Juncheng Hu1,2,3 · Jiawei Du2,3 · Xin Zhang2,3 · Joey Tianyi Zhou2,3
1NUS 2CFAR, A*STAR 3IHPC, A*STAR
Draw2Think is a training-free constraint-agentic harness for geometry reasoning: a frozen VLM dispatches typed ToolSpecs to an executable constraint engine. This repo contains the harness, ToolSpecs, eval scripts, ablations, and reproduction entry points.
A frozen VLM proposes typed actions; the engine updates a shared canvas and returns structured observations. As an agent-systems stack, the harness has seven layers. ▶ See it live.
| Constraint-agentic harness (Draw2Think, ours) |
Harness Layer | What it governs → code |
|---|---|---|
 | L1 Context | sees only verified state problem + ToolSpecs + history → prompts/ |
| L2 Tools | typed ToolSpec interface schemas / preconditions → tools/ | |
| L3 Orchestration | model routes tool use turn-level routing → test_agentic… | |
| L4 Memory | canvas state + trace objects / DAG / styling → CanvasTracker | |
| L5 Verification | fidelity + faithfulness construction checks → geogoal/ | |
| L6 Recovery | reject → rollback → recover repair / escape → execute() | |
| L7 Supervision | external engine sandbox audit boundary → geogebra_api.py |
| Path | What | Details |
|---|---|---|
symbolic/ |
core library: engine bridge, typed ToolSpecs, model registry | symbolic/README |
eval/ |
harness eval: PDV constructor, baselines, benchmark evals, ablations | eval/README |
tests/ |
ToolSpec, engine bridge, and pipeline smoke tests | tests/README |
Requires Python >= 3.10 and >=4 GB RAM. bootstrap prepares the .env template, Chrome for Testing, ChromeDriver, then runs a Selenium smoke test. We recommend --offline-bundle for stable reproduction. An agentic coding framework can inspect the repo and help run the bootstrap/doctor steps.
git clone https://github.com/draw2think/harness-geometry.git
cd harness-geometry
conda create -n symbolic python=3.10 -y && conda activate symbolic
pip install -e .python setup.py bootstrap --offline-bundle # (recommended) local bundle [~110MB]
python setup.py bootstrap # online CDN-backed runtime
python setup.py download_manual # (opt) official reference docsIf your cluster blocks browser downloads, install Chrome/Chromium manually or set DRAW2THINK_CHROME and DRAW2THINK_CHROMEDRIVER:
# Ubuntu/Debian
sudo apt-get update && sudo apt-get install -y chromium
# Cluster / no sudo
conda install -c conda-forge chromium -ypython setup.py bootstrap writes a blank .env template to the project root and leaves an existing .env untouched. Fill in only the providers you run; the default Gemini constructor needs GOOGLE_API_KEY, judge-based evals (GenExam) additionally need an OpenAI-compatible key. Use python setup.py create_env to regenerate the template separately.
Official key consoles: Google AI Studio, OpenAI, Anthropic.
Additional included in registry: Moonshot Intl / CN, Z.ai / BigModel CN, DeepSeek, Alibaba Intl / Bailian CN.
Practical observation for stable reproducibility. Use native provider keys for reported results. Low-price third-party proxies may lack quality guarantees and can introduce provider-side numerical or routing perturbations even under the same model name, temperature-0 setting, and seed. Avoid unauthorized resellers for reproducibility and key-safety reasons.
python eval/download_datasets.py # list datasets and local status
python eval/download_datasets.py --download <dataset-id>
python eval/download_datasets.py --download allList available models:
python -m symbolic.utils.model_registry --vision --tool-calling --thinkingAgentic construction (CT): the PDV constructor:
python eval/test_agentic_geo_constructer.py \
--dataset pgps9k --data_dir /data/PGPS9K \
--mode construct --sample 50 --workers 4Baseline (BL): single-turn, no tools; the direct-VLM comparison reported in the paper:
python eval/eval_baseline.py --dataset pgps9k --data_dir /data/PGPS9K --sample 50Key flags (constructor): --mode construct|direct, --model <registry-id>, --sample N (--sample 0 for full set; default is 10), --workers N, --skip-done (resume), --thinking minimal|low|medium|high, --id <problem-id> (explicit IDs skip sampling).
| Paper claim | Command |
|---|---|
| Outcome accuracy, CT (main table) | python eval/test_agentic_geo_constructer.py --mode construct ... |
| Outcome accuracy, BL (no-tool baseline) | python eval/eval_baseline.py ... |
| GeoGoal construction fidelity (SR/SC) | python eval/geogoal/eval_geogoal.py --data /data/geogoal_sgvr |
| GeoGoal fidelity-conditioned answer quality | python Writing/figs/geogoal_sgvr/fidelity_bars.py |
GeoGoal T_i tolerance sweep |
python Writing/figs/geogoal_sgvr/tol_sweep.py |
| GenExam-math 68.2% / 90.5% rendering | python eval/eval_genexam.py --generate-only → --judge-only → --score-only |
| Query / Delete / Description ablations (§5) | python eval/ablation_wo_query.py, python eval/ablation_wo_delete.py, python eval/ablation_description_run.py |
| Answer-source taxonomy | python eval/analyze_answer_source.py |
| Re-score saved runs without re-querying the model | python eval/rescore_from_logs.py |
Paper-specific entry points:
GeoGoal
python eval/geogoal/eval_geogoal.py --data /data/geogoal_sgvr --sample 10
python Writing/figs/geogoal_sgvr/fidelity_bars.py
python Writing/figs/geogoal_sgvr/tol_sweep.pyGenExam
python eval/eval_genexam.py --data_dir /data/genexam --sample 10 --generate-only
python eval/eval_genexam.py --judge-only
python eval/eval_genexam.py --score-onlyAblations
python eval/ablation_wo_query.py --ablation-mode wo_query_17 --bench mathverse --skip-done
python eval/ablation_wo_delete.py --bench mathverse
python eval/ablation_description_run.py --level bare --bench mathverse --workers 4Default run parameters (model, max turns = 30, temperature = 0, thinking level) live in eval/eval_config.py; CLI flags override them. Per-benchmark recipes and the full result schema are in eval/README.
