-
-
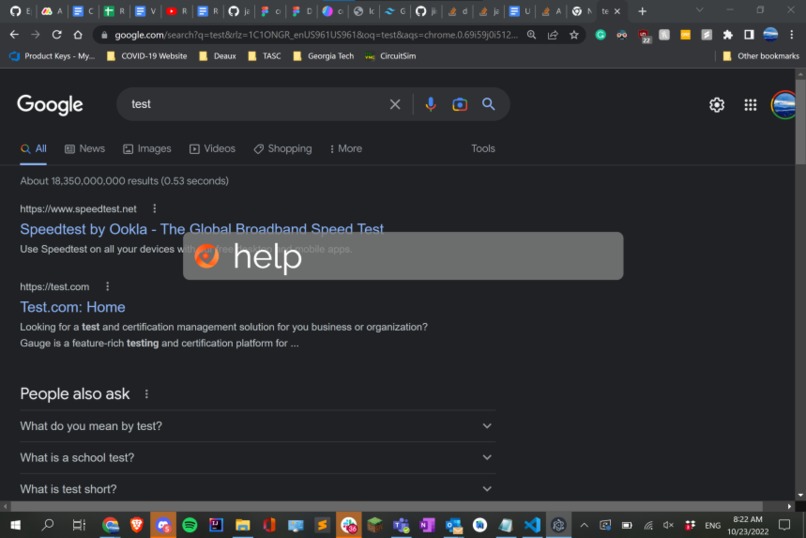
Image of the interface
-
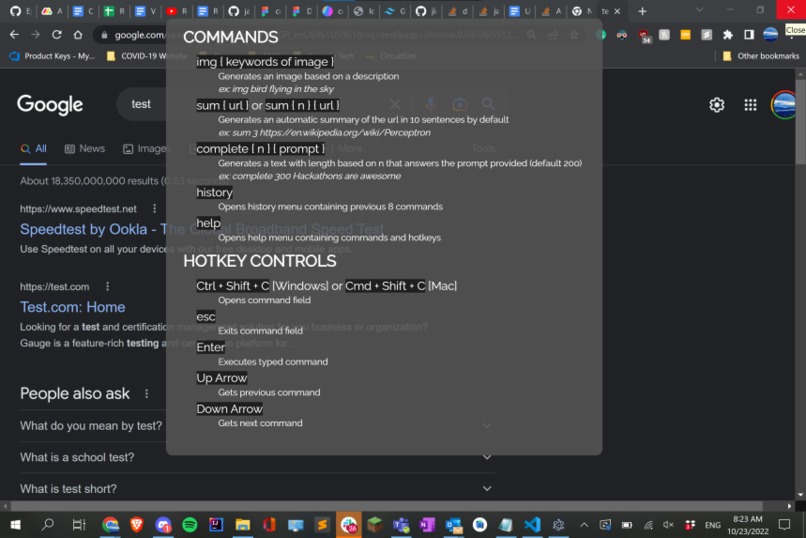
List of commands & hotkeys (generated with the help command)


Inspiration
Novel machine learning models have been released in the last few years, but they're incredibly difficult to set up and use. Ceptron is a solution to change this.
What it does
Ceptron is a clipboard for ML. Using the keyboard shortcut Ctrl+Shift+C invokes ML models, copying their output to the clipboard. For example, the command "summarize https://techcrunch.com/2022/10/21/techcrunch-roundup-plg-and-enterprise-sales-saas-pricing-strategy-opt-options/" copies a summary of the article to the clipboard.
There are currently three functions:
- summarize: Generates a summary of text given a link to the text.
- image: Generates a 512x512 image created from a user-provided prompt with Stable Diffusion.
- complete: Uses GPT-3 for state-of-the-art autocompletion.
All outputs are copied to the clipboard and can be pasted onto any document.
How we built it
We used GCP for all our cloud deployments:
- Cloud Run
- Compute Engine
- Firebase Hosting
Cloud Run hosts the backend for summarize. Because summarize is less resource-intensive, we used Cloud Run to ensure a reproducible, consistent environment that automatically rebuilds & redeploys on every commit.
Compute Engine was used to host Stable Diffusion due to the large amount of disk space and resources required to generate images. Since Cloud Run does not support GPUs, we needed to use Compute Engine to be able to run the inference model.
Firebase is used both for routing of our application and static hosting for our landing page. The backend is routed to ceptron.tech/api via a Firebase rule, while our landing page lives on ceptron.tech.
The frontend is built with Electron. It captures global keyboard shortcuts, parses commands, executes the commands on servers, and copies the results & return values to the clipboard. Because the clipboard is general purpose, it can be used in any application.
Challenges we ran into
- Logistics of running large models. Failing CPU inference, out of memory errors, network errors while uploading/downloading weights, etc.
- Moving onto Compute Engine presented another set of challenges, including setting up the environment required for Compute Engine, transferring code and data between our local environments and the VM, and accepting and returning API calls within the virtual machine.
- This is the first time any of us have worked with GPUs on Compute Engine.
- The models were extremely large, containing billions of parameters, making them difficult to deploy.
Accomplishments that we're proud of
- Running stable diffusion on a VM with GPU. This was the first time any of our team members has done this!
- Achieving a simple, yet polished UI.
- Adding additional features to the original project idea such as history and tab completion.
What we learned
- Hardware specs such as GPUs and large amounts of RAM are necessary for virtually all large ML models (> 1 billion parameters). Plan accordingly by reserving a large VM in the cloud.
- How to create an API using FastAPI to encapsulate business logic (in this case, running inference on ML models).
- How to create a cross-platform desktop application with web technologies using Electron.
- Deploying ML is challenging!
What's next for Ceptron
Expand the model suite to include more architectures. Ceptron is currently a proof of concept, but we'd love to broaden the applications of instant ML model invocation further.





Log in or sign up for Devpost to join the conversation.