-
-
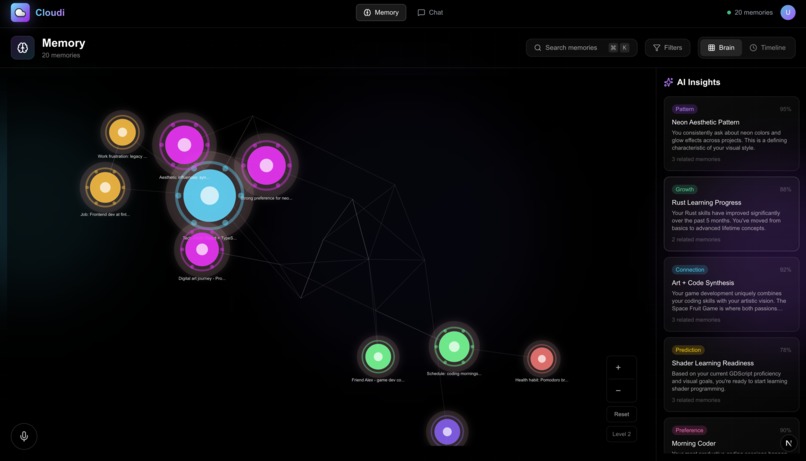
Memory in categorical view
-

Project pitch
-
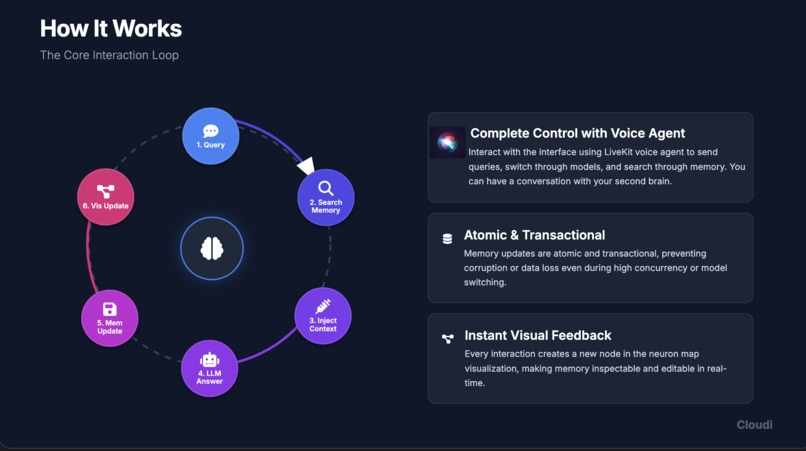
How it works
-
Mobile interface
-
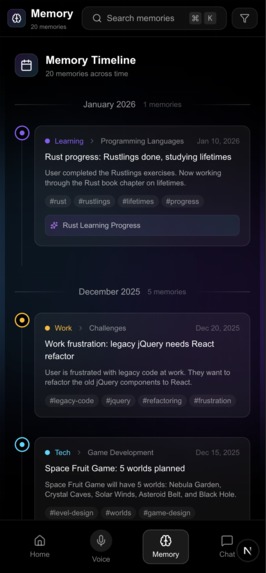
Memory in chronological view on phone
-
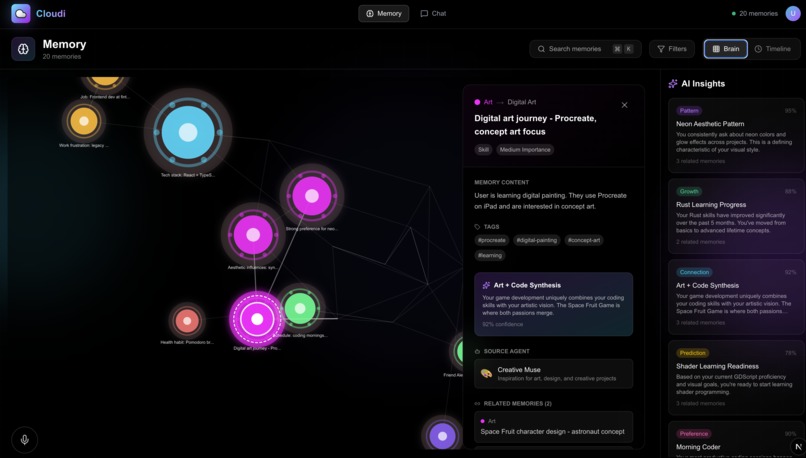
AI summary and insights of selected memory






