-
-
Landing page for user
-
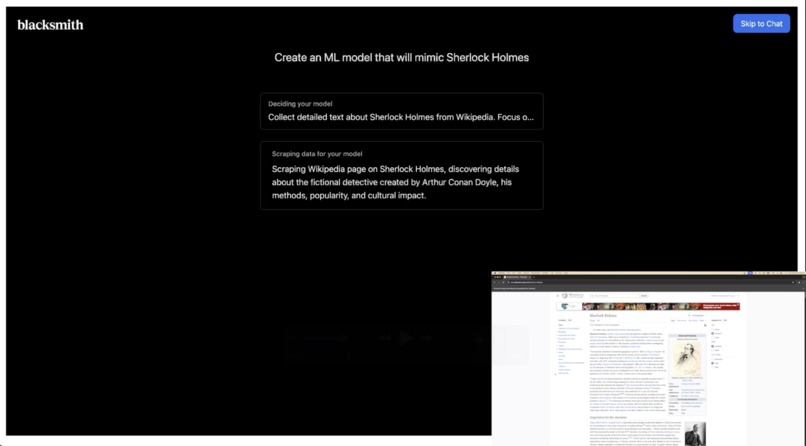
Webscraping demo + Visual User feedback
-
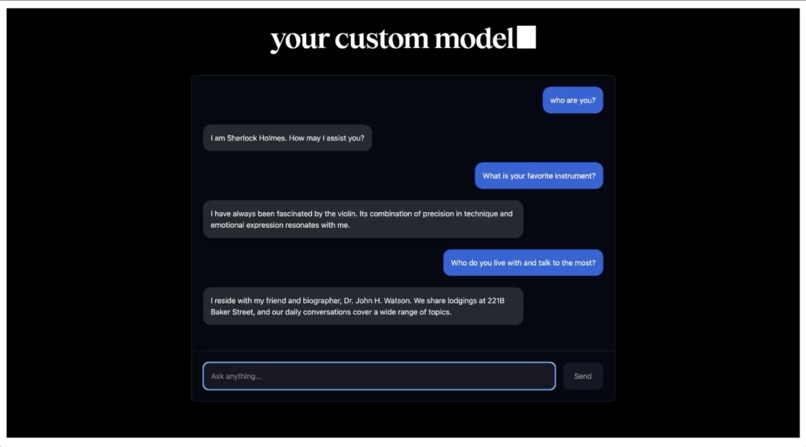
Deployed finetuned chatbot Model
-




Inspiration
First, we witnessed how Webflow revolutionized web development by abstracting complex coding into intuitive visual interfaces, empowering non-technical creators to build sophisticated websites. This democratization of web development sparked our vision to do the same for machine learning - creating a platform that removes technical barriers and allows users to express their AI needs without dealing with the underlying complexity.
Second, Databricks' AutoML platform showed us the power of automated machine learning for classical ML techniques like XGBoost. While their platform serves enterprise users and data scientists effectively, we saw an opportunity to push this concept further. Our vision extends beyond traditional ML by incorporating fine-tuned LLMs and making the entire process more accessible through intelligent agents that handle web scraping and data collection completely automatically, without the user having to lift a finger.
Finally, we were captivated by the potential of complex multi-agent workflows to build smaller, more specialized models. The idea of multiple AI agents working in concert - each handling specific tasks like data collection, preprocessing, and optimization - inspired us to bring this vision to life during TreeHacks. This approach not only makes model development more efficient but also opens up new possibilities for creating highly specialized AI models.
What it does
Blacksmith is a no-code, text-only ML training and deployment automation platform. Buzzwords aside, all this means is you put in text, you get out ML models :) With just simple prompts like “Create an ML model based on George Washington”, you’ll get a personalized, historically accurate agent for the first president. Not only do you immediately have access to the chatbot just 10 minutes after you request your model, you also have an API endpoint that can then be as part of your larger multi-agent workflow.
Traditionally, this process is extremely tedious and impossible for someone who is just getting into machine learning. For finetuning models, data has to be manually scraped and collected, converted into a Q/A format, labeled, uploaded, and finetuned. For training models from scratch, it’s even worse! You need to set up the machine learning codebase yourself and be very very careful when training these sensitive models. We want machine learning to be accessible to everyone, with the power of personalized agents in every person and organization’s hands.
Blacksmith makes this possible. Given the text prompt, it first figures out the type of model and data that should be used. Then we use our extremely fast, custom, multi-agent Computer Use system to jump through webpages and extract raw data for our model. The data is automatically organized and labeled, then GPT and/or Mistral is used for the finetuning process.
Once the model is fully trained, you have access to the API endpoint and the chatbot, making the world your oyster!
