-
-
Landing Page
-
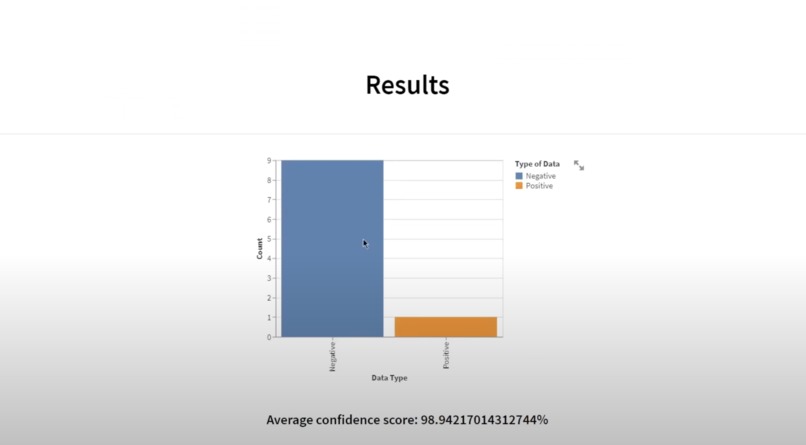
URL Data Results for demo
-
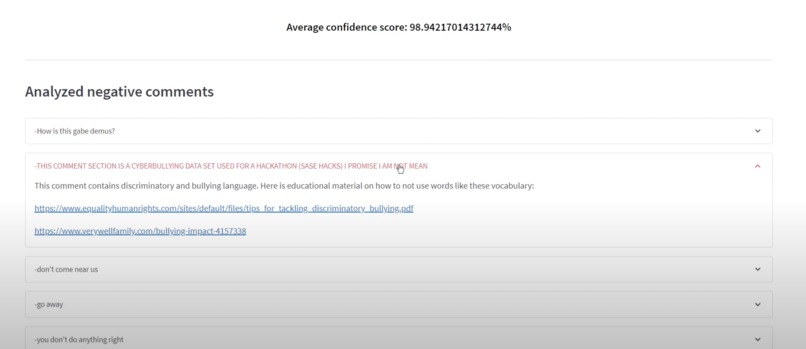
The Negative comments and the categories
-
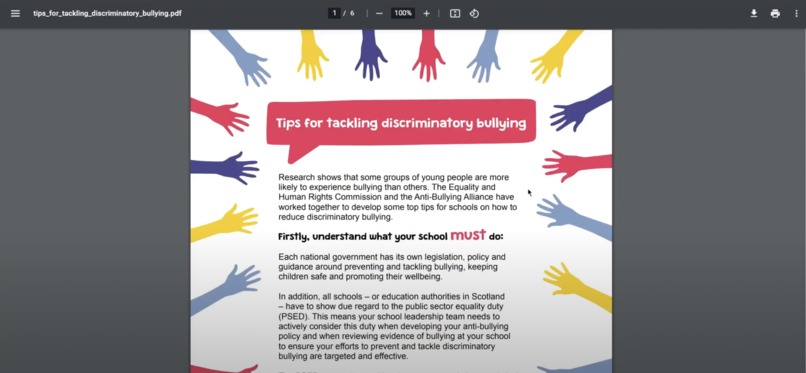
URL for educational purpose
-
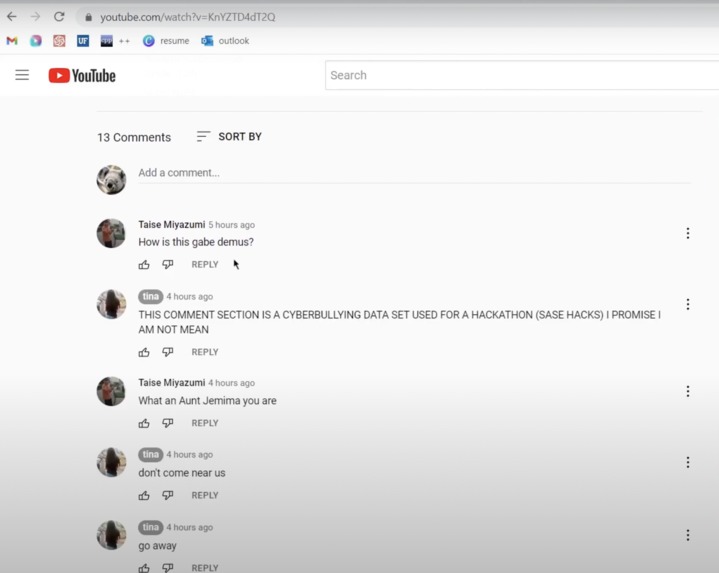
Youtube Post that was parsed and analyzed
-
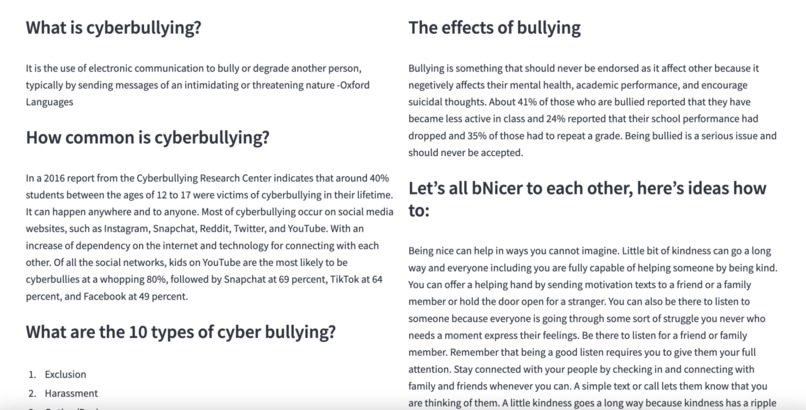
The bottom of the website for information pt.1
-

