-
-

Cover Image

TLDR
We are a developer toolkit which provides a decentralized database as a service where users can use our endpoints as well as NoCode tool where users can upload their data in a decentralised manner.
Inspiration
👋🏻 With the advent of Web3, there are now decentralized ways to store data that are a hundred times cheaper than Web2 solutions. Such methods are equally, if not more secure, dependable and scalable.
😩 However, using them remains vastly more technically challenging and time consuming than traditional alternatives.
🤓 As Web3 developers, even as we've sought to push the envelope with frontier blockchain technology, we've run into limitations with Web2 solutions time and time again.
What it does
🫡 ControlDB’s mission is to bridge this gap between cost and performance, allowing developers to use exponentially cheaper IPFS distributed file storage, while circumventing much of the complexity and limitations that normally come with it.
🚀 IPFS, the InterPlanetary File System, is a peer-to-peer file sharing network. Files are sharded across multiple nodes. Building on this protocol allows ControlDB to fundamentally ensure user data remains decentralized, preventing a single source of failure because of IPFS' distributed nature.
❌ A limitation of IPFS, however, is that shards of files are made public.
✅ To overcome this, ControlDB adds an additional layer of encryption to further increase user privacy. In the event that a user's IPFS hash is intercepted, an attacker will still have to circumvent the additional layer of advanced encryption, keeping users' data safe.
❌ IPFS also has no inherent read or write controls, necessary for handling sensitive data across multiple agents, for example in healthcare.
✅ Here ControlDB introduces a permission layer onto files, allowing admins to designate different levels of file access across multiple stakeholders with varied roles.
❌ IPFS is also accessed through command line interface, making it hard to debug and understand.
✅ In contrast ControlDB adds a user-friendly GUI on top of IPFS’ command line based function, allowing non-technical users to access its features. A simplified API makes it easy and quick for developers to implement ControlDB’s file storage into their programs. Doing so circumvents the need for developers to build a new IPFS pipeline, reducing the barrier to entry for smaller and/or less experienced teams.
✅ Our architecture is designed to be plug-and-play, which means that you can easily switch between different storage endpoints, such as IPFS or Estuary or any other option where you just need to add a configuration file, depending on your needs. This provides you with the flexibility to use the database of your choice, while still taking advantage of our platform's powerful features.
🔥🔥🔥 Altogether ControlDB will save developers significant amounts of time, money and technical headache, allowing them to scale usage from simple to complex use cases as their software grows.
😌😌😌 It will also improve the availability of files, reduce privacy concerns, and grant users increased control over their data.
Demo
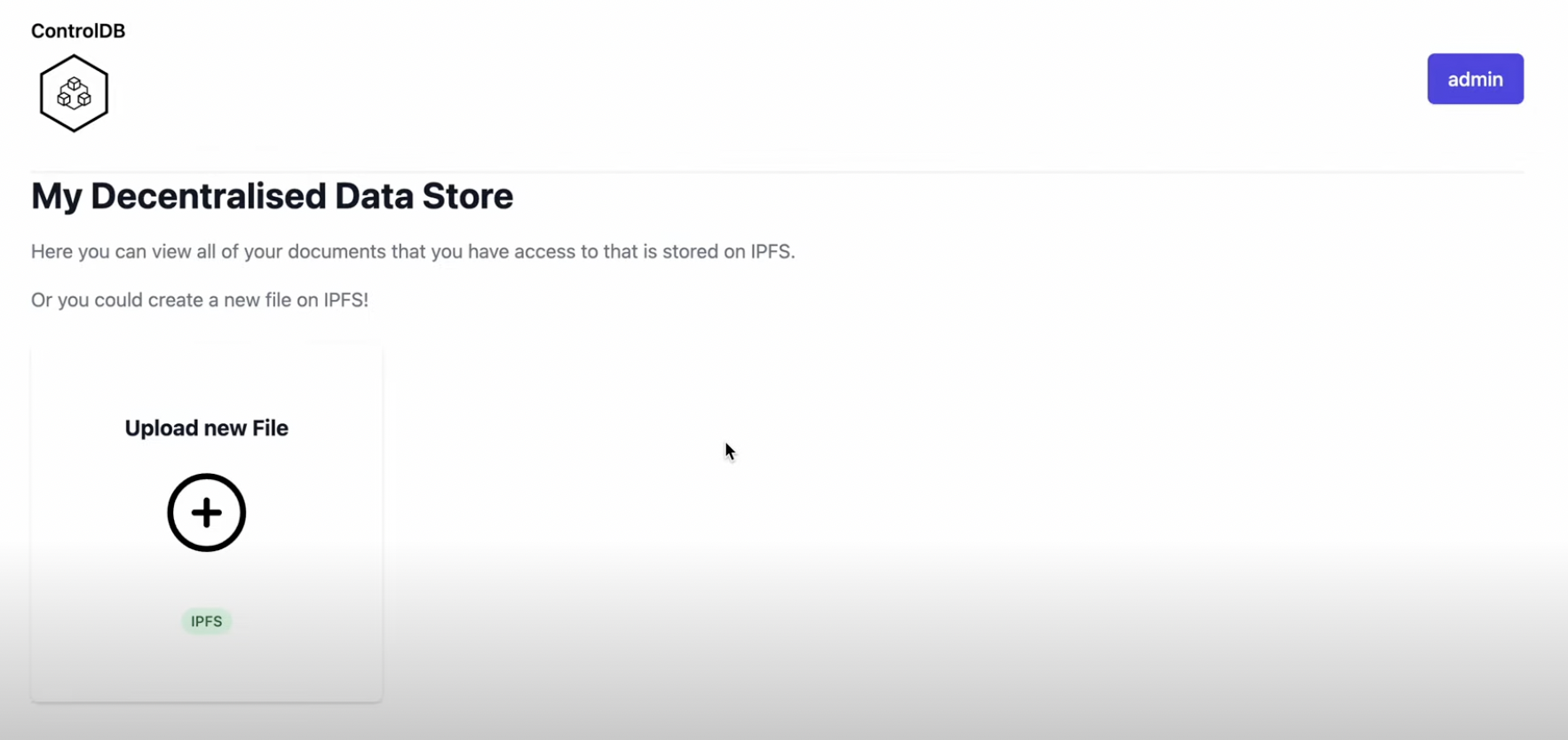
How we built it
🛠️ ControlDB was built with TypeScript and Golang. Its MVP consists of a fully functional backend with full encryption, decryption and sharding across multiple nodes implemented, as well as a fully functional frontend with login, file upload and retrieval. We even built a working user interface.
🤝🏻 Yes, everything is fully working. 🫡🫡🫡
Technical Architecture
Overall Architecture
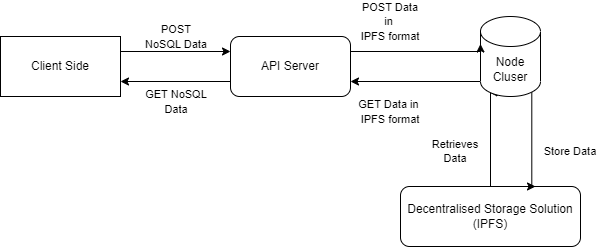