How we built it
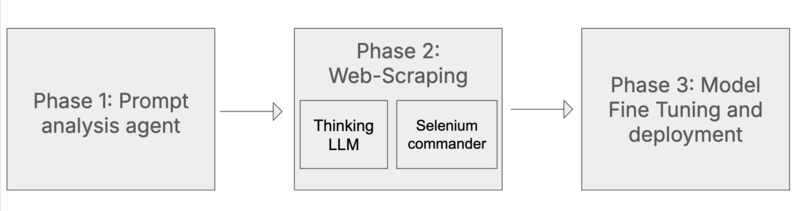
How we built it To create an end-to-end process that transforms a simple user prompt into a fully functional ML model, we developed a sophisticated multi-agent workflow system operating in three distinct phases:
Phase 1: Prompt Analysis Agent: Our initial agent performs deep analysis of the user's prompt through analysing three key aspects of what is required next in the workflow.
Model type selection: This agent determines whether to use OpenAI or Mistral's base models based on the specific use case requirements and performance characteristics. We use NLP techniques to parse user intent and map it to specific model architectures. For instance, if a user wants to create a customer service bot, the first thing this agent decides is its model.
Data type requirements: Simple selection of what needs datatypes need to be collected in order to train/finetune a machine learning model that suits our users needs; especially useful as we plan to incorporate vision and audio in future in addition to text
Web scraping prompt formulation: Transforms user requirements into sophisticated search strategies that combine domain-specific keywords with contextual parameters. For example, "customer service interactions" might be expanded to include "support tickets", "FAQ responses", and "resolution examples".
Phase 2: Intelligent Web Scraping Agents - Our dual-LLM architecture orchestrates sophisticated web scraping:
Thinking LLM: Functions as a strategic orchestrator for the scraping, maintaining a comprehensive understanding of the scraping mission's progress and goals. Continuously evaluating webpage content against the target data requirements, making real-time decisions about which content to extract and where to navigate next with state management. Incorporating learned patterns from successful data extraction attempts and adapting to different website structures.
Selenium Commander LLM: Translates high-level directives from the thinking LLM into precise, executable Selenium commands, handling complex scenarios, and optimizing scraping execution speed. These commands are directly executed using Seleniums computer use and are used to navigate the web and scrape useful data.
Phase 3: Model Fine-tuning & Deployment Agent
Data Processing & Formatting: Implements cleaning algorithms that normalize the scraped content, remove irrelevant information, and ensure consistency across different sources. Generates high-quality question-answer pairs from raw scraped data, ensuring each pair contributes meaningful finetuning signals to the model.
Model Training Integration: Manages the entire fine-tuning pipeline through direct integration with OpenAI and Mistral's APIs, handling authentication, data upload, and training monitoring.
Deployment Architecture: Implements a responsive chat interface that handles real-time model inference while maintaining low latency and high availability.
The result is a fully automated pipeline that transforms a simple user prompt into a production-ready, domain-specialized LLM, making advanced AI development accessible to non-technical users while maintaining enterprise-grade quality and reliability.
Challenges we ran into
The most difficult part of this process was the web scraping section. Given the unstructured nature of the web, it became near impossible for us to extract data using classical techniques, so we turned to state-of-the-art models like Computer Use for scraping. However, since most of these models use manual mouse and keyboard inputs, the time for webscraping simply was taking way too long. Given this, we decided to build our own Computer Use system that was much, much faster, but also more deterministic.
Using a novel multi-agent optimization algorithm integrating Selenium, we enable step-by-step navigation on the web with source code reflection. A Thinker and a Worker work in tandem to create and run Selenium commands on the server, with constant summaries being returned to the frontend. With this, we cut down our time for data collection by multiple orders of magnitude!
Accomplishments that we're proud of
Our biggest accomplishment was our novel autonomous web scraping technology described in the challenges section :)
We’re also really proud of how integrated and end-to-end our solution is. The first time we were able to get the full system from prompt to chatbot running perfectly was a huge milestone for us, and we want to share the same delights we have training machine learning models with everyone in the world, not just with experts in the field.
What we learned
We learned so much about the finetuning process and how all of these APIs work together. The orchestration process between multiple agents depending on each other was a huge learning curve at first, since it feels a little like managing a distributed system of really smart toddlers LOL. But this whole process was super fun and the integration with traditional tools like Selenium was a big part of our learning process.
Outside of this, our background is largely in machine learning itself and not too much in the web domain, so building a web workflow that seamlessly integrates with our frontend was a big learning process for us!
What's next for Blacksmith
We have so much planned for Blacksmith! The very first thing we want to work on is diversifying all of the models that we support. Right now, we support text models from OpenAI and Mistral, but we really want to integrate something like the RoboFlow universe into our system, where you can work on large amounts of computer vision models and train them from scratch based purely on a text prompt.
For bigger enterprise use cases, we also want users and organizations to allow for training with their own unstructured data that we will automatically label and organize for them. A big pain point in finetuning is the data formatting part, and Blacksmith’s custom Computer Use is really really good at figuring out what data is important and how to format it best for finetuning purposes.
Built With
- computer-use
- fastapi
- gpt
- mistral
- muli-agent-workflow
- next.js
- openai
- python
- selenium
- typescript







Log in or sign up for Devpost to join the conversation.