-
-
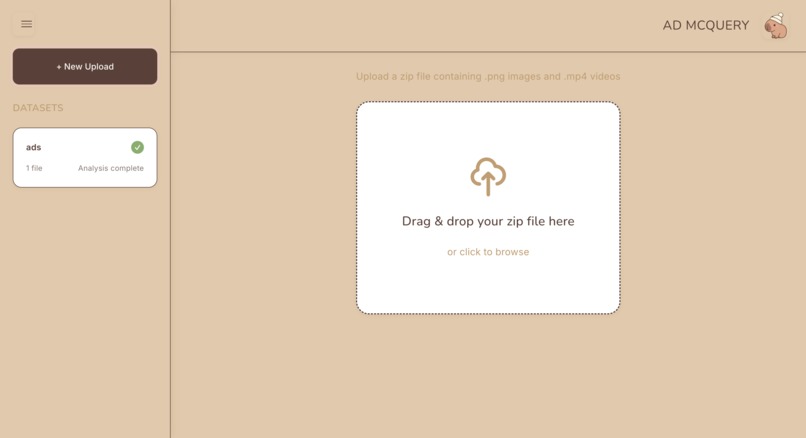
Landing page with zip file upload
-
Data processing loading screen
-
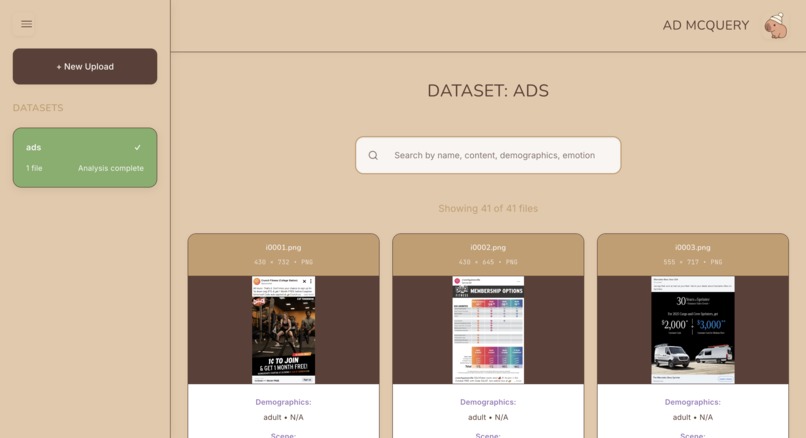
Ads dashboard after processing



Inspiration
When ads are first shipped to platforms like Axon, they’re vectorized and dropped near the median of the existing ad space. The system then uses user interactions over ~2 weeks to nudge the ad toward its true audience—but performance is weak during this learning period. We propose preprocessing key metrics so the ad starts in a more accurate demographic cluster, improving early-stage performance.
What it does
Upon ZIP ingestion, files enter a batch pipeline for metadata extraction and OCR. The raw media and derived text are then passed to Gemini, which generates metric scores—including but not limited to: age demographic, purchase urgency, luxury index, and product visibility. Individual images and videos can be batch processed in parallel for maximum scalability.
How we built it
Media assets were processed with Pillow (PIL) and PyTesseract for metadata and OCR. The resulting text, along with the original media, was submitted to Gemini using the Google Python SDK to generate targeted metrics defined by our prompts.
Challenges we ran into
We needed to determine which metrics were truly informative. Then, since our pipeline relies on AI for scoring, we validated that the model consistently produced reliable, human-comparable numeric scores for those metrics.
Accomplishments that we're proud of
Our ad-processing runs produced consistent metric scores. We also ran blind human ratings for each metric and compared results: over 90% of AI scores aligned with human judgments.
What we learned
Gemini provides robust demographic signals (age-range, geo intent), but fine-grained scalar scores show variance across runs. We mitigate this by ordinalizing most metrics into three categories—low, medium, high—for greater consistency and decision stability.
What's next for Ad McQuery
We hope to refine our model's metric analysis and improve our pipeline to achieve production level scale.
Built With
- computer-vision
- fastapi
- gemini
- pillow
- python
- react
- typescript




Log in or sign up for Devpost to join the conversation.