This is a direct followup of yesterday’s post. There is a bunch of great stuff I didn’t know in the exercises of Chapter 2 of Isaacs’ book, again much of it focused on getting control over the degrees of the characters of a finite group. Let me just get right into it:
Proposition: Let  be a finite abelian group. Let
be a finite abelian group. Let 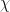 be a character of (not necessarily irreducible). Then
be a character of (not necessarily irreducible). Then

The first inequality is an equality if all the irreducible components of are distinct; the second is an equality if they are all identical.
This is (essentially) Problem (2.9a). (I’m throwing in the 2nd inequality and the comments about when equality occurs.) This is setup for an epic punchline; see below.
Proof: The quantity

is the canonical inner product  on the
on the  -linear space of characters of (equivalently, functions on , since it’s abelian). Now the character is a sum of irreducible characters; because is abelian, they are all linear, i.e., they each have degree
-linear space of characters of (equivalently, functions on , since it’s abelian). Now the character is a sum of irreducible characters; because is abelian, they are all linear, i.e., they each have degree  , so
, so  is how many there are. By the Schur orthogonality relations, all the irreducible characters have norm 1 with respect to the inner product
is how many there are. By the Schur orthogonality relations, all the irreducible characters have norm 1 with respect to the inner product  , and are also orthogonal with respect to this inner product.
, and are also orthogonal with respect to this inner product.
Picture the space of characters of as a finite-dimensional (actually  -dimensional) Hilbert space, with the irreducible characters an orthonormal basis; then all the characters are the lattice points in the nonnegative orthant. Call the irreducible characters
-dimensional) Hilbert space, with the irreducible characters an orthonormal basis; then all the characters are the lattice points in the nonnegative orthant. Call the irreducible characters  , to suggest thinking of them as a standard orthonormal basis for the space. Then because the character is a sum of (not necessarily distinct) elements of this basis, it satisfies
, to suggest thinking of them as a standard orthonormal basis for the space. Then because the character is a sum of (not necessarily distinct) elements of this basis, it satisfies

where each 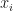 is a nonnegative integer and
is a nonnegative integer and  . In other words, is a lattice point somewhere on the simplex defined by the intersection of the hyperplane with the nonnegative orthant
. In other words, is a lattice point somewhere on the simplex defined by the intersection of the hyperplane with the nonnegative orthant  . If
. If  , then
, then  of the ‘s have to be 0, in which case is even on the lower-dimensional simplices defined by the same equation but summed only over the nonvanishing ‘s.
of the ‘s have to be 0, in which case is even on the lower-dimensional simplices defined by the same equation but summed only over the nonvanishing ‘s.
In any case, we are now in real Euclidean geometry land! The question is this: given such a point , what’s the biggest and smallest that its norm (which is  , a.k.a.
, a.k.a.  , because the
, because the  ‘s are orthonormal) can be?
‘s are orthonormal) can be?
I say that the smallest norms are the points where distinct ‘s are , the rest zero. And the biggest norms are the points where one is , the rest zero. My conviction about this rests on picturing the simplices I just described, and maybe you are already convinced with similar geometric reasoning. It amounts to saying that the closest point to the origin of a standard simplex  in Euclidean space is the center point, and the farthest points from the origin are the vertices. I assume/hope this is a standard thing.
in Euclidean space is the center point, and the farthest points from the origin are the vertices. I assume/hope this is a standard thing.
Anyway, if is a vector in a Euclidean inner product space that is a sum of distinct orthonormal vectors (the minimum case), then  . If it is times a single unit vector, then
. If it is times a single unit vector, then  . So in general, it lies between these two values, reaching the extremes under precisely these two conditions. We get the inequalities in the proposition by multiplying everything by . 🐯
. So in general, it lies between these two values, reaching the extremes under precisely these two conditions. We get the inequalities in the proposition by multiplying everything by . 🐯
Okay, you ready for the punchline? Here you go!
Theorem: The degree of any irreducible character of a finite group is bounded above by the index of any abelian subgroup. 😲
This is Problem (2.9b) in Isaacs!
Proof: Let 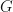 be a finite group, let be an abelian subgroup, and let be an irreducible character. Then
be a finite group, let be an abelian subgroup, and let be an irreducible character. Then

where the first equality is the fact that is irreducible (so has norm 1 with respect to the inner product on characters of ), the middle inequality is because the summands are all nonnegative reals and the second sum is a sub-sum of the first, and the final inequality is precisely the above proposition applied to the abelian group  .
