice Haven
As Voice Haven is in it’s starting stage, it has much room to improve. The future steps would be creating a text-to-speech of the captions to improve the experience of gaming for a wider range of people. It is also important to us that Voice Haven can be used with many different video games. Thus, we are planning to make Voice Haven compatible with many different applications. We also plan for Voice Haven to be an in-game overlay in the future. We believe that Voice Haven has the potential to grow into a wide-used video game overlay that will improve assessability for people who are hard of hearing and improve the overall gaming experience of marginalized groups such as women. Which in turn allows them to feel more welcomed and safe in the community.
Built With
- google-authentication
- javascript
- mongodb
- nextjs
- node.js
- python
- react
- whisper

Log in or sign up for Devpost to join the conversation.