-
-
Codeplexity: AI-powered search for Github codebases
-
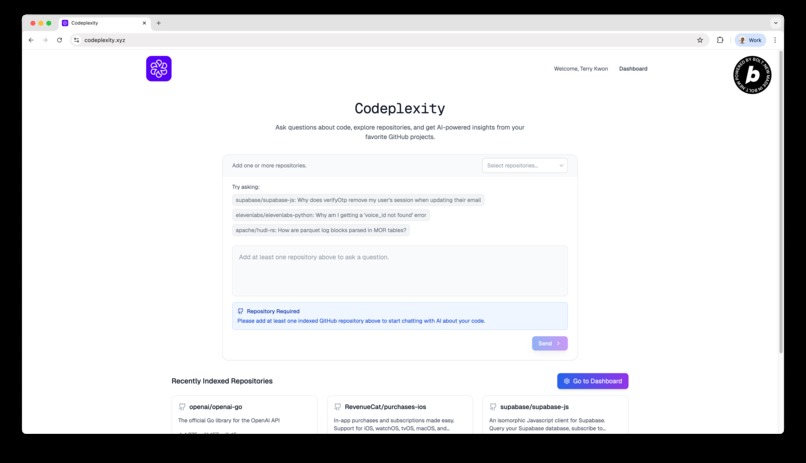
Ask questions about code, explore repositories, and get AI-powered insights from your favorite GitHub projects.
-
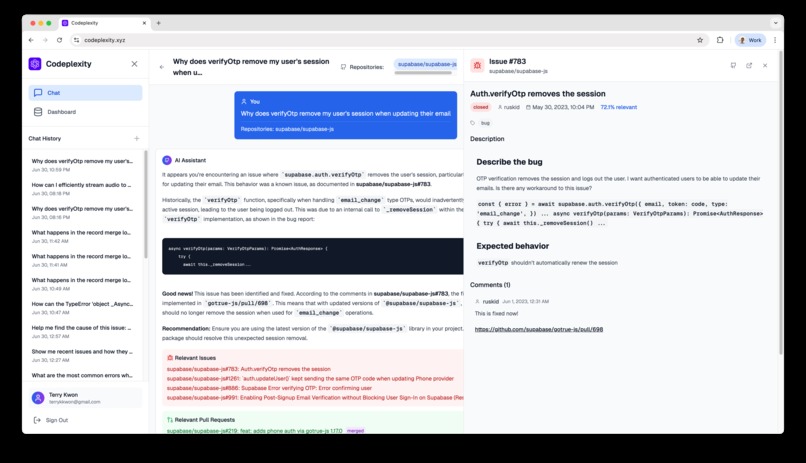
Get AI-powered answers to your questions with up-to-date references to code files, Github issues, and even Jira tickets.
-
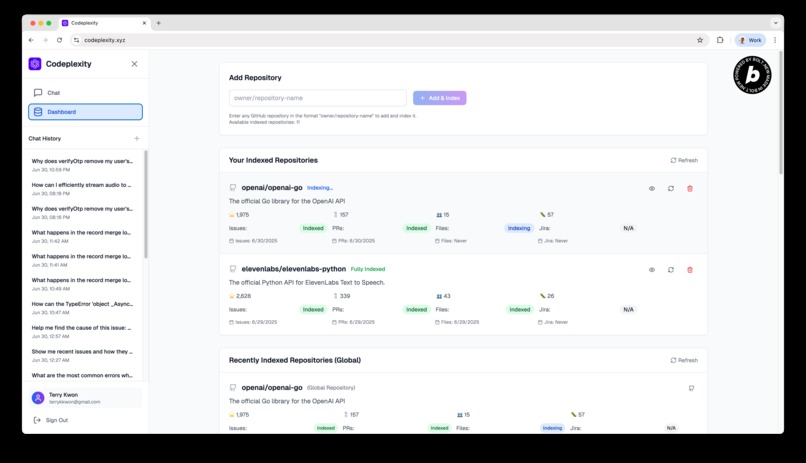
You can add any public Github repo as well, and Codeplexity will make it searchable by creating an index in the background.
