-
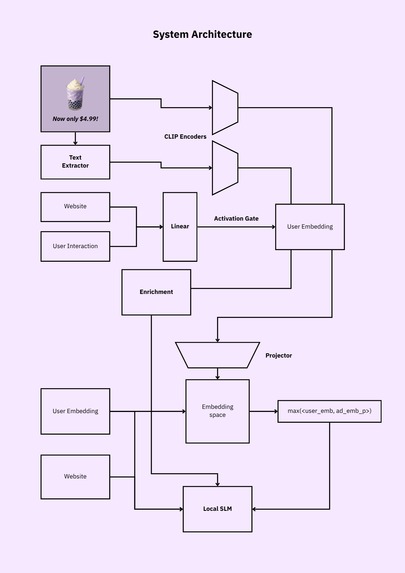
System Overview

Big tech ad networks rely on tracking and personal data to target users. PrivAds is a new kind of ad platform: it predicts what ads users are most likely to engage with — without ever storing their identity, browsing history, or demographics. We use only click feedback and page context to serve relevant, privacy-respecting ads.
Inspiration
We took ideas from many of the challenges at CalHacks. For example, we loved AppLovin’s challenge to extract high-value signals from ads as a way to gain user insights, but we built upon that and pushed it further by asking: “What if we could build an ad recommendation engine that’s smart and privacy first?” We also drew from Y Combinator’s AI native track to imagine what an AI-powered, privacy-centric alternative to existing Y Combinator ad startups, such as Plai, might look like in today’s world.
What we do
Imagine an ad network that actually respects your privacy. Instead of tracking you with cookies and personal data, our system learns from your interactions like what types of ads you click on, what pages you are interested in, and builds a privacy-first user embedding that never stores your identity. We process ad images or videos using multimodal AI, where we extract visual, textual, and contextual signals from images and videos using a VLM encoder. Then, we use contrastive learning to "match" those embeddings against a user’s embedding space. With Fetch.ai, we simulate autonomous user personas who explore thousands of ads, and Claude AI helps us model click probabilities for each ad-user pair. This all came together into a scalable, privacy-first ad recommendation engine that knows what you like without knowing who you are.
What makes us special
- No user tracking or segments: We use user embeddings, not personas or segments that could be traced back.
- Multimodal ad understanding: Ads are processed with a vision-language model (Jina CLIP v2) to extract both visual and textual signals.
- Context-aware serving: Ad selection considers both user embedding and the current page context.
- Custom and dynamic ads: The system can generate or enhance ads on the fly, tailored to user interests and page content.
- Less ads: Showing ads to people who are not going to interact with the material is a waste of time and money. For instance, if someone's in a hurry, they won't click on any ads. We detect user interaction patterns and avoid showing ads when we anticipate low performance. Everybody wins!
How we built it
Dataset collection: The contrastive learning model requires data on ads and users interacting with those ads. To do so, we built on AppLovin's provided dataset. We used Google Gemini and Reka to extract key features from image and video ads, respectively. We then used an Anthropic AI agent with BrightData's MCP server and Langchain to build a large dataset of ads. Furthermore, for user dataset generation, we used another agent to build realistic user profiles.
Contrastive Learning LLM for Ad-Serving: Unlike OpenAI's CLIP model, instead of a one-to-one relationship amongst data, we have many users interacting with many ads -- aka many-to-many data. We generate embeddings for user profiles, context of the user, and ads. The model crunches out which ads to serve to which users. The model is deployed at an endpoint.
Platform for companies: In the grand scheme of things, the ad-serving platform serves companies publishing advertisements. We have already figured out ad-understanding, customer-segmentation, and effective ad-serving.
Custom Ads: The platform allows companies to generate custom ads; companies can also opt to enhance their pre-existing ads dynamically on each user's device. The system extracts contextual information about the app / webpage the ad is being deployed on, makes inferences about the user, and specifically tailors the ad to the user's interests to improve click-through rate.
Demo website:
https://privads-demo.onrender.com/
Challenges we ran into
It was a very complex system to implement because there were several dependent parts. While we doubled down on the research problem of effectively learning from creatives granted high dimensional data, we ideated a lot about what direction to take it in as a product, what problem we were solving for our users (companies), and our unique value proposition. Luckily, we were able to find our direction and niche.
Accomplishments that we're proud of
To have built so many agents and a custom LLM for ad-serving that works despite high-dimensional, sparse data.
What we learned
Architecture matters: Separating concerns (frontend, web_ad_service, backend) makes scaling easier, but coordinating them and building them separately at the same time as a team is complex. Environment management: Having one shared miniconda env for multiple services is messy; separate envs or containers (Docker) are better. Privacy-first is hard but valuable - Building without personal data tracking is more complex but more aligned with user interests We learned to test external APIs in isolation. Setting up isolated tests for each part of the frontend customized ad generation pipeline is what helped us catch the real issue in the process not working.
What's next for PrivAds
Comparing the use of contrastive learning to ML models oriented toward high-dimensional sparse data.
Built With
- agents
- anthropic
- brightdata
- gemini
- javascript
- python
- reka
- torch
- transformers
- transformers-js


Log in or sign up for Devpost to join the conversation.