.
Dividing through by , we get ![[G:A]\geq \chi(1)](https://s0.wp.com/latex.php?latex=%5BG%3AA%5D%5Cgeq+%5Cchi%281%29&bg=ffffff&fg=111111&s=0&c=20201002) !!! ✨
!!! ✨
Okay again I am out of time! More soon hopefully.
Addendum 6-25-2021: Something I didn’t have time to mention yesterday but wanted to say. Part of the reason the theorem given above was so striking to me is that it resonates a little with a theorem I proved! And I want to discuss the relationship (mainly to give myself the opportunity to properly think through it).
I wrote a paper with Fedor Bogomolov (journal | arXiv) analyzing a pair of representation-theoretic properties we call purely noncommuting (PNC) and strongly purely noncommuting (SPNC). I’m gonna quickly explain our inquiry and mention some of our results, including the relevant one and its proof, and then ponder what it has to do with the above.
Ok:
Two diagonalizable matrices that commute with each other share a full basis of eigenvectors. Two matrices that don’t commute won’t share a full basis of eigenvectors, but they can still share eigenvectors, and their restrictions to the subspace spanned by the common eigenvectors do commute. So you can see “sharing eigenvectors” as “partial commuting”. In this context, we ask: suppose you have two elements 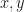 in a finite group that don’t commute. Can you find a representation of in which the associated matrices “noncommute purely” (i.e., don’t share eigenvectors)? We call a group that has such a representation for each noncommuting pair a purely noncommuting (PNC) group. In this definition, the representation is allowed to depend on the pair . If the group even has a representation that simultaneously avoids any shared eigenvectors for all noncommuting pairs at once, we call it strongly purely noncommuting (SPNC). Our inquiry was an investigation of the questions: Which groups are PNC? Which are SPNC?
in a finite group that don’t commute. Can you find a representation of in which the associated matrices “noncommute purely” (i.e., don’t share eigenvectors)? We call a group that has such a representation for each noncommuting pair a purely noncommuting (PNC) group. In this definition, the representation is allowed to depend on the pair . If the group even has a representation that simultaneously avoids any shared eigenvectors for all noncommuting pairs at once, we call it strongly purely noncommuting (SPNC). Our inquiry was an investigation of the questions: Which groups are PNC? Which are SPNC?
The main results of our paper are that: (a) supersolvable groups (including nilpotent groups) are always PNC; (b) nonabelian simple groups are never PNC; (c) metabelian groups are not PNC in general, but if a metabelian group has the property that when its commutator is decomposed as a product of cyclic groups of prime-power order, the factors are pairwise nonisomorphic, then it is PNC. We also have a pair of other results. One characterizes group-theoretically when a pair of permutations noncommute purely in the standard representation of  . The other one is the one I want to talk about.
. The other one is the one I want to talk about.
It’s this: If a finite group has an irreducible character whose degree exceeds the index of any of its nonabelian subgroups, then it is (not only PNC) but SPNC. (And the representation corresponding to that character realizes it as SPNC, i.e. no two noncommuting elements of share an eigenvector in that representation.)
This is Proposition 5.1 in both the journal and arXiv versions of our paper. The hypothesis is, incidentally, (sufficient but) not remotely necessary for a group to be SPNC.
