こんにちは、タイミーでエンジニアをしている徳富(@yannKazu1)です。
前回の記事では、EKS 上に self-hosted GitHub Actions Runner 基盤を構築した話をご紹介しました。
▼ 前回の記事
https://tech.timee.co.jp/entry/2025/09/22/122415
ありがたいことに、この取り組みは AWS さんの公式ブログでもご紹介いただきました。
👉 AWS ブログ
https://aws.amazon.com/jp/blogs/news/timee-amazon-eks-auto-mode/
今回はその続編として、
EKS のクラスターバージョンアップを、どうやって安全に自動化したか
についてお話しします。
EKS のクラスターバージョンアップ、地味につらい
EKS を運用していると、どうしても避けて通れないのが定期的なクラスターバージョンアップです。
- Kubernetes のマイナーバージョンは定期的に EOL が来る
- 放置するとサポート切れになる
- とはいえ、毎回人が確認して手動で上げるのは正直しんどい
「これ、もう少し楽にできないか?」
そう思ったのが、今回の仕組みを考え始めたきっかけでした。
今回の前提:EKS Auto Mode を使っている
今回運用している EKS では、EKS Auto Mode を採用しています。
EKS Auto Mode では、
- ノード管理
- 主要な Add-on 管理(VPC CNI / AWS Load Balancer Controller など)
を AWS 側で管理しており、運用負荷を軽減できます。
そのため、クラスターバージョンアップの流れは比較的シンプルです。
- マニフェストで 非推奨 API を使っていないか確認する
- 問題なければ クラスターバージョンをアップする
- ノードや主要 Add-on は AWS が自動で追従する
さらに EKS にはUpgrade Insightsという便利な仕組みがあります。
- 非推奨 API の使用状況
- バージョンアップ時に問題になりそうな点
を事前にチェックできるため、
「このバージョンに上げて大丈夫か?」をかなり楽に判断できます。
自動化の方針
とはいえ、いきなり本番クラスターバージョンを自動で上げるのは、さすがに怖い。
そこで、次の方針で仕組みを作りました。
1. 本番とは別にテスト用クラスターを用意する
Self-hosted Runner 用の main クラスターとは別に、検証専用の test クラスターを用意しています。
- コストを抑えるため Spot インスタンスを使用する
- 最小構成で test-runner のみを起動する
インフラは次のように管理しています。
- クラスターや AWS リソース:Terraform
- ARC Controller などの Helm リソース:Terraform
- その他の Kubernetes リソース:マニフェスト(Kustomize)
この構成にしていることで、
- test / main クラスターに ほぼ同じ設定をそのまま適用できる
- runner の 台数やサイズだけを環境ごとに切り替えられる
といったことが簡単にできます。
結果として、
- コントローラや設定は本番と同一
- リソース(インスタンスサイズ・台数)を最小構成にした test-runner
という、「本番に限りなく近いが、低コストなコピー環境」を作れています。
2. テストクラスターで先にバージョンアップする
テストクラスターでは、次の条件を満たした場合のみ
自動でバージョンアップを行います。
① リリースから 1 か月以上経過したバージョンであること
aws eks describe-cluster-versions \
--include-all \
