-
-
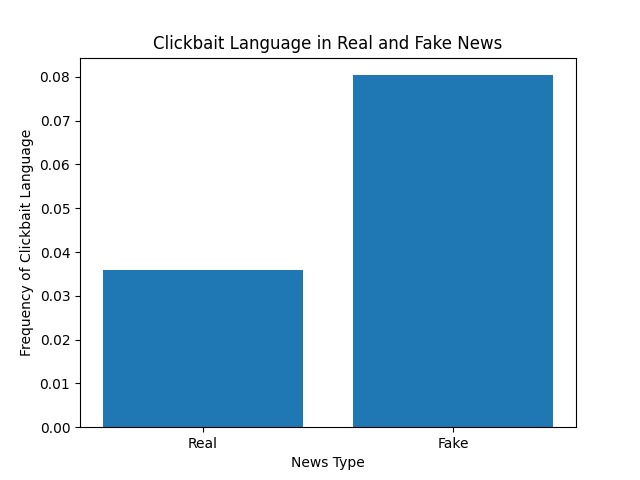
Study of Clickbait and validity
-
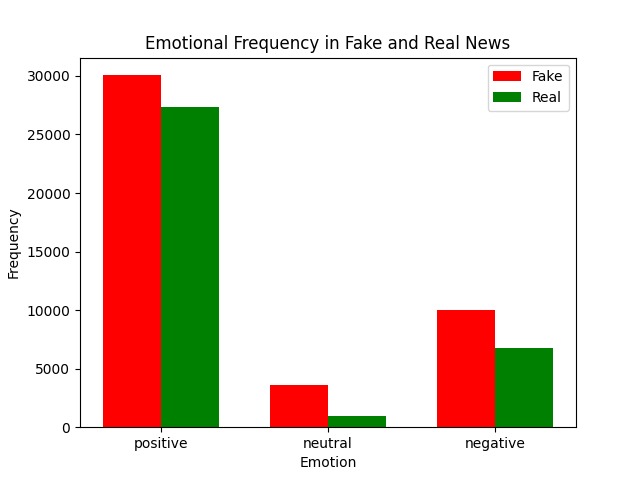
Study of Emotions and validity
-
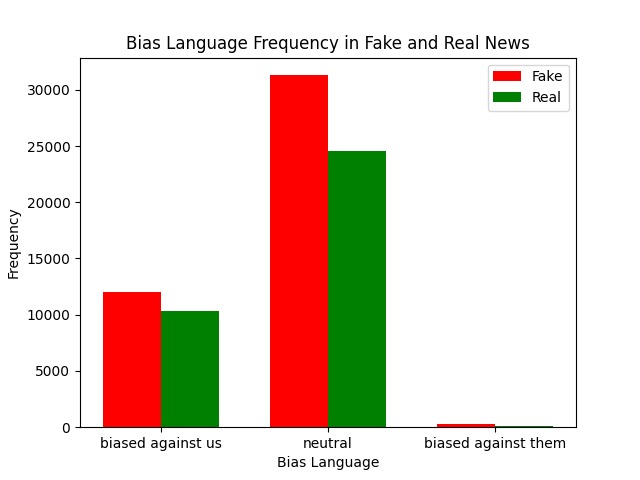
Study of Bias language and validity
-
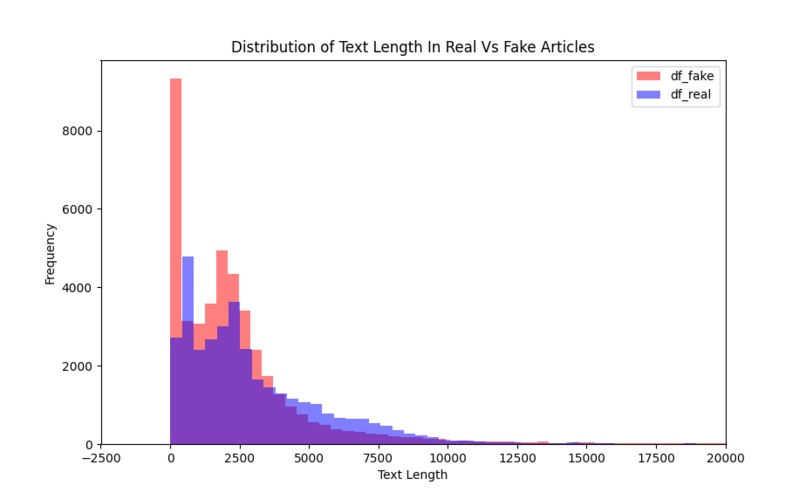
Study of Length and validity
-
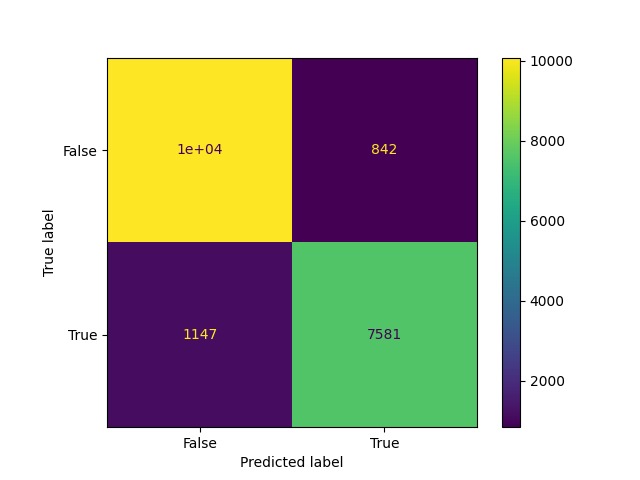
Confusion Matrix Demonstrating Accuracy





Inspiration
As software engineering students, our inspiration for creating a machine learning model to detect fake news comes from the desire to tackle a growing problem in our society. We understand the limitations of human fact-checkers and believe that machine learning can provide a reliable and efficient solution. We are motivated by the potential impact our model could have in promoting accuracy and accountability in news reporting and social media. Our aim is to develop a technical solution that can be applied across various platforms and make a positive difference in combating the spread of fake news.
