작년 화제가 된 구글의 양자우월성 증명은 양자랜덤회로를 만들고, 그 결과를 측정(measure)하여 얼마나 올바른 분포를 만들었는지를 관측하는 XEB Fidelity benchmark를 사용했다. 지난번 관련된 글을 두개 써서 현황을 설명하기도 했다.
그런데 실제로 우리가 쓸 것으로 예상되는 회로들은 Grover의 알고리즘이나 HHL의 선형방정식 알고리즘, 양자 머신러닝, Shor의 알고리즘등 같은 연산을 반복하거나 (Grover, HHL) 비슷한 연산을 반복하는 양자 Fourier 변환등을 이용하게 된다. 즉, 우리가 실제로 쓸 연산은 랜덤회로와 달리 굉장히 구조적이라는 것.
그렇다면 과연 구글의 양자랜덤회로 샘플링을 통한 평가가 우리가 실제로 쓸 것으로 예상되는 “구조적”인 알고리즘을 평가하는데에 얼마나 도움이 될까? 가장 이상적으로는 랜덤회로나 구조적인 회로나 비슷한 수준의 에러를 갖거나, 구조적인 회로가 더 적은(!)에러를 갖는 경우일 것이다.
하지만 안타깝게도, 어제 아카이브에 올라온 논문에 따르면 실제로는 그 반대인듯 하다고 한다. 즉,
현재 기술로는 양자랜덤회로 샘플링이 구조적 알고리즘보다 쉽다
라는 것. 그러니까, 양자랜덤회로의 에러가 구조적 알고리즘의 에러보다 더 작다는 말.
다만 이 실험은 구글의 Sycamore가 아닌, 실험하기 더 쉬운 IBM Q와 Rigetti의 양자컴퓨터를 이용해서 진행했다고 하니 Sycamore의 경우는 어떤지 아직 알수는 없다. 그 실험적 결과는 아래와 같다.

위 그림을 살펴보면 꽤나 부정적인 결과를 여럿 얻을 수 있다.
- 전체적으로 회로의 정확성이 예측보다 훨씬 못한 편이다.
- 대체적으로 구조적 회로가 랜덤회로보다 훨씬 부정확하다. (가끔 그렇지 않은 경우도 있긴 하다)
- 7큐비트정도부터는 depth를 조금만 늘려도 전부 다 제 멋대로 나오는듯 하다.
- IBM Q Melbourne은…. 뭔가 문제가 있어 보인다.
근데, 지난 글에서 구글의 실험 자체가 옳은지를 검증하는게 어렵다는 말을 한적이 있다. 이 논문에서 어떻게 구조적 회로와 랜덤회로의 정확성/에러를 확인한걸까? 마지막으로 논문에서 이 부분을 어떻게 해결했는지 살펴보자.
저자들이 사용한 방식은 거울회로, 혹은 실험에 사용한 회로 C의 역인 C-1, 혹은 그의 변형을 생각하는 것이다. 논문에서는 다음과 같이 그림으로도 설명해준다.

대충 원래 적용한 회로의 역, 혹은 그거를 약간 변형한 방식을 한번 더 적용함으로써 답이 고전상태로 정해지는 독특한 회로를 만든것.
이 회로의 결과는 고전컴퓨터로 계산/검증이 쉽지만 에러가 있는 양자컴퓨터로는 계산하기 어렵다. 어찌보면 양자우월성에서 필요했던 회로의 듀얼 버젼인데, 이걸 이렇게 간단히 만들 수 있다는 사실이 신기하군ㅋ

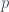 는 테스트하고자하는 확률 분포,
는 테스트하고자하는 확률 분포,  는 C의 결과로 나오는 확률 분포. 이 XEB값은
는 C의 결과로 나오는 확률 분포. 이 XEB값은  가 되면 (C의 structure때문에) 1이 된다고 한다.
가 되면 (C의 structure때문에) 1이 된다고 한다.
 개 정도 있으면 실제로 XEB Fidelity를 2에 가까운 정도로 크게 만들수 있다고.
개 정도 있으면 실제로 XEB Fidelity를 2에 가까운 정도로 크게 만들수 있다고.
 위에서의
위에서의  에서의 문제였고,
에서의 문제였고, ![\exp\left(\sqrt[3]{\frac{64}{9}} (\log N)^{1/3}(\log \log N)^{2/3} (1+o(1))\right)](https://s0.wp.com/latex.php?latex=%5Cexp%5Cleft%28%5Csqrt%5B3%5D%7B%5Cfrac%7B64%7D%7B9%7D%7D+%28%5Clog+N%29%5E%7B1%2F3%7D%28%5Clog+%5Clog+N%29%5E%7B2%2F3%7D+%281%2Bo%281%29%29%5Cright%29&bg=ffffff&fg=333A42&s=0&c=20201002)

 ))정도를 달성하는데에 그친다.
))정도를 달성하는데에 그친다.  가 성립할것이라고 말하는 Strong exponential time hypothesis (SETH)도 있다.
가 성립할것이라고 말하는 Strong exponential time hypothesis (SETH)도 있다.  -approximation 선형 알고리즘이 최적이고, 심지어
-approximation 선형 알고리즘이 최적이고, 심지어  -approximation 근사는 O*(n2-2t)에 되었다고 한다.
-approximation 근사는 O*(n2-2t)에 되었다고 한다.