Inspiration
Everyday users increasingly rely on multiple LLMs for different tasks, but every switch fractures context and forces them to start over. We were inspired by the gap between how users expect AI to remember long-term work and how siloed, forgetful today’s LLM experiences actually are.
What it does
Cloudi provides a persistent, shared memory layer that sits above individual LLMs, allowing users to continue the same project across models without reintroducing context. Every interaction is summarized, stored, and visualized in an interactive neuron-map interface that users can explore, edit, and resume from.
How we built it
Frontend: Framework & Core
Next.js 16 - React framework with App Router React 19 - UI library with hooks (useState, useEffect, useCallback, useMemo, useRef) TypeScript - Type safety throughout
Styling
Tailwind CSS - Utility-first CSS with custom configurations CSS Variables - For theming (dark mode with cyan/purple gradient accents)
Animation & Visualization
Framer Motion - Page transitions, component animations, AnimatePresence for mount/unmount D3-force - Physics-based graph simulation for the memory node visualization react-zoom-pan-pinch - Pan/zoom controls for the graph canvas
UI Components
Lucide React - Icon library clsx + tailwind-merge (via cn utility) - Conditional class merging
Backend: Core FastAPI Python
Memory/Database GetZep PostgreSQL
AI Services/APIs: OpenAI API Gemini API Anthropic (Claude) API LiveKit API TheTokenCompany SDK
Challenges we ran into
Problem Ideation Our first challenge was deciding on an idea to tackle. Inspired by the Overshoot welcome speech, we wanted to go with an ambitious idea, but not so ambitious that we would run out of time or not have the technical expertise. The two ideas we settled on were either an advanced ASL to text to speech recognition system, an MVP builder through a single conversation, and Cloudi. They all had their pros and cons with factors such as technical impressiveness, novelness, and sponsor track applicability playing a role but we finally decided to go with Cloudi after a LiveKit representer who we pitched to jumped enthusiastically at it.
Division of Work In the beginning, we didn't clarify how we were splitting work, so two of us ended up both working on the backend, and one of them had to eventually be scrapped. We were also unsure what build chronology would make for the most seamless integration and mistakenly made the frontend and the backend simultaneously without consulting one another. This resulted in an intense integration grind where Will worked really hard to map all the frontend end points to the backend.
Version Control Our next main challenge was getting everyone set up on the github repo. Will pushed the backend and frontend code to the repo in two separate branches, and setting that up on Rony's and Eli's computer took a while because we had to navigate around setup instructions and bugs. Eventually Eli got it to work, but Rony's could not due to an unknown error with the database where the backend was connecting to a different database than intended even though no other databases were running. Not focusing on this setback, Rony shifted to implementing TheTokenCompany's SDK for user query compression and cleaning up the frontend with Karen.
LiveKit Eli was tasked with setting up LiveKit for the sponsor track that we were intending to go most deep into. Our plan was to create a voice agent with LiveKit which could control the entire interface like a managerial agent. This involves being able to act as a control interface, entering queries that the user speaks, choosing which LLM to query to, and navigating through the visual memory interface to view past memories. However the service proved to be very confusing and took many different attempts and perspectives to get working. The computer's lack of compatibility also contributed to this problem. We eventually got it to work but ran into another problem where our api credits would run out almost instantly, much faster than advertised. Unsure how to deal with this, we attempted integration of LiveKit into our system but it failed due to hitting the API rate limit. We are still trying to figure out how to work around this.
Accomplishments that we're proud of
UI/UX Design We are proud of our UI/UX design. Using Framer Motion with Lucide React made for some smooth animations with aesthetic icons. Our color scheme is vibrant and draws the user to the screen. The simplicity of our website makes it intuitive and more useful.
Seamless LLM Switching without Context Loss Our MAIN goal was to achieve model switching without context loss and we have achieved it. Using our design flow of Query --> Search Memory --> Inject Context --> LLM Answer --> Memory Update --> Visualization Update, we were able to switch models without having to worry about model specific memory because they all shared a universal memory database powered by GetZep and PostgreSQL. Telling ChatGPT a statement and then asking a question about that statement to Gemini worked as if they were the same model.
Memory Map Visualization Our memory map visualization was especially creative and intuitive. It uses D3-force-graph to create a neuron map of ideas that are similarly related in clusters. Each cluster has a label for what concept encapsulates all the chat memories close to it. It is easy to navigate around, and the user can click on specific nodes to access that memory summary from the chat. This takes the idea even further from just an interface to switch between models without context loss to a complete second brain where you can view all your memories and interact with your most used models.
Other Goals One last goal that we thought was less visible but still important was the energy and efficiency impact our design has. First of all, having minimal context loss means that less total queries are needed in between models which decreases the overall token usage of a user substantially. Additionally by applying TheTokenCompany SDK, we were able to compress user queries by 66% without context loss to further decrease token usage. Overall, we believe this system has extreme potential to revolutionize how LLM's are used for this reason and the others mentioned above.
What we learned
Integration One of our biggest challenges was integrating the frontend and backend that we built at the same time, and while it felt like a huge hurdle at first, it ended up being one of our biggest learning experiences. Because the frontend didn’t have clearly defined backend endpoints at the start, we had to constantly communicate, test assumptions, and adjust our code as the project evolved. Through this process, we learned how frontend and backend systems actually talk to each other, how important clear data contracts are, and how to iteratively bring two moving parts together into a working product.
API Key Usage Another important lesson we learned was how to properly use and manage API keys when working with multiple AI services. We learned how to securely store keys using environment variables instead of hard-coding them, how to pass them safely from the backend when making external API calls, and why exposing keys on the frontend can be a serious security risk. This helped us better understand real-world security practices, rate limits, and cost control, and showed us that even small projects need thoughtful handling of sensitive credentials to avoid unintended issues. We also spent a lot of money :)
Organization A lot of our challenges also came from a lack of organization and clear communication within the team, especially early on. Because roles and responsibilities weren’t always clearly defined, some people ended up working on the same backend tasks while others weren’t sure how to move forward on areas like the LiveKit sponsor track. This experience taught us how important it is to set clear ownership, communicate progress frequently, and make sure everyone understands both the technical goals and their role in achieving them, especially when working under tight time constraints.
What's next for Cloudi
For the future, we aim to make Cloudi an AI companion that is integrated into daily life, constantly learning about you, mirroring your actions, and providing you with valuable insights. In terms of design, we will add a better filtering, pinning, and editing system for the memories. We will also add physics that show categories breaking into smaller units. In terms of the infrastructure, we aim to secure our database and prepare our product for the market. We also hope to gain partnerships with more AI agents to diversify our models and chat memories. In order to make the most use of storage and context windows, we would like to use tools that reduce our tokens and provide a succinct summary of memories.



Log in or sign up for Devpost to join the conversation.