--query 'clusterVersions[?versionStatus==`STANDARD_SUPPORT`].{version: clusterVersion, releaseDate: releaseDate}' \
--output json
取得した結果を jq で加工し、
「リリースから 1 か月以上経過しているバージョン」のみを対象にします。
② Upgrade Insights がすべて PASS していること
INSIGHTS_JSON=$(aws eks list-insights \
--cluster-name ${{ inputs.cluster-name }} \
--output json)
ERROR_COUNT=$(echo "$INSIGHTS_JSON" | jq '[.insights[] | select(.category=="UPGRADE_READINESS" and .insightStatus.status=="ERROR")] | length')
WARNING_COUNT=$(echo "$INSIGHTS_JSON" | jq '[.insights[] | select(.category=="UPGRADE_READINESS" and .insightStatus.status=="WARNING")] | length')
ERROR/WARNINGがあればブロックするUNKNOWNは未使用機能なので許容する
これらの条件をすべて満たしている場合のみ、毎朝 7 時に GitHub Actions から aws eks update-cluster-version を実行します。
3. test クラスターの結果を cluster_version.txt の PR として残す
本番クラスターのバージョンアップは、cluster_version.txt に書かれたバージョンへ更新する
という前提で設計しています。
そのため、本番をいつ上げるかだけは人が判断できるように
cluster_version.txt の更新は必ず PR 経由にしています。
test クラスターバージョンアップが正常に完了すると、
- 実際に上がった EKS バージョンを
- そのまま
cluster_version.txtに書き込み - 自動で PR を作成
します。
# **cluster_version.txt** 1.34
この PR をマージすると、その日の深夜に本番クラスターバージョンアップが実行されます。
- 検証は自動で完了済み
- 本番反映の日付だけ人が判断する
というバランスに落ち着きました。
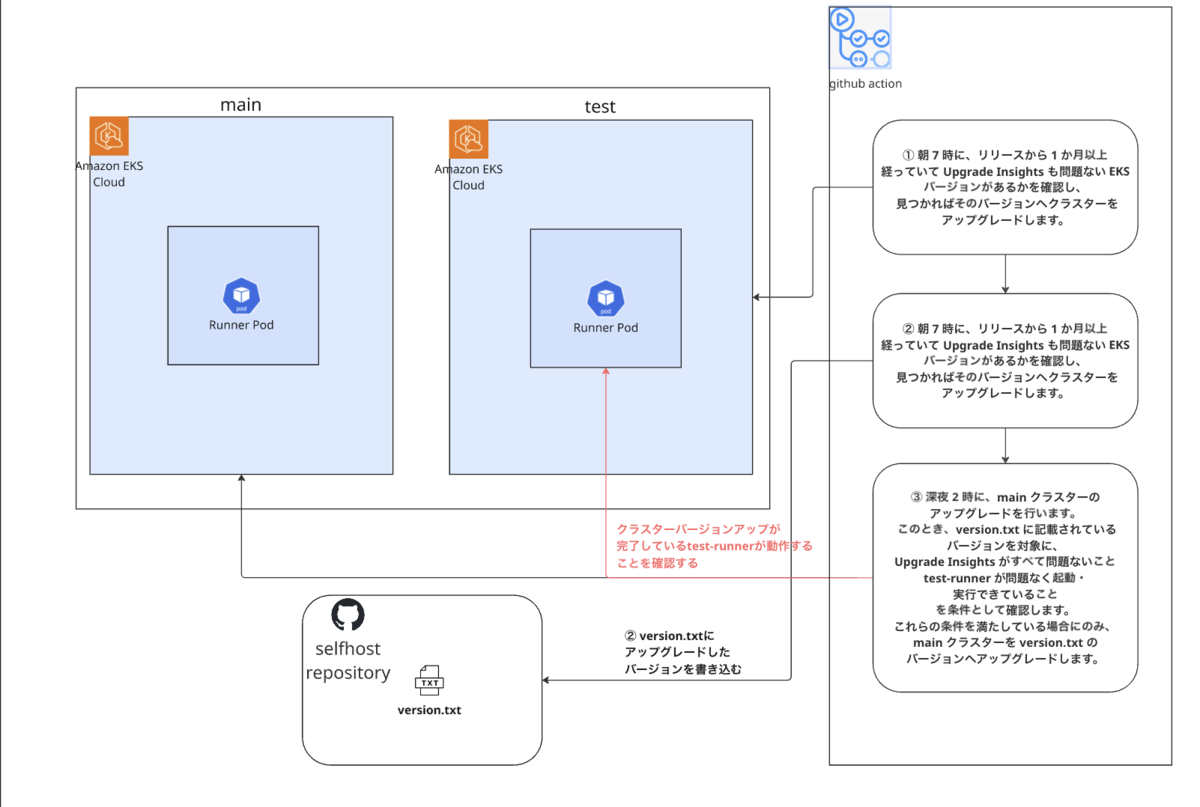
本番クラスターバージョンアップフロー
本番クラスターバージョンアップは、毎日 深夜 2 時に
GitHub Actions から定期実行しています。
流れは次のとおりです。
1. cluster_version.txt との差分を確認
cluster_version.txtのバージョン- 現在の本番クラスターのバージョン
を比較し、差分がなければここで終了します。
差分がある場合のみ、以降のチェックに進みます。
2. Upgrade Insights が PASS していることを確認
INSIGHTS_JSON=$(aws eks list-insights \
--cluster-name ${{ inputs.cluster-name }} \
--output json)
ERROR_COUNT=$(echo "$INSIGHTS_JSON" | jq '[.insights[] | select(.category=="UPGRADE_READINESS" and .insightStatus.status=="ERROR")] | length')
WARNING_COUNT=$(echo "$INSIGHTS_JSON" | jq '[.insights[] | select(.category=="UPGRADE_READINESS" and .insightStatus.status=="WARNING")] | length')
