Pinned
Applied Compute
182 posts


Applied Compute
@appliedcompute
The Best AI is Built Not Bought
 We partnered with @harvey to post-train the state-of-the-art legal agent on their LAB benchmark. It surpasses Opus 4.8 Max and GPT-5.5 xhigh.
We partnered with @harvey to post-train the state-of-the-art legal agent on their LAB benchmark. It surpasses Opus 4.8 Max and GPT-5.5 xhigh. 00:00Replying to @appliedcomputeWe rebuilt the agent harness to operate well in challenging long context environments. Legal source documents are huge, with the 90th-percentile LAB task carrying nearly 100k tokens and some exceeding 200k. We added compaction so the model summarizes its own transcript and
00:00Replying to @appliedcomputeWe rebuilt the agent harness to operate well in challenging long context environments. Legal source documents are huge, with the 90th-percentile LAB task carrying nearly 100k tokens and some exceeding 200k. We added compaction so the model summarizes its own transcript and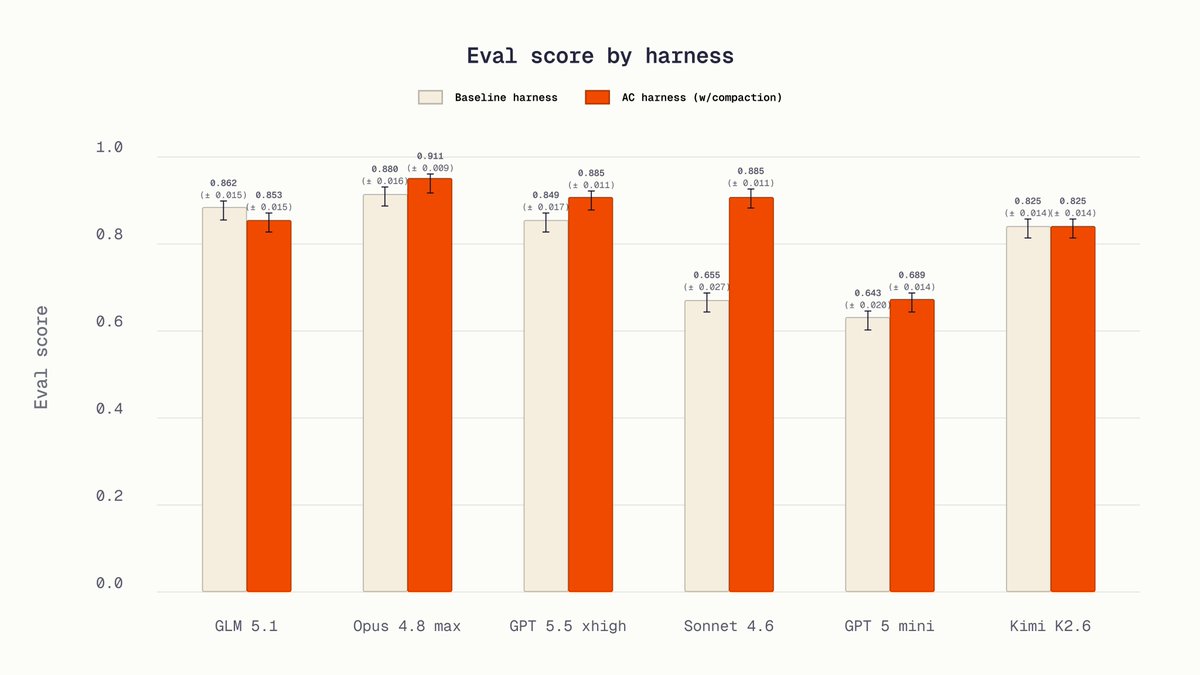
- Applied Compute reposted
 Model strategy for @harvey: We are working on the first model in our legal foundation model series, inspired by @cursor_ai's Composer. Two goals: 1. Allow us to serve frontier intelligence across our product surface areas at an affordable price and a strong security posture.
Model strategy for @harvey: We are working on the first model in our legal foundation model series, inspired by @cursor_ai's Composer. Two goals: 1. Allow us to serve frontier intelligence across our product surface areas at an affordable price and a strong security posture. - Preserving entropy is critical for continued training; in modern post-training recipes, entropy is often a fixed resource that gets exhausted over the course of a training run, making it difficult for the model to improve and learn on new tasks. Adaptive entropy control methods
 Replying to @appliedcomputeThe collapse also shows up in the answers themselves. Under various metrics of intra-prompt diversity, a policy trained with GRPO leads to less diverse responses than a trained with adaptive entropy control. Moreover, we observe that entropy allows response diversity to be tuned,
Replying to @appliedcomputeThe collapse also shows up in the answers themselves. Under various metrics of intra-prompt diversity, a policy trained with GRPO leads to less diverse responses than a trained with adaptive entropy control. Moreover, we observe that entropy allows response diversity to be tuned, Read the full research report:
Read the full research report: - The workflows that make you different shouldn't run on the same general models everyone else rents. Our co-founder @rhythmrg on when to train your own.
- Applied Compute reposted
 When we started Applied Compute this was our thesis in a nutshell. "Companies need to turn their workflows, domain knowledge, and accumulated judgment into AI systems that improve with each use. Private evals should capture whether a model is actually improving against outcomes
When we started Applied Compute this was our thesis in a nutshell. "Companies need to turn their workflows, domain knowledge, and accumulated judgment into AI systems that improve with each use. Private evals should capture whether a model is actually improving against outcomes - "A great eval needs to understand every correct answer, and every way one can go catastrophically wrong." @BrendanFoody from @mercor_ai shared with our CEO @ypatil125 how evals are deceptively the hardest part of post-training. Our team at Applied Compute solves this by
 00:00
00:00 - “RL is remarkably data efficient. You can specialize a model on exactly what your business needs, with surprisingly little data.” @BrendanFoody sat with our CEO @ypatil125 to discuss how RL flipped the equation from quantity to quality, so the proprietary data only you have can
 00:00
00:00 - After working with both frontier labs and enterprises across industries, @mercor_ai CEO @BrendanFoody joined our CEO @ypatil125 to discuss why proprietary data and custom models are what keep a company competitive at the frontier.
 00:00
00:00 - @nvidia’s Nemotron 3 Ultra handles software-engineering tasks at a fraction of the per-task cost of frontier models. So we trained a router to send each coding task to the cheapest model that can successfully solve it, cutting inference cost while holding frontier-level quality.

 Replying to @appliedcomputeThe models are complementary. The trained router sends 73% of tasks to @NVIDIAAI's efficient Nemotron 3 Ultra and routes the long tail to GPT 5.5 and Opus 4.7 on tasks where frontier performance at a premium is worth the tradeoff. Since the router is agentic, it can call tools
Replying to @appliedcomputeThe models are complementary. The trained router sends 73% of tasks to @NVIDIAAI's efficient Nemotron 3 Ultra and routes the long tail to GPT 5.5 and Opus 4.7 on tasks where frontier performance at a premium is worth the tradeoff. Since the router is agentic, it can call tools