We have an API Server which interacts with the Node Cluster which is a wrapper to any decentralised storage system. We spun up 3 IPFS nodes locally which are used as the decentralised storage engine.
No code frontend tool Our front end allows users to easily upload their data onto decentralised file storage quickly without any hassle or code.
API Server
API Server: This layer accepts user requests via our Frontend as well as the HTTP API requests. The permissions are fetched out of payload which user sent and then the main data is used for the further part.
Middleware Node Cluster
Middleware Node: A search engine is developed in this layer using B+ Trees for faster retrieval of data and lookup. As the data is received from the user, we encrypt it using AES-256 and generate the encryption key. A unique id is also generated in this node which will be used as a key for insertion in the B+ Tree. The package of permissions, encryption key and IPFS Hash is generated for the insertion in B+ Trees.
IPFS Nodes We have started 3 IPFS nodes which interacts with our middleware node.
Firstly, IPFS is installed on the operating system by following the official IPFS documentation. This step provides the necessary software to create and manage the IPFS cluster.
Next, IPFS is initialized on each node using the ipfs init command, which creates configuration files for ipfs-cluster-ctl to interact with the nodes. This step is essential to ensure that the IPFS nodes are ready to be managed by the cluster.
A configuration file is created using the default docker-compose.yml file, or a custom configuration file can be used to set up the cluster. The configuration file specifies how many IPFS cluster nodes and Kubo nodes are to be created, which determines the cluster's capacity and the method of interaction with the nodes.
The Kubo nodes sit on top of the IPFS cluster nodes and provide a way for users to interact with the cluster via HTTP API or IPFS client. This interaction enables users to manage and control the IPFS cluster by creating endpoints that allow various actions to be performed on the nodes.
Once the cluster is set up, users can create endpoints to perform various actions on the cluster nodes. These endpoints can be migrated as necessary, enabling the cluster to be flexible and adaptable to changing requirements.
Challenges we ran into
🧐 At first, the team struggled with ideation, and considered a broad spectrum of potential pathways. There was a struggle to find consensus. We also had little to no experience with IPFS, and no idea how to architect or scope it down. This was overcome with much discussion and research.
Challenges we ran into:
- Developing the ACL and integrating it with the IPFS.
- Starting the local IPFS architecture.
- As we were running the local IPFS server, we faced the CORS issue in the IPFS nodes which prevented us to access from different origins.
- Developing B+ search tree as per our use case of adding multiple values.
- Integration of different components we built.
- Integration with Estuary APIs for using them as the storage engine along with IPFS.
Accomplishments that we're proud of
🙏🏻 We are incredibly proud to achieve a fully functional MVP within 36 hours. Integrating IPFS from zero experience, as well as permission and encryption layers, ensuring everything runs stably, has been a huge accomplishment within the short time we've had.
What we learned
💯 This was a great deep dive into the world of decentralized data storage, IPFS and building permission layers. We also learnt to build synergy as a team, and how to build a strong team together, leveraging each individual's unique strengths.
What's next for ControlDB
🥳 We'd like to change encryption keys over time, reducing vulnerabilities to attacks.
Built With
- b+tree
- caching
- docker
- estuary
- github
- golang
- ipfs
- nextjs
- solidity
- tailwindcss
- typescript










Log in or sign up for Devpost to join the conversation.