3. test-runner のヘルスチェックを実行
本番アップグレード前に、
test クラスター上の Self-hosted Runner が正常に動くかを確認します。
簡単な workflow_dispatch のワークフローを用意しています。
name: Test Runner Health Check
on:
workflow_dispatch
jobs:
health-check:
runs-on: test-runner # testクラスター上のtest-runnerを指定する
timeout-minutes: 10
steps:
- run: |
echo "✅ test-runner is healthy!"
hostname
date
このワークフローをgh コマンドで起動し、
10 分以内に success することを確認します。
(ポーリング処理は省略していますが、実装上は完了を待っています)
4. 問題なければ本番クラスターバージョンアップ
aws eks update-cluster-version \
--name ${{ env.MAIN_CLUSTER_NAME }} \
--kubernetes-version "$TARGET_VERSION"
流れを図で表すと、以下のとおりです。
なぜ深夜 2 時に「自動で」上げるのか?
「本番反映の日付は人が制御」と書きましたが、厳密には PR をマージした日の深夜 2 時に自動でクラスターバージョンアップが走る 仕組みです。
つまり、人が決めるのは 「いつの深夜にクラスターバージョンアップを実行するか」 だけ。
この設計にしている理由は 2 つあります。
1. 深夜ならデプロイと競合しない
- デプロイが走っていない時間帯である
- ノード更新時に Pod が退避しても影響が出にくい
- デプロイ途中で Pod が落ちる事故を防げる
2. 問題が起きても業務開始後に対処できる
Self-hosted Runner の利用箇所では、Organization variablesを使って runner を指定しています。
runs-on: ${{ vars.RUNNER_AMD64_STANDARD }}
もしクラスターバージョンアップ後に問題が発覚しても、この変数の値を ubuntu-latest などに変更するだけで、全リポジトリのワークフローが GitHub-hosted runner で動くようになります。
コードを一切変更せずにフォールバックできるため、業務開始後に気づいてからの対応でも十分間に合います。
このフォールバック手段があるからこそ、
- 深夜に自動でクラスターバージョンアップを実行
- 人は「日付を決める」だけ
という運用が成り立っています。
Terraform 管理との付き合い方
インフラは Terraform で管理していますが、
EKS のクラスターバージョンだけは Terraform 管理外にしています。
cluster_versionにignore_changesを設定している- バージョンアップは CLI で実施している
これにより、
- CLI で上げても Terraform 差分が出ない
- IaC と運用の責務をきれいに分離できる
というメリットがあります。
まとめ
この仕組みを導入したことで、
- クラスターバージョンアップの toil を大幅に削減できた
- 「test → 本番」の安心できるフローを自動化できた
- Self-hosted Runner が壊れないことを事前に保証できるようになった
という成果が得られました。
EKS Auto Mode の特性を活かすことで、
「人が気合で回す運用」から一段階進められたかなと思っています。
同じように EKS を運用している方の参考になれば嬉しいです 🙌