Anyway, this theorem is basically a consequence of Frobenius reciprocity. (Proof:) Say the representation space in question (with degree exceeding the index of any nonabelian subgroup) is  , and (hoping for a contradiction) suppose are two noncommuting elements of that have a common eigenvector in . Let
, and (hoping for a contradiction) suppose are two noncommuting elements of that have a common eigenvector in . Let 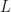 be the one-dimensional subspace of spanned by the common eigenvector. Then is a one-dimensional representation of the nonabelian subgroup
be the one-dimensional subspace of spanned by the common eigenvector. Then is a one-dimensional representation of the nonabelian subgroup  , and the number of copies of inside the restriction of to
, and the number of copies of inside the restriction of to 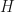 is at least one. On the other hand, by Frobenius reciprocity, the number of copies of in the restriction of to is equal to the number of copies of in the induced representation
is at least one. On the other hand, by Frobenius reciprocity, the number of copies of in the restriction of to is equal to the number of copies of in the induced representation  . But because is one-dimensional, this induced representation has dimension
. But because is one-dimensional, this induced representation has dimension ![[G:H]](https://s0.wp.com/latex.php?latex=%5BG%3AH%5D&bg=ffffff&fg=111111&s=0&c=20201002) , which by hypothesis is smaller than
, which by hypothesis is smaller than  because is nonabelian. So the number of copies of in
because is nonabelian. So the number of copies of in  must actually be zero, and therefore the number of copies of in ‘s restriction to must be zero. This is the desired contradiction. 🐞
must actually be zero, and therefore the number of copies of in ‘s restriction to must be zero. This is the desired contradiction. 🐞
Okay. So lemme just mention that while this result plays only a minor role in our paper, it is a little nostalgic for me personally because it was chronologically the first fact I proved as part of the research that eventually became my PhD thesis. Anyway, what does it have to do with the above?
Well, ok, the above thing in Isaacs says that irreducible character degrees cannot ever exceed the indices of any abelian subgroups. My theorem just described says that if an irreducible character degree exceeds the indices of all nonabelian subgroups, then something cool (namely SPNCness) happens.
Now it was clear to me when I proved it that the hypothesis of my theorem was a somewhat special property of a group. Being SPNC is already a pretty special property, and the condition of my theorem is sufficient for it, but not necessary, so this condition is strictly rarer. Indeed I did a fair amount of work to construct an interesting example. (The hypothesis is met by minimal nonabelian groups, but there are easier ways to see they are SPNC than the above. The example I constructed, for which the above theorem actually informed me it was SPNC, was a certain subgroup of the affine group  , where
, where  is a prime congruent to 1 mod 4. See Proposition 1.1.49 of my thesis for the details.) The theorem I learned from Isaacs’ Problem (2.9b) above is making me appreciate a particular dimension of the specialness of this condition.
is a prime congruent to 1 mod 4. See Proposition 1.1.49 of my thesis for the details.) The theorem I learned from Isaacs’ Problem (2.9b) above is making me appreciate a particular dimension of the specialness of this condition.
In general, the little subgroups of a nonabelian finite group tend to be abelian (e.g., the cyclic subgroups), while the bigger subgroups tend to be nonabelian (since as they contain more of the elements, they have a better shot at containing noncommuting pairs). However, it is not in general the case that all the nonabelian subgroups are bigger than all the abelian ones. For example, just take the direct or semidirect product of a little nonabelian group with a big abelian group.
On the other hand, taking into account the above theorem from Isaacs’ Problem (2.9b), you can see that the condition of my theorem actually requires every nonabelian subgroup to be larger than every abelian subgroup. The condition assumes there is an irreducible representation whose degree is bigger than the index of every nonabelian subgroup  . But Isaacs’ thing says that this degree bounds the index of every abelian subgroup below. In other words, for the hypothesis to be met, we have to have
. But Isaacs’ thing says that this degree bounds the index of every abelian subgroup below. In other words, for the hypothesis to be met, we have to have
![\dim V > [G:H]](https://s0.wp.com/latex.php?latex=%5Cdim+V+%3E+%5BG%3AH%5D&bg=ffffff&fg=111111&s=0&c=20201002)
for every nonabelian subgroup , but Isaacs tells us that
![[G:A] \geq \dim V](https://s0.wp.com/latex.php?latex=%5BG%3AA%5D+%5Cgeq+%5Cdim+V&bg=ffffff&fg=111111&s=0&c=20201002)
for every abelian subgroup . It follows that  for every abelian and nonabelian ! 🌵
for every abelian and nonabelian ! 🌵


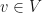

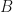













 in a finite group
in a finite group  , we have
, we have 
 are conjugate, then we also have for any
are conjugate, then we also have for any 
 , and
, and  is real. Conversely, if
is real. Conversely, if  , and
, and  for every integer
for every integer  prime to the order of
prime to the order of  ), we’re working with the whole Galois group of a cyclotomic field big enough to contain all of the character values. Specifically:
), we’re working with the whole Galois group of a cyclotomic field big enough to contain all of the character values. Specifically: , let
, let  be a primitive
be a primitive  . Any character value of
. Any character value of  generates a Galois automorphism
generates a Galois automorphism  , and every Galois automorphism has this form. By choosing a diagonal basis for a given group element
, and every Galois automorphism has this form. By choosing a diagonal basis for a given group element  is then the result of applying this same Galois automorphism
is then the result of applying this same Galois automorphism 

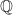 . Conversely, if
. Conversely, if 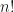 , then
, then 
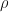 is a representation with that character, then
is a representation with that character, then  is exactly the preimage in
is exactly the preimage in  . In general (even if
. In general (even if ![\sqrt{[G:\mathbf{Z}(\chi)]}](https://s0.wp.com/latex.php?latex=%5Csqrt%7B%5BG%3A%5Cmathbf%7BZ%7D%28%5Cchi%29%5D%7D&bg=ffffff&fg=111111&s=0&c=20201002) .