-
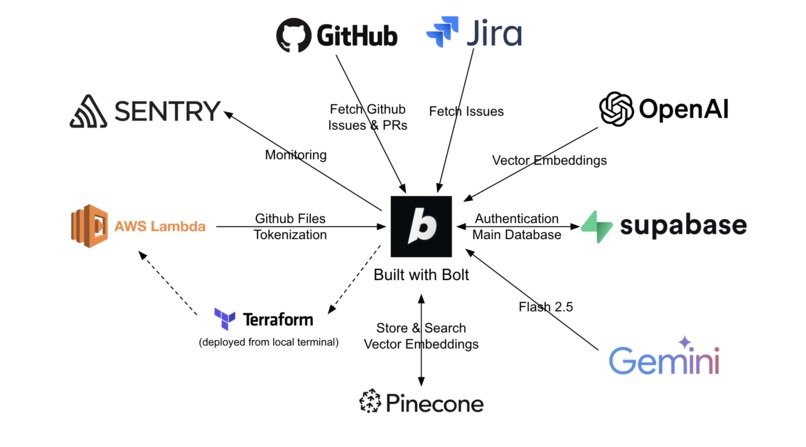
Codeplexity is built on top of Bolt using various services to provide the best AI-generated response with sources specified.





Inspiration
Every developer has experienced the struggle - you're trying to use open-source software, but you hit an error and get stuck 20 tabs deep into GitHub issues, pull requests, and source code. We have all spent hours piecing together solutions from fragmented discussions across issues from 2019, closed PRs with crucial context, and cryptic error messages in the codebase.
We asked ourselves - what if we could just ask questions to the repository directly?
What it does
Codeplexity transforms how engineers interact with open-source repositories through conversation. Instead of manually searching through documentation, issues, and code, engineers can simply ask questions in plain English and get intelligent, contextual answers. Our AI engine analyzes the entire repository ecosystem - GitHub issues, pull requests, source code, and even JIRA tickets when available - to synthesize accurate answers.
But we don't just give you an AI response; we show our work. Every answer comes with the exact sources displayed side-by-side, with relevant code lines highlighted, so you can verify the information and dive deeper when needed.
How we built it
Our architecture combines modern AI infrastructure with robust data processing:
Core Tech Stack:
- Bolt as our primary development framework
- GitHub & JIRA APIs for fetching repository issues, PRs, and code
- Pinecone for vector storage and semantic search
- OpenAI for generating vector embeddings of text chunks
- Gemini for AI-powered responses
- Supabase for authentication and persistent storage of repository metadata, GitHub data, and chat history
- AWS Lambda for serverless Github source code processing and tokenization
- Terraform for deploying AWS Lambda
- Sentry for monitoring and error tracking for a production-grade application
RAG Pipeline:
- Data Ingestion: Supabase Edge Functions fetch GitHub issues, PRs, code files, and JIRA tickets
- Code Processing: AWS Lambda tokenizes source files while preserving code structure and context
- Vector Generation: OpenAI embeddings capture the semantic meaning of all content, stored in Pinecone for efficient retrieval
- Query Processing: User questions are embedded, and matched against indexed content in Pinecone. Relevant context based on vector similarity search is provided to Gemini for generating accurate, contextual responses
- Source Attribution: Responses are displayed alongside sources with precise line-level highlighting
This architecture ensures scalability and maintains traceability from question to source.
Challenges we ran into
1. Context Window Limitations
- GitHub issues and PRs can be extremely long with hundreds of comments
- Solution: Implemented smart chunking and relevance scoring to extract only the most pertinent sections
2. Performance
- Users expect instant responses, but processing large repositories is computationally intensive
- Solution: Users can pre-index public GitHub repositories incrementally so that vector search is faster at the point of asking questions.
3. Accuracy vs. Completeness
- Balancing between giving comprehensive answers and avoiding hallucinations
- Solution: Always show sources and implement confidence scoring to indicate answer reliability
4. Bolt token usage
- Due to the engineering complexity of Codeplexity, per-query token usage on Bolt accelerated as the project became bigger.
- Solution: Regularly refactor the codebase so that less code will be updated. We also duplicated the project several times to wipe out the chat history context.
What we learned
- Open source is more than code - The real knowledge lives in the discussions, decisions, and collective problem-solving captured in issues and PRs
- Importance of text pre-processing - Vector embedding can become expensive at scale. Applying various optimization techniques at the text processing level as well as infrastructure and system design level is necessary.
- Context is everything - A single line of code means nothing without understanding the issue that prompted it or the PR discussion that refined it
- Human interpretability is important - Engineers need to see exactly where information comes from, which is why our side-by-side source view is important in providing entry points for engineers to dive deep.
What's next for Codeplexity
In the age of Vibe Coding, the importance of debugging will increase over time. At the same time, open-source software will continuously grow in the future. We will improve the UI/UX of the products to help engineers and non-engineers resolve issues they run into while using open-source software. Furthermore, we will make it easier for them to participate and contribute to the projects they are using.
In terms of engineering, we will enhance our repository indexing mechanism to be more scalable and cost-efficient.
Built With
- amazon-web-services
- bolt
- gemini
- github
- jira
- lambda
- openai
- pinecone
- react
- sentry
- supabase
- terraform





Log in or sign up for Devpost to join the conversation.