What it does
During the training process, the models learn to identify patterns in the text data that distinguish between real and fake news articles. The models then use these learned patterns to predict the labels of new news articles that they have not seen before.
When a new news article is input into the models, they analyze its text and use the learned patterns to predict whether it is real or fake. The models output a label that corresponds to either "real" or "fake" based on their analysis of the input article's text.
Overall, this code helps detect fake news by training machine learning models to analyze the text of news articles and determine whether they are real or fake.
How we built it
This fake news detection algorithm is built in six main steps:
- Collect both real and fake news articles data.
- Clean the data and combine it into one dataframe.
- Preprocess the text data by removing stop words and stemming words.
- Convert the preprocessed text data into numerical vectors.
- Train machine learning models using the preprocessed and vectorized data.
- Evaluate the accuracy of the models and determine which performs best for detecting fake news.
This algorithm helps to detect fake news articles by analyzing the text and determining if it is real or fake.
Challenges we ran into
One of the main challenges in developing a model to detect fake news is the lack of a standardized definition for what constitutes "fake news."
Developing a model that can be sustained in the future, because misinformation is constantly changing and therefore unpredictable. We were limited by the dataset.
These are some reasons the model is only a model... so far.
Accomplishments that we're proud of
Our model helps combat misinformation and fake news in online sources.
Developing this model has given us valuable knowledge data analysis machine learning that can be applied to other projects.
Our accurate fake news detection can empower people to be more informed and critical consumers, leading to a more engaged society based on accurate information.
What we learned
As student's, working on a machine learning model to prevent misinformation was a challenging but rewarding experience. Through this project, I learned about the importance of data quality and how it can impact the performance of the model. I also gained an understanding of feature engineering and how selecting and transforming relevant data features can significantly improve the accuracy of the model.
One of the biggest challenges I faced was dealing with the complexity of misinformation. Misinformation can take many forms, and it can be difficult to define and identify. It was important for me to continuously monitor and update the model as new forms of misinformation emerged.
Another valuable aspect of this project was the opportunity to work with a multidisciplinary team. I collaborated with experts in machine learning, data analysis, and the specific domain in question, which provided me with diverse perspectives and skill sets. This not only helped me learn more about the project, but also helped me develop important teamwork and communication skills.
One of the most important things I learned from this project was the importance of transparency and interpretability. As machine learning models are increasingly used to prevent misinformation, it is important to ensure that they are transparent and explainable. This can help build trust in the model and ensure that it is being used appropriately.
Overall, working on a machine learning model to prevent misinformation was an excellent learning experience. It helped me develop a deeper understanding of the complexities involved in using machine learning for real-world applications, and provided me with valuable skills that will be useful in my future studies and career.
What's next for Misinfo-buster
Incorporating new data sources, such as fact-checking websites or government reports, can also improve the model's performance and adaptability. This can help the model stay up-to-date on current events and trends related to misinformation and ensure that it is able to detect new forms of false information as they emerge.
Exploring new algorithms or combinations of existing ones can also improve the model's performance and adaptability. For example, using deep learning techniques, such as convolutional neural networks, can improve the accuracy of the model in detecting subtle patterns and features in text that indicate misinformation.
Building modular components can also improve the model's adaptability. For example, separate components could be built for detecting specific types of misinformation, such as conspiracy theories or propaganda, which can be easily swapped out or modified as needed.
Finally, fine-tuning the hyperparameters of the model can improve its adaptability and optimize it for specific tasks or contexts. For example, adjusting the learning rate or regularization strength can help the model perform better on different types of data or in different environments.

Log in or sign up for Devpost to join the conversation.