The bottom of the website for information pt.2







Inspiration
When coming up with an idea, we researched about bullying and often it occurs. We found out that almost half of students between 12 to 17 have experienced some sort of bullying. To try and minimize this, we had the idea to identify negativity in text through a deep learning network. Our ideal project was to be able to identify negative texts through a chrome extension, but due to time, we decided to make a proof of concept and launch it on a website.
What it does
Our website takes a YouTube URL as an input. It then opens the page on a separate chrome browser and loads the given URL. Then, using the library youtube_comment_scraper_python we were able to extract all the comments on that webpage and store them in a list object. The list then gets parsed through by the deep learning model and returns positive or negative corresponding to the tone of the message. If the message ends up being marked as negative, we go through a second layer of search. We check if the string has any substring containing foul words. We do this by preemptively preparing different dictionaries corresponding to words that are discriminatory, bullying, or offensive or a combination of the three. Those correlations are then returned on the website along with education material that can help improve the person’s opinions, actions, and vocabulary so they never stoop as low as the commentors.
How we built it
We utilized Streamlit as our front-end interface for the website interaction and design. Then for the neural network we used the Jupyter Notebook, Python, transformers package and TensorFlow (and a few others) to make a machine that detects tone for natural language processing. Our data was trained using a labeled twitter-data base. For our second layer, we used a substring detection mechanism to look through our premade lists to find overlap with the comment. Our lists were also separated based on words containing racism, words containing discrimination, and words containing offensive language. So when we found matches in one category or multiple, we were able to provide educational material that can divert the user from exemplifying those actions.
Challenges we ran into
We faced some challenges throughout the project. At the beginning, we struggled to find an idea that would fit the challenge and something that we all believed in. We agreed that the idea is the most important part so we took our time coming up with an idea. We also ran into issues with the computer architecture as some APIs and packages only worked on Windows and three of us have Macbooks. We were also beginners at Machine Learning and using TensorFlow, hence it took a long time to research and figure out the machine learning model created. Another issue we ran into was being able to iterate through a website URL for the comment section because sometimes the WebDriver did not work, which caused multiple hours of research on the issue and debugging it by trial and error. Some of us were unfamiliar with GitHub so there was some issues with repositories as well.
Accomplishments that we're proud of
We are all proud of being determined to create a helpful product even after 25+ hours and having enough stamina to push through a 21 hour window of continuous coding. We are also proud of the website’s potential impact and those that will utilize it. Being able to learn more about Machine Learning, TensorFlow, Python, Git/Github, and etc was a huge accomplishment we had!
What we learned
We learned that it is necessary to write clean and neat code and add comments throughout or else it is easy to get lost in the middle of coding when it’s necessary to look back and add elements. We all tackled some parts of the code that we were unfamiliar with. For example, some of us were unfamiliar with Streamlit and some were unfamiliar with machine learning algorithm. For all of us, there were so many packages and files that we have never seen before. We did a lot of googling, but with patience, determination, and pure curiosity, we were able to have fun creating this project while learning a plethora.
What's next for bNicer
There are many possible improvements for bNicer. First, we want to add an in-text sentence analyzer so the algorithm can detect if you are being unintentionally hurtful to someone before you send your message. This could be used when you are drafting a comment on Instagram or writing an email. Another feature we looking forward to add is user authentication, so that users may create accounts and log down their findings and have a history of their searches. We also want to branch out to other social media sites that kids use such as Roblox, Instagram, and etc. This application has a huge potential; teachers are able scan for potential harmful words before assigning a task to students to ensure there is no unintentional harm done.





Log in or sign up for Devpost to join the conversation.