. (with respect to the norm on characters on
(with respect to the norm on characters on 
 is always nonnegative, we have
is always nonnegative, we have

 , we get
, we get![[G:\mathbf{Z}(\chi)] \geq \chi(1)^2.](https://s0.wp.com/latex.php?latex=%5BG%3A%5Cmathbf%7BZ%7D%28%5Cchi%29%5D+%5Cgeq+%5Cchi%281%29%5E2.&bg=ffffff&fg=111111&s=0&c=20201002)
 is abelian.
is abelian. .
. is not in
is not in  with the commutator
with the commutator ![[g,h] := g^{-1}h^{-1}gh](https://s0.wp.com/latex.php?latex=%5Bg%2Ch%5D+%3A%3D+g%5E%7B-1%7Dh%5E%7B-1%7Dgh&bg=ffffff&fg=111111&s=0&c=20201002) not lying in the kernel of
not lying in the kernel of ![[G,G]](https://s0.wp.com/latex.php?latex=%5BG%2CG%5D&bg=ffffff&fg=111111&s=0&c=20201002) lies inside
lies inside ![[g,h]\in \mathbf{Z}(\chi)](https://s0.wp.com/latex.php?latex=%5Bg%2Ch%5D%5Cin+%5Cmathbf%7BZ%7D%28%5Cchi%29&bg=ffffff&fg=111111&s=0&c=20201002) . So
. So ![\rho([g,h])](https://s0.wp.com/latex.php?latex=%5Crho%28%5Bg%2Ch%5D%29&bg=ffffff&fg=111111&s=0&c=20201002) is a scalar matrix that’s not the identity! Call it
is a scalar matrix that’s not the identity! Call it  , with
, with  an appropriate root of unity different from
an appropriate root of unity different from ![\rho(g[g,h])=\rho(g)\rho([g,h]) = \zeta \rho(g)](https://s0.wp.com/latex.php?latex=%5Crho%28g%5Bg%2Ch%5D%29%3D%5Crho%28g%29%5Crho%28%5Bg%2Ch%5D%29+%3D+%5Czeta+%5Crho%28g%29&bg=ffffff&fg=111111&s=0&c=20201002) , so that
, so that![\chi(g[g,h]) = \zeta \chi(g),](https://s0.wp.com/latex.php?latex=%5Cchi%28g%5Bg%2Ch%5D%29+%3D+%5Czeta+%5Cchi%28g%29%2C&bg=ffffff&fg=111111&s=0&c=20201002)
![g[g,h] = h^{-1}gh](https://s0.wp.com/latex.php?latex=g%5Bg%2Ch%5D+%3D+h%5E%7B-1%7Dgh&bg=ffffff&fg=111111&s=0&c=20201002) is conjugate to
is conjugate to ![\chi(g[g,h]) = \chi(g).](https://s0.wp.com/latex.php?latex=%5Cchi%28g%5Bg%2Ch%5D%29+%3D+%5Cchi%28g%29.&bg=ffffff&fg=111111&s=0&c=20201002)
 , and because
, and because  , this implies
, this implies  . 🌈
. 🌈 for a particular topological space
for a particular topological space 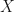 that was carrying an action by a particular finite group
that was carrying an action by a particular finite group  is an affine variety with an action of a finite group
is an affine variety with an action of a finite group  ? Or if
? Or if 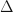 is a balanced
is a balanced ![k[\Delta / G]](https://s0.wp.com/latex.php?latex=k%5B%5CDelta+%2F+G%5D&bg=ffffff&fg=111111&s=0&c=20201002) is isomorphic to
is isomorphic to ![k[\Delta]^G](https://s0.wp.com/latex.php?latex=k%5B%5CDelta%5D%5EG&bg=ffffff&fg=111111&s=0&c=20201002) (see
(see  doesn’t divide the order of
doesn’t divide the order of  inherits a simplicial (or CW complex) structure, then already
inherits a simplicial (or CW complex) structure, then already  at the level of chains. There are analogous results for compact Lie groups if the characteristic of
at the level of chains. There are analogous results for compact Lie groups if the characteristic of  doesn’t divide
doesn’t divide  . (And the corresponding statement for homology. See Theorem 2.4 in Chapter III of that book.)