Click any preview to open the GUI walkthrough with model traces, engine outputs, and live canvas states.
 |
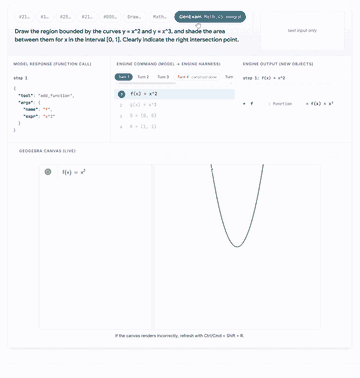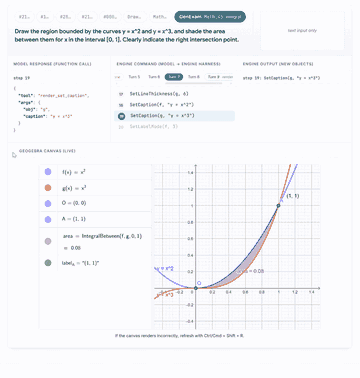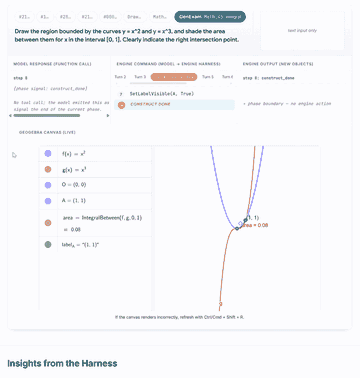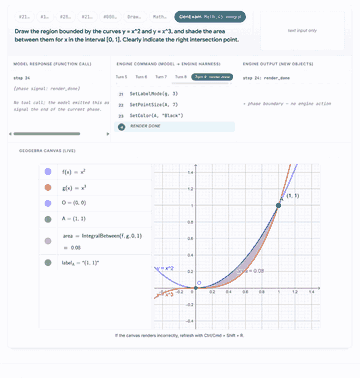 |
 |
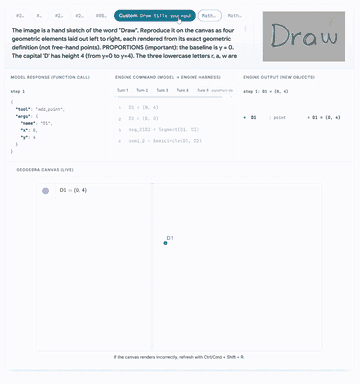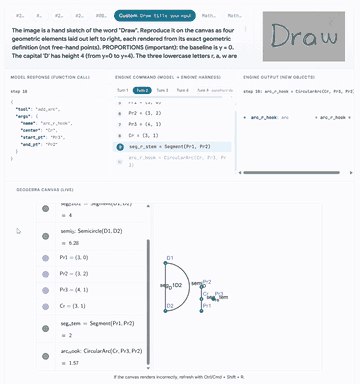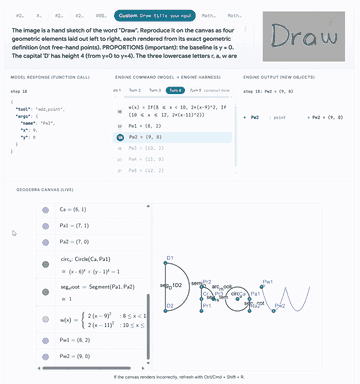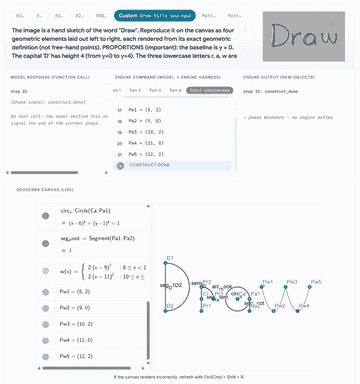 |
@article{hu2026draw2think,
title = {Draw2Think: Harnessing Geometry Reasoning through Constraint Engine Interaction},
author = {Hu, Juncheng and Du, Jiawei and Zhang, Xin and Zhou, Joey Tianyi},
journal = {arXiv preprint arXiv:2605.20743},
year = {2026},
url = {https://draw2think.github.io}
}Released under the MIT License.
Draw2Think uses GeoGebra and Giac CAS backends, fetched on demand under their own licenses. See NOTICE.