-
-
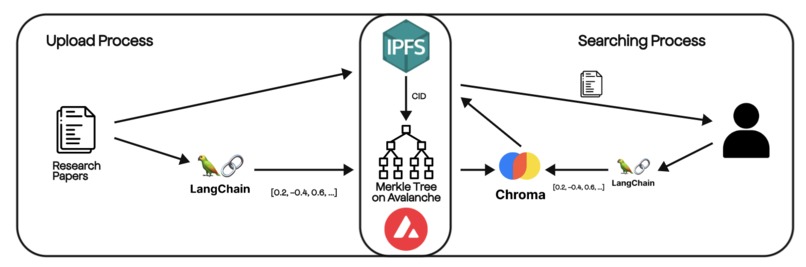
System Design
-
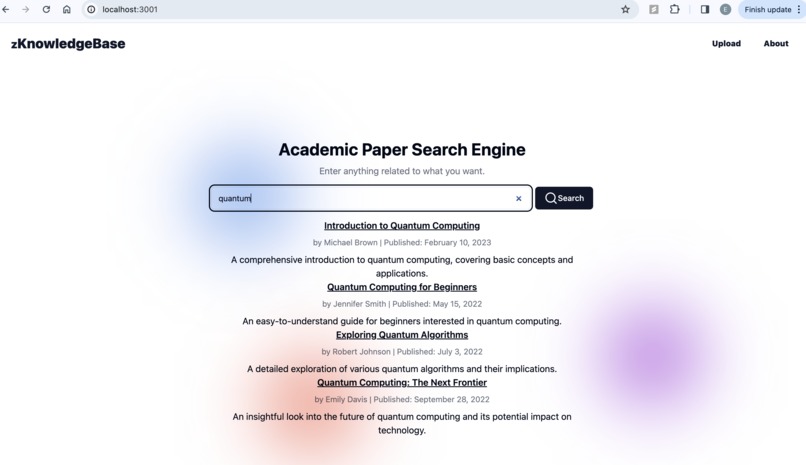
ZKnowledgeBase


Inspiration
One of my team members, Thor, was looking for citations for his psychology research paper while on the bus ride up from SoCal. He had a psychology paper due and as he scrambled to finish the assignment, he struggled to find articles to cite due to the fragmented landscape of paywalled academic journals and lackluster indexing. We looked into his problem and realized that research is very unfriendly to those without the means.
Access to Academic journals are expensive (>$500) for one person and the biggest commercial indexers such as Web of Science or Scopus will charge you for using their search. Open source alternatives such as IEEEExplore and arXiv either do not have the breadth of research or lack vetting as preprints. A further exigence is the detrimental nature of science journalism that fuels a cycle of misleading publications. When scientists are at the mercy of research journals to expose their work for grants and journals need clicks to drive revenue, the scientific community as a whole pays the price. This felt like an issue that needed to be tackled.
zKnowledgeBase is a decentralized research platform that eliminates paywalls, enables free sharing of verified research without third-party control, and mitigates censorship risks - empowering academics with open and unbiased access to knowledge.
What it does
We built a decentralized web platform allowing users to search and store research articles, immutably and forever. Users can upload research PDFs and search for articles using our vector-embedded search. We secure our articles with a Merkle Tree, where the root is publicly available on the Avalanche Blockchain.
How we built it
We allow users to upload research papers in PDF form. We store their submissions on IPFS, a distributed ledger designed for file storage, allowing for reliable uptime and free access. At the same time, we chunk and vector embed the paper, using LangChain and together.ai to render the paper into a multiple hundred dimensional vector, stored in ChromaDB's vector database. When the user searches with our platform, we vector embed their search query and use cosine similarity to compare the search vector to the stored vectors in the vector database. We then present the most similar papers in a scrollable format. Finally, we used a Merkle tree built with Zig for submission security and to verify that papers retrieved from IPFS came from our uploads.
Challenges we ran into
We used a lot of new technologies for the first time including Merkle Trees, Zig, Vector Databases, and we had to read a lot of documentation and learn quickly to finish on time. The integration of the front end and backend took some time.
Accomplishments that we're proud of
We used Zig for the first time and managed to code a complicated Delta Merkle Proof quickly and correctly despite time constraints. We were able to follow a plan from ideation to submission.
What we learned
We learned that it is important to budget your time wisely and spend time with system design.
What's next for zKnowledge Base:
RICHER METADATA: Publication, # of Citations, etc INCENTIVIZE UPLOADS: Spread the word and get more engagement TOKENS: Distribute tokens for decentralized governance





Log in or sign up for Devpost to join the conversation.