-
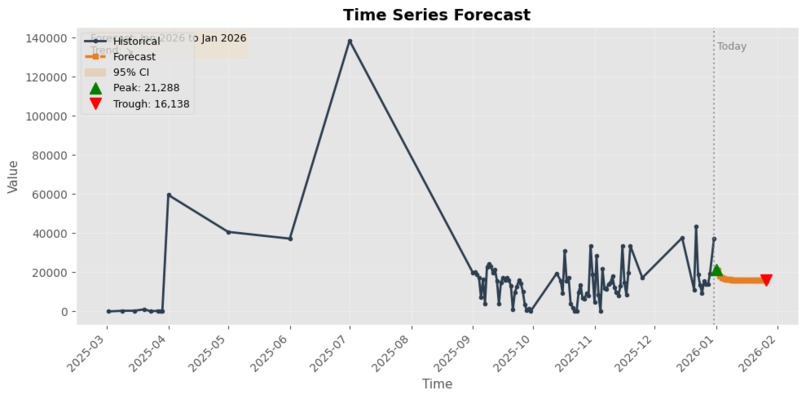
Graph based on Given data
-
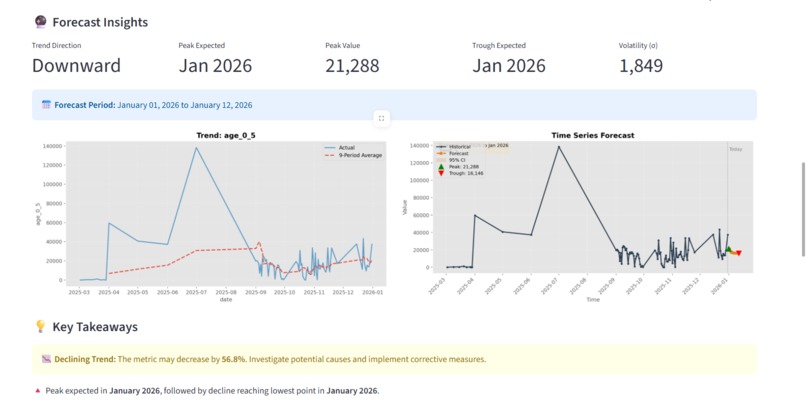
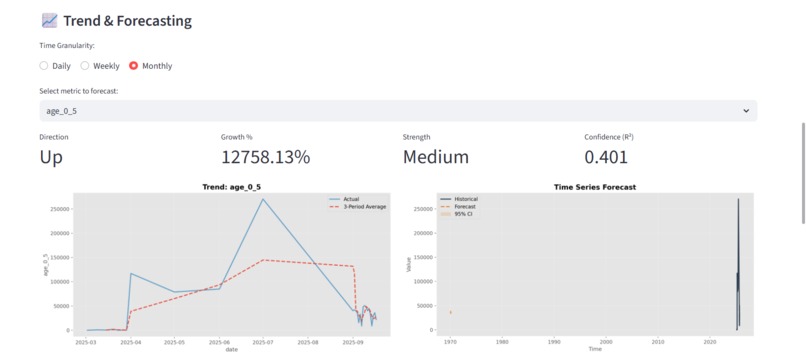
Tread foreseeing
-
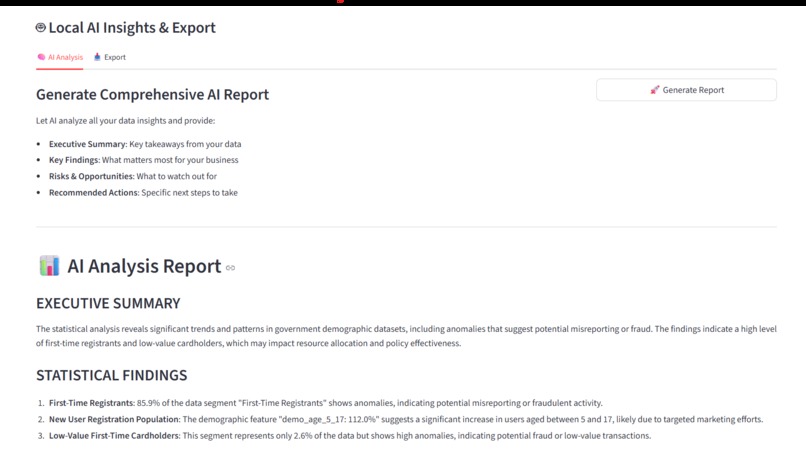
Local Ai expert
-
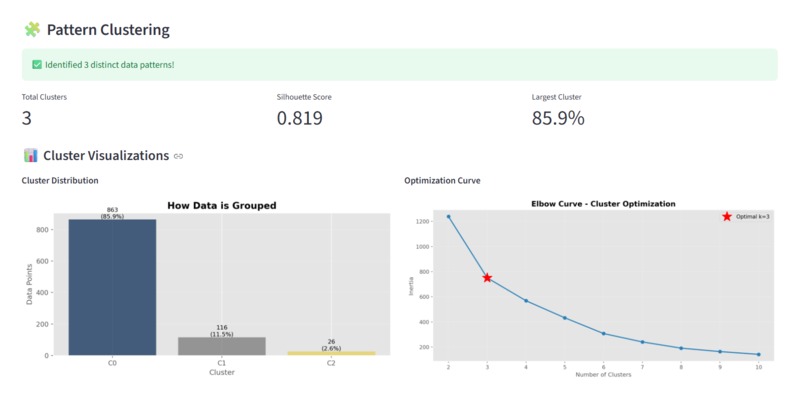
Advance concept for data analysi
-





🏛️ Build Story
Why we started
- We needed local-first analytics that respected data sovereignty and ran fully on CPUs.
- We wanted analysts to get trustworthy insights in minutes without wiring together notebooks, cloud creds, or brittle scripts.
How we built it (milestones)
- Foundation: Stood up
ingestion/loader.pyfor multi-file uploads, then layered validation inutils/data_validator.pyso bad data fails early with human-readable errors. - Schema IQ: Built
schema/analyzer.pyto fingerprint columns, spot dates and numerics, and hand that context to downstream steps. - Decision Engine: Added
decision_engine/rules.pyto auto-suggest the right analysis path (forecasting, anomalies, clustering) based on schema signals. - Models that fit offline: Implemented ARIMA forecasting, Isolation Forest anomalies, and K-Means clustering in
ml_models/, tuned for CPU-only speed and predictable defaults. - Visual Storytelling: Wrapped Plotly charts in Streamlit, emphasizing responsive layouts and downloadability for quick handoffs.
- Local LLM assist: Integrated Ollama in
llm/to turn numbers into narratives while keeping every token on the user's machine.
Principles we kept
- Privacy-first: nothing leaves the box; defaults avoid external calls.
- Fast enough on a laptop: sampling and chunked reads keep 200K+ rows workable.
- Reproducible: single
config.py,.envoptions, and lean requirements. - Observable: structured logs plus focused tests (
tests/verify_backend.py, clustering/validation specs) to catch regressions early.
Built With
- ai
- api
- ollama
- python


Log in or sign up for Devpost to join the conversation.