. (And the corresponding statement for homology. See Theorem 2.4 in Chapter III of that book.) to a basis of
to a basis of  , implying that
, implying that  in all cases. I couldn’t see any reason why the boundary map wouldn’t commute with this isomorphism. Doesn’t that mean that both chain complexes
in all cases. I couldn’t see any reason why the boundary map wouldn’t commute with this isomorphism. Doesn’t that mean that both chain complexes  and
and  . That’s the step that requires the nonmodularity hypothesis.
. That’s the step that requires the nonmodularity hypothesis. (it’s short), and then I’ll show how Cappell’s sketch can be completed to a proof by identifying
(it’s short), and then I’ll show how Cappell’s sketch can be completed to a proof by identifying  from the nonmodularity assumption, and I think that the reasoning behind the necessary group cohomology is basically the same as Bredon’s argument anyway, so the alternative proof is secretly the same proof hiding behind fancier machinery. But still I wanted to record it because it was a new connection for me.
from the nonmodularity assumption, and I think that the reasoning behind the necessary group cohomology is basically the same as Bredon’s argument anyway, so the alternative proof is secretly the same proof hiding behind fancier machinery. But still I wanted to record it because it was a new connection for me. given on simplices
given on simplices 
 described above, where you send a simplex of
described above, where you send a simplex of  will be a nontrivial multiple of the sum across the corresponding orbit in
will be a nontrivial multiple of the sum across the corresponding orbit in  is not an isomorphism unless
is not an isomorphism unless  is prime to
is prime to  . Let me also call this composition
. Let me also call this composition  is called the transfer. The image lands inside
is called the transfer. The image lands inside  induced from the quotient map
induced from the quotient map  . If you restrict
. If you restrict  to
to  and
and  end up being multiplication by
end up being multiplication by  . (Basically you find this out by chasing chains through the definitions of
. (Basically you find this out by chasing chains through the definitions of  and
and  and
and  , where
, where 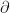 is the boundary operator of the chain complex
is the boundary operator of the chain complex  . (I’m suppressing subscripts because I’m finding them distracting to the main point. I hope it doesn’t bother you and I apologize if it does.) In other words, we’ve got a short exact sequence
. (I’m suppressing subscripts because I’m finding them distracting to the main point. I hope it doesn’t bother you and I apologize if it does.) In other words, we’ve got a short exact sequence
 is left-exact (e.g., Exercise 6.1.1 in
is left-exact (e.g., Exercise 6.1.1 in  . Therefore, there is a long exact sequence
. Therefore, there is a long exact sequence
 ? It consists of those chains that are both
? It consists of those chains that are both  , i.e., it is just the kernel of the boundary map of the complex
, i.e., it is just the kernel of the boundary map of the complex  . This doesn’t require the nonmodularity hypothesis.
. This doesn’t require the nonmodularity hypothesis. ? This consists of chains that are images of
? This consists of chains that are images of  , let
, let 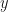 be any
be any 
 is
is 
 , and the fact that
, and the fact that  is exactly the homology of
is exactly the homology of  injects into
injects into  is surjective. From the long exact sequence, this in turn will follow if
is surjective. From the long exact sequence, this in turn will follow if  . Is it?
. Is it? ‘s etc. If
‘s etc. If  vanishes for any
vanishes for any  and any
and any  for any of the
for any of the  ‘s. So, this does it!
‘s. So, this does it! . Indeed, we have the short exact sequence
. Indeed, we have the short exact sequence

 just as it does for
just as it does for  . So the
. So the  , as desired.
, as desired. vanishes when (multiplication by)
vanishes when (multiplication by)  preserves surjectivity, and thus is an exact functor, on
preserves surjectivity, and thus is an exact functor, on ![\mathbb{Z}[|G|^{-1}]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BZ%7D%5B%7CG%7C%5E%7B-1%7D%5D&bg=ffffff&fg=111111&s=0&c=20201002) -modules.]
-modules.] always injects into
always injects into  always injects into
always injects into  always has a map to
always has a map to  (
( , then the Sylow
, then the Sylow  -points of the Borel subgroup form the Sylow normalizer.
-points of the Borel subgroup form the Sylow normalizer. as an algebraic variety. The subgroup
as an algebraic variety. The subgroup  are closed subgroups of
are closed subgroups of  (that commutes with the action of
(that commutes with the action of 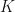 ; i.e., the family of parabolic subgroups of
; i.e., the family of parabolic subgroups of 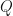 and a
and a  ,
,  has a subgroup of order
has a subgroup of order  (this is the Sylow subgroup). Evidently such a subgroup is both maximal among
(this is the Sylow subgroup). Evidently such a subgroup is both maximal among 
 ,
, 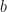 ,
, 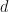 , and
, and  , are isomorphisms, then
, are isomorphisms, then  is an isomorphism.
is an isomorphism. as having elements and just applied the axioms of an abelian category; I seem to have abandoned the effort after it started to seem like too much work to be worth standing on ceremony. (In view of
as having elements and just applied the axioms of an abelian category; I seem to have abandoned the effort after it started to seem like too much work to be worth standing on ceremony. (In view of  are isomorphisms. If you identify the pairs
are isomorphisms. If you identify the pairs  etc. along these isomorphisms, the diagram becomes
etc. along these isomorphisms, the diagram becomes
 and
and  must have the same kernel (namely, the image of
must have the same kernel (namely, the image of  ). This means that the image of
). This means that the image of 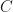 and
and  is the same. Similarly, exactness at
is the same. Similarly, exactness at 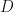 is the statement that
is the statement that  and
and  have the same image (the kernel of
have the same image (the kernel of  ). We may as well replace
). We may as well replace 
 , we can conclude that
, we can conclude that  by
by  . The Steenrod 5-lemma thus comes down to the assertion that if you have groups
. The Steenrod 5-lemma thus comes down to the assertion that if you have groups  acting as the identity on
acting as the identity on  and
and  , then
, then  is surjective. It’s injective because (1) injectivity of
is surjective. It’s injective because (1) injectivity of  in
in  . I’m using boldface to distinguish these kernels and quotients from other kernels and quotients that come up in what follows; the last two sentences should be taken as definitions-of-boldface-kernels-and-quotients. The question is, “what assumptions on
. I’m using boldface to distinguish these kernels and quotients from other kernels and quotients that come up in what follows; the last two sentences should be taken as definitions-of-boldface-kernels-and-quotients. The question is, “what assumptions on 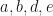 allow us to conclude that the maps on kernels and quotients are surjective (resp. injective)?
allow us to conclude that the maps on kernels and quotients are surjective (resp. injective)? . The fact that the kernels are quotients of
. The fact that the kernels are quotients of  . (General principle: surjectivity of a map does not imply surjectivity of an induced map on subgroups.) But surjectivity of
. (General principle: surjectivity of a map does not imply surjectivity of an induced map on subgroups.) But surjectivity of  and pull it back to
and pull it back to  ? Yes, because it must map to zero after pushing forward to
? Yes, because it must map to zero after pushing forward to 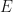 and then down along
and then down along  came from
came from  two different ways. Indexing over
two different ways. Indexing over 
 is the set of fixed points of
is the set of fixed points of 
 is the set of orbits, and the
is the set of orbits, and the 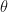 . Equating the two counts and dividing by
. Equating the two counts and dividing by 
 is equal to the number of orbits
is equal to the number of orbits  .
.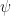 ) in
) in  . Meanwhile,
. Meanwhile,  is exactly
is exactly  since
since 

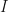 is an ideal in a commutative ring, and
is an ideal in a commutative ring, and  and
and  are both finitely generated, then
are both finitely generated, then  , and write each one as the sum of an element of
, and write each one as the sum of an element of  ,
, and each
and each  just some ring element. Also choose a finite set of generators
just some ring element. Also choose a finite set of generators  for
for  lie in
lie in  be arbitrary. Then there is a representation
be arbitrary. Then there is a representation 
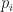 are some ring elements. The key observation is that
are some ring elements. The key observation is that 
 is in
is in  ,
, are some ring elements. Then we have
are some ring elements. Then we have ,
, . This completes the proof.
. This completes the proof. be the family of non-f.g. primes, which is nonempty by assumption. Note that given an ascending chain in
be the family of non-f.g. primes, which is nonempty by assumption. Note that given an ascending chain in  , but
, but  . By the former supposition,
. By the former supposition,  . By the latter supposition,
. By the latter supposition,  . But recalling that
. But recalling that  , we can now conclude that
, we can now conclude that  ! This proves that
! This proves that ![R = k[x,y]_{(x,y)}](https://s0.wp.com/latex.php?latex=R+%3D+k%5Bx%2Cy%5D_%7B%28x%2Cy%29%7D&bg=ffffff&fg=111111&s=0&c=20201002) . Let
. Let ![S = R[y/x,y/x^2,\dots]](https://s0.wp.com/latex.php?latex=S++%3D+R%5By%2Fx%2Cy%2Fx%5E2%2C%5Cdots%5D&bg=ffffff&fg=111111&s=0&c=20201002) . Note that
. Note that  , because every
, because every  is a multiple of
is a multiple of 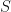 . It follows that
. It follows that  , so that
, so that  is a maximal ideal in
is a maximal ideal in  .
.  , for all
, for all  , since
, since  , but in a noetherian local ring, the intersection of the powers of the maximal ideal is zero, by the
, but in a noetherian local ring, the intersection of the powers of the maximal ideal is zero, by the ![f=x^p-a\in k[x]](https://s0.wp.com/latex.php?latex=f%3Dx%5Ep-a%5Cin+k%5Bx%5D&bg=ffffff&fg=111111&s=0&c=20201002) , where
, where 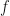 is irreducible over
is irreducible over 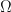 be an algebraic closure of
be an algebraic closure of  .
. , where
, where  is a
is a 
![g,h\in k[x]](https://s0.wp.com/latex.php?latex=g%2Ch%5Cin+k%5Bx%5D&bg=ffffff&fg=111111&s=0&c=20201002) . Then, normalizing
. Then, normalizing 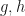 to be monic, we have
to be monic, we have ,
,  ,
,  and
and  . This implies
. This implies  since
since  are
are  . Since
. Since 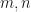 are relatively prime, there exist integers
are relatively prime, there exist integers  for which
for which  , and then we can conclude
, and then we can conclude  . Thus
. Thus  .
. is relatively prime with
is relatively prime with  be a splitting field for
be a splitting field for  be a primitive
be a primitive  is also a root of
is also a root of  , and is thus in
, and is thus in  ; thus
; thus  . As all roots of
. As all roots of  .
. is a Galois extension. Let
is a Galois extension. Let  , and let
, and let  . If
. If  be a nontrivial element. We have
be a nontrivial element. We have  for some
for some  , as
, as  , we have
, we have
 traverses all residue classes mod
traverses all residue classes mod  moves to every root of
moves to every root of  acts transitively on the roots of
acts transitively on the roots of  . It follows that
. It follows that  . An element
. An element 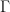 is therefore determined by its action on
is therefore determined by its action on  ,
,  realizes
realizes  . Since the latter group is cyclic (as it is a finite subgroup of the multiplicative group of a field), it follows that
. Since the latter group is cyclic (as it is a finite subgroup of the multiplicative group of a field), it follows that 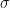 be a generator.
be a generator. for some
for some  , and
, and  for some
for some  . We will show that
. We will show that 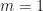 , then
, then  on
on  , and
, and  , then the equation
, then the equation  , regarded as occurring in
, regarded as occurring in 
 . Since this is the entire Galois group of
. Since this is the entire Galois group of  . Thus
. Thus  , where
, where  . But this means if there is a proper factorization into factors of degree
. But this means if there is a proper factorization into factors of degree  ,
,  , for some integers
, for some integers  . As above, in Case 1, because
. As above, in Case 1, because 
 . The thing on the right is both in
. The